ГОСТ Р ИСО 3534-1-2019
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Статистические методы
СЛОВАРЬ И УСЛОВНЫЕ ОБОЗНАЧЕНИЯ
Часть 1
Общие статистические термины и термины, используемые в теории вероятностей
Statistical methods. Vocabulary and symbols. Part 1. General statistical terms and terms used in probability
ОКС 01.040.03; 03.120.30
Дата введения 2020-01-01
Предисловие
1 ПОДГОТОВЛЕН Закрытым акционерным обществом "Научно-исследовательский центр контроля и диагностики технических систем" (ЗАО "НИЦ КД") на основе собственного перевода на русский язык англоязычной версии стандарта, указанного в пункте 4
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 125 "Применение статистических методов"
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 5 сентября 2019 г. N 636-ст
4 Настоящий стандарт идентичен международному стандарту ИСО 3534-1:2006* "Статистика. Словарь и условные обозначения. Часть 1. Общие статистические термины и термины, используемые в теории вероятностей" (ISO 3534-1:2006 "Statistics - Vocabulary and symbols - Part 1: General statistical terms and terms used in probability", IDT).
________________
* Доступ к международным и зарубежным документам, упомянутым в тексте, можно получить, обратившись в Службу поддержки пользователей. - .
Международный стандарт разработан Техническим комитетом ISO/TC 69.
Наименование настоящего стандарта изменено относительно наименования указанного международного стандарта для приведения в соответствие с ГОСТ Р 1.5-2012 (пункт 3.5)
5 ВЗАМЕН ГОСТ Р 50779.10-2000 (ИСО 3534-1-93)
Правила применения настоящего стандарта установлены в статье 26 Федерального закона от 29 июня 2015 г. N 162-ФЗ "О стандартизации в Российской Федерации". Информация об изменениях к настоящему стандарту публикуется в ежегодном (по состоянию на 1 января текущего года) информационном указателе "Национальные стандарты", а официальный текст изменений и поправок - в ежемесячном информационном указателе "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ближайшем выпуске ежемесячного информационного указателя "Национальные стандарты". Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет (www.gost.ru)
Введение
В настоящем стандарте использован минимальный уровень математической абстракции, при котором возможно введение последовательных, корректных и лаконичных определений. Термины, представленные в настоящем стандарте, являются основополагающими в теории вероятностей и статистике, вследствие чего они имеют несколько усложненное математическое представление. Работа с другими стандартами по прикладной статистике предполагает обращение к настоящему стандарту для уточнения определений соответствующих терминов, по этой причине некоторые определения представлены менее формально и сопровождены примечаниями и примерами. Данное неформальное представление не заменяет собой формальных определений, но позволяет работать с приведенными терминами и определениями пользователям с различными уровнями подготовки в области теории вероятностей и математической статистики. Примечания и примеры позволяют настоящему стандарту быть более доступным для пользователей.
Корректное и полное определение терминов, используемых в теории вероятностей и математической статистике, важно для разработки и эффективного применения стандартов, содержащих статистические методы. Определения, представленные в настоящем стандарте, являются достаточно точными и имеют необходимый уровень математического представления, что дает возможность разработчикам стандартов на статистические методы избежать неопределенности в представлении информации. Более детальное представление содержания излагаемых концепций и сферы их применения приведено в литературе по теории вероятностей и математической статистике.
В приложениях представлены схемы для каждой группы терминов: 1) общие статистические термины (приложение В) и 2) термины, используемые в теории вероятностей (приложение С). Приведены шесть диаграмм для общих статистических терминов и четыре диаграммы для терминов, связанных с теорией вероятностей. Некоторые термины включены в несколько диаграмм, что обеспечивает связь между представленными концепциями. Приложение D содержит краткое введение в методологию концептуальных диаграмм и их интерпретацию.
Использованные схемы позволяют выявлять взаимосвязи терминов. Они также полезны при переводе терминов на другие языки.
Большая часть терминов и определений, представленных в настоящем стандарте, если не указано иное, дана для одномерного случая без упоминания этого предположения. Это позволяет избежать многократных указаний на размерность в большинстве определений.
Область применения
________________
Разделу не присвоен номер для сохранения идентичности настоящего стандарта.
Настоящий стандарт устанавливает общие статистические термины и термины, используемые в теории вероятностей, которые могут быть использованы при разработке других стандартов.
Приведенные в настоящем стандарте термины подразделены:
a) на общие статистические термины (раздел 1);
b) термины, используемые в теории вероятностей (раздел 2).
Приложение А содержит перечень обозначений и сокращений, используемых в настоящем стандарте.
Термины и определения, представленные в настоящем стандарте, упорядочены в соответствии со схемами, приведенными в приложениях В и С.
1 Общие статистические термины
1.1 (генеральная) совокупность: Множество всех рассматриваемых единиц. | en | population |
fr | population | |
Примечание 1 - Совокупность может состоять из реальных объектов и быть конечной, может состоять из реальных объектов и быть бесконечной или может быть полностью гипотетической. Иногда используют термин "конечная совокупность", особенно в ситуациях, связанных с получением конечных выборок. Подобным образом термин "бесконечная совокупность" используют в случае выборки из континуума. В главе 2 совокупность рассматривается в вероятностном контексте как пространство элементарных событий (2.1). Примечание 2 - Гипотетическая совокупность позволяет делать различные предположения о природе ожидаемых данных. Таким образом, гипотетическая совокупность полезна на стадии статистических исследований, особенно при выборе подходящего объема выборки. Гипотетическая совокупность может состоять из конечного или бесконечного числа элементов. Ее использование особенно полезно при работе с аналитическими статистиками в статистических исследованиях. Примечание 3 - Область применения исследований определяет свойства совокупности. Например, если для демографического или медицинского исследования выбраны три населенных пункта, то генеральная совокупность состоит из жителей данных конкретных населенных пунктов. Однако если эти три населенных пункта выбраны случайным образом среди всех населенных пунктов заданного региона, то совокупность состоит из всех жителей данного региона. | ||
1.2 выборочная единица: Одна из конкретных единиц, из которых состоит генеральная совокупность (1.1). | en | sampling unit |
Примечание - В зависимости от обстоятельств единицей может быть человек, семья, учебное заведение, административное подразделение и т.д. | fr |
|
1.3 выборка: Подмножество генеральной совокупности (1.1), состоящее из одной выборочной единицы (1.2) или более. | en | sample |
Примечание 1 - В зависимости от рассматриваемой генеральной совокупности выборочными единицами могут быть предметы, числовые значения или даже абстрактные объекты. Примечание 2 - Определение выборки, приведенное в ИСО 3534-2, включает пример схемы отбора выборки, которая необходима при отборе случайной выборки из конечной совокупности. | fr |
|
1.4 наблюдаемое значение: Значение исследуемой характеристики, полученное в результате единичного наблюдения. | en | observed value |
Примечание 1 - Часто используемые синонимы данного понятия - это "реализация" и "данная величина". Множественное число от понятия "данная величина" - данные. Примечание 2 - Определение не указывает на происхождение или способ получения данного значения. Значение может представлять только одну реализацию случайной величины (2.10), но это не является общей ситуацией. Последующему статистическому анализу может быть подвергнута одна из нескольких реализаций случайной величины. Несмотря на то что соответствующие выводы требуют некоторого статистического обоснования, ничто не препятствует вычислительной обработке или графическому представлению наблюдаемых значений. Только при появлении таких вопросов, как определение вероятности появления конкретного набора реализаций случайной величины, применение статистических методов обработки данных становится уместным и важным. Предварительный этап изучения наблюдаемых значений, как правило, относят к анализу данных. | fr | valeur |
1.5 описательная статистика: Краткое представление наблюдаемых значений (1.4) в графическом, численном или ином виде. | en | descriptive statistics |
Пример 1 - Численные сводки включают выборочное среднее (1.15), выборочный размах (1.10), выборочное стандартное отклонение (1.17) и т.д. | fr | statistique descriptive |
1.6 случайная выборка: Выборка (1.3), отобранная методом случайного отбора | en | random sample |
________________
Примечание 1 - Данное определение имеет меньше ограничений, чем приведенное в ИСО 3534-2, которое допускает наличие бесконечной генеральной совокупности. Примечание 2 - Когда выборка из Примечание 3 - Для выборочных планов данных опроса, составляемых для конечного пространства элементарных событий, случайная выборка может быть отобрана с помощью различных планов отбора выборки, таких как планы отбора стратифицированной случайной выборки, систематической случайной выборки, групповой выборки, выборки с вероятностью отбора пропорционально величине вспомогательной переменной, а также с помощью различных других планов. Примечание 4 - Как правило, определение относят к фактическим наблюдаемым значениям (1.4). Эти наблюдаемые значения считают реализациями случайных величин (2.10), и каждое наблюдаемое значение соответствует одной случайной величине. Если оценки (1.12), статистические критерии для проверки статистических гипотез (1.48) и доверительные интервалы (1.28) получены на основе случайной выборки, определение дополняют ссылкой на случайные величины, возникающие в большей степени на основе абстрактных объектов выборки, чем на основе фактически наблюдаемых значений этих случайных величин. Примечание 5 - Случайные выборки из бесконечной генеральной совокупности часто генерируют путем многократного отбора из пространства элементарных событий таким образом, что выборка состоит из независимых одинаково распределенных случайных величин в соответствии с интерпретацией данного определения, приведенной в примечании 4. | fr |
|
1.7 простая случайная выборка: Случайная выборка (1.6) из конечной генеральной совокупности, такая, что всем подмножествам заданного объема соответствует одна и та же вероятность быть отобранными. | en | simple random sample |
Примечание - Данное определение гармонизировано с определением, приведенным в ИСО 3534-2, хотя и имеет немного отличную формулировку. | fr |
|
1.8 статистика: Полностью определенная функция случайных величин (2.10). | en | statistic |
fr | statistique | |
Примечание 1 - Для случайной выборки (1.6), понимаемой в смысле примечания 4 к 1.6, статистика представляет собой функцию случайных величин. Примечание 2 - В соответствии с примечанием 1, если Примечание 3 - Приведенное определение является формальным и соответствует трактовке, используемой в математической статистике. В приложениях многочисленные статистические данные, в частности статистики, могут иметь отношение к различным областям технических знаний, включающим анализ действий, представленный в международных стандартах ISO/TC 69. | ||
1.9 порядковая статистика: Статистика (1.8), определяемая порядковым номером случайной величины (2.10) в ряду случайных величин, расположенных в неубывающем порядке. | en | order statistic |
Примечание 1 - Пусть наблюдаемые значения (1.4), составляющие случайную выборку (1.6), образующие множество Примечание 2 - На практике определение порядковых статистик для набора данных сводится к сортировке данных, как формально описано в примечании 1. Отсортированные данные применяют для определения полезных сводных статистик, как представлено в нескольких следующих определениях. Примечание 3 - Порядковая статистика представляет собой выборочное значение, соответствующее его позиции в последовательности данных после их ранжирования в неубывающем порядке. Как показано в примере, легче понять сортировку выборочных значений (реализаций случайных величин), чем сортировку ненаблюдаемых случайных величин. Тем не менее можно представлять случайные величины из случайной выборки (1.6), упорядоченной в неубывающем порядке. Например, максимальное значение набора из Примечание 4 - Отдельная порядковая статистика представляет собой полностью заданную функцию случайной величины. Эта функция является идентификатором положения или ранга случайной величины в отсортированном наборе случайных величин. Примечание 5 - Потенциальную проблему представляет ранжирование совпадающих значений, особенно для дискретных случайных величин и для значений, полученных с низкой точностью. Формулировка "неубывающий порядок" точнее, чем "возрастающий порядок", при учете всех тонкостей процесса ранжирования данных. Необходимо акцентировать внимание на том, что совпадающие значения сохраняют при обработке данных, а не заменяют одним значением. В примере, представленном выше, две реализации, "6" и "6", представляют собой совпадающие значения. Примечание 6 - Упорядочивание выполняют на основе фактических значений, а не на основе абсолютных значений случайных величин. Примечание 7 - Полный набор порядковых статистик составляет случайную величину размерности Примечание 8 - Компоненты порядковой статистики также рассматривают как порядковые статистики, но снабженные спецификатором, указывающим их номер в упорядоченной последовательности значений в выборке. Примечание 9 - Минимальное и максимальное значения, а также при нечетном объеме выборки выборочная медиана (1.13) представляют собой частные случаи порядковых статистик. Например, для выборки объема 11 единиц, | en | statistique d’ordre |
1.10 выборочный размах: Разность между значениями наибольшей и наименьшей порядковых статистик (1.9). | en | sample range |
Пример - Для примера, рассмотренного в 1.9, выборочный размах, полученный на основе наблюдений, равен 19-6=13. Примечание - В статистическом управлении процессами выборочный размах часто используют для отслеживания дисперсии процесса, особенно при относительно небольших объемах выборки. | fr |
|
1.11 середина размаха: Среднее арифметическое (1.15) наименьшей и наибольшей порядковых статистик (1.9). | en | mid-range |
Пример - В примере, рассмотренном в 1.9, середина размаха на основе наблюдений равна (6+19)/2=12,5. Примечание - Середина размаха дает быструю и простую оценку середины небольших наборов данных. | fr | milieu de |
1.12 оценка: | en | estimator |
fr | estimateur | |
Примечание 1 - Оценкой может быть выборочное среднее (1.15) при определении оценки математического ожидания (2.35) генеральной совокупности, которое может быть обозначено Примечание 2 - При определении оценок характеристик генеральной совокупности [например, моды (2.27) для одномерного распределения (2.16)] подходящей оценкой может быть функция оценки(ок) параметра распределения или сложная функция случайной выборки (1.6). Примечание 3 - Термин "оценка" использован в широком смысле. Он включает в себя как точечную, так и интервальную оценки параметра, которые могут быть использованы для прогнозирования (иногда их рассматривают как прогностические факторы). Оценка также может включать в себя такие функции, как ядерные оценки и другие специальные статистики. Дополнительная информация приведена в примечаниях к 1.36. | ||
1.13 выборочная медиана: Значение | en | sample median |
Примечание 1 - Для случайной выборки (1.6) объема Примечание 2 - Упорядочивание случайных величин, для которых наблюдения отсутствуют, может казаться невозможным. Тем не менее в рамках работы с порядковыми статистиками данный анализ может быть произведен. На практике получают наблюдаемые значения и, сортируя эти значения, реализации порядковых статистик. Данные реализации могут быть проинтерпретированы исходя из структуры порядковых статистик случайной выборки. Примечание 3 - Выборочная медиана является оценкой середины распределения, с каждой стороны от которой лежит половина выборки. Примечание 4 - На практике выборочная медиана полезна как оценка, не чувствительная к наличию в выборке сильно удаленных крайних значений. Например, в обзорах в качестве "среднего дохода" и "средней цены на жилье" часто указывает медиану. | fr |
|
1.14 выборочный момент порядка | en | sample moment of order k | ||||||||||
Примечание 1 - Для случайной выборки объема
Примечание 2 - Кроме того, данное понятие можно характеризовать как начальный выборочный момент порядка Примечание 3 - Выборочный момент порядка 1, представленный в следующем определении, является выборочным средним (1.15). Примечание 4 - Хотя определение дано для произвольного Примечание 5 - Использование буквы " | fr | moment | ||||||||||
1.15 выборочное среднее; среднее арифметическое: Сумма случайных величин (2.10) случайной выборки (1.6), деленная на число слагаемых в этой сумме. | en | sample mean (average, arithmetic mean) | ||||||||||
Пример - В примере, приведенном в 1.9, значение выборочного среднего составляет 9,7, т.к. сумма наблюдаемых значений равна 97, а объем выборки равен 10. Примечание 1 - Рассматриваемое как статистика выборочное среднее представляет собой функцию случайных величин из случайной выборки в смысле, указанном в примечании 3 к 1.8. Необходимо отличать функцию от численного значения выборочного среднего, вычисленного на основе наблюдаемых значений (1.4) случайной выборки. Примечание 2 - Рассматриваемое как статистика выборочное среднее часто используют как оценку математического ожидания (2.35) генеральной совокупности. Часто используемым синонимом является арифметическое среднее. Примечание 3 - Для случайной выборки объема
Примечание 4 - Выборочное среднее является моментом первого порядка. Примечание 5 - Для выборки объема, равного двум, выборочное среднее, выборочная медиана (1.13) и середина размаха (1.11) совпадают. | fr | moyenne | ||||||||||
1.16 выборочная дисперсия; | en | sample variance | ||||||||||
Пример - Для примера, приведенного в 1.9, значение выборочной дисперсии составляет 17,57. Сумма квадратов отклонений от выборочного среднего равна 158,10; данная сумма поделена на число 9, что составляет объем выборки 10 минус один. Примечание 1 - Рассматриваемая как статистика (1.8) выборочная дисперсия Примечание 2 - Для случайной выборки объема
Примечание 3 - Выборочная дисперсия - это статистика, которая "почти" совпадает со средним арифметическим квадратных отклонений случайных величин (2.10) от их выборочного среднего (так как сумму делят не на Примечание 4 - Величину Примечание 5 - Выборочная дисперсия является вторым выборочным моментом случайных величин нормализованной выборки (1.19). | fr | variance | ||||||||||
1.17 выборочное стандартное отклонение; | en | sample standard deviation | ||||||||||
Пример - Для примера, приведенного в 1.9, значение выборочного стандартного отклонения составляет 4,192, т.к. полученная выборочная дисперсия составляет 17,57. Примечание 1 - На практике выборочное стандартное отклонение используют для определения оценки стандартного отклонения (2.37). Примечание 2 - Выборочное стандартное отклонение является мерой разброса распределения (2.11). | fr |
| ||||||||||
1.18 выборочный коэффициент вариации: Выборочное стандартное отклонение (1.17), деленное на выборочное среднее (1.15). | en | sample coefficient of variation | ||||||||||
Примечание - Как и в случае коэффициента вариации (2.38), полезность этой статистики ограничена генеральными совокупностями, содержащими положительные значения. Величину выборочного коэффициента вариации обычно представляют в процентах. На практике выборочный коэффициент вариации, как правило, применяют, когда вариация возрастает пропорционально среднему. | fr | coefficient de variation | ||||||||||
1.19 стандартизованная выборочная случайная величина: Разность случайной величины (2.10) и ее выборочного среднего (1.15), деленная на выборочное стандартное отклонение (1.17). | en | standardized sample random variable | ||||||||||
Пример - Для примера, приведенного в 1.9, полученное выборочное среднее составляет 9,7, а полученное выборочное стандартное отклонение - 4,192; таким образом, полученные значения стандартизованной выборки составляют: -0,17; 0,79; -0,64; -0,88; 0,79; -0,64; 2,22; -0,88; 0,07; -0,64. Примечание 1 - Стандартизованную выборочную случайную величину следует отличать от ее теоретического аналога - стандартизованной случайной величины (2.33). Целью стандартизации случайной величины является ее преобразование в случайную величину с нулевым математическим ожиданием и стандартным отклонением, равным единице; данное преобразование проводят для простоты интерпретации и сравнения данных. Примечание 2 - Стандартизованные наблюдаемые значения имеют нулевое наблюдаемое среднее и наблюдаемое стандартное отклонение, равное единице. | fr | variable | ||||||||||
1.20 выборочный коэффициент асимметрии: Среднее арифметическое стандартизованных выборочных случайных величин (1.19) случайной выборки (1.6) в третьей степени. | en | sample coefficient of skewness | ||||||||||
Пример - Для примера, приведенного в 1.9, получен выборочный коэффициент асимметрии 0,97188. Для такого объема выборки (n=10) выборочный коэффициент асимметрии имеет высокую изменчивость, поэтому требует осторожности при использовании. Применение альтернативной формулы, представленной в примечании 1, дает значение 1,34983. Примечание 1 - Определению соответствует следующая формула:
Некоторые программы статистической обработки данных с целью корректировки смещения (1.33) используют для вычисления выборочного коэффициента асимметрии следующую формулу:
где При больших объемах выборок разность значений этих двух оценок пренебрежимо мала. Отношение несмещенной оценки к смещенной для Примечание 2 - Асимметрия характеризует симметричность распределения. Близкие к нулю значения данной статистики указывают на то, что рассматриваемое распределение очень близко к симметричному, тогда как ненулевые значения соответствуют тому, что, вероятно, существуют случайные всплески значений по одну сторону от центра распределения. Асимметричность данных также отражает различие в значениях выборочного среднего (1.15) и выборочной медианы (1.13). Положительная асимметрия (правосторонняя асимметрия) данных указывает на возможное наличие нескольких экстремально больших значений. Подобным образом отрицательная асимметрия указывает на возможное наличие нескольких экстремально малых значений. Примечание 3 - Выборочный коэффициент асимметрии является третьим выборочным моментом стандартизованной выборочной случайной величины (1.19). | fr | coefficient | ||||||||||
1.21 выборочный коэффициент эксцесса; выборочный эксцесс: Среднее арифметическое стандартизованных выборочных случайных величин (1.19) случайной выборки (1.6). | en | sample coefficient of kurtosis | ||||||||||
Пример - Для примера, приведенного в 1.9, получен выборочный коэффициент эксцесса 2,67419. Для выборки такого же объема, как и в данном примере, выборочный коэффициент эксцесса (n=10) имеет высокую изменчивость, поэтому при использовании требуется осторожность. Программные пакеты статистической обработки позволяют варьировать настройки при вычислении выборочного коэффициента эксцесса (см. примечание 3 к 2.40). При использовании альтернативной формулы, приведенной в примечании 1, вычисленное значение составляет 0,43605. Два полученных значения, 2,67419 и 0,43605, непосредственно не сопоставимы. Для их сравнения рассматривают разность 2,67419-3 (3 вычитают для сопоставления с эксцессом нормального распределения), которая равна -0,32581, эту величину можно сравнивать с 0,43605. Примечание 1 - Определению соответствует следующая формула:
В некоторых программных пакетах статистической обработки данных с целью корректировки смещения (1.33) и определения отклонения от эксцесса нормального распределения выборочный коэффициент эксцесса вычисляют по следующей формуле:
где Второй член формулы при достаточно больших Примечание 2 - Эксцесс характеризует тяжесть хвостов унимодального распределения. Для нормального распределения (2.50) с учетом вариабельности выборки выборочный коэффициент эксцесса приблизительно равен 3. На практике эксцесс нормального распределения представляет собой эталонное или базовое значение. Распределения (2.11), у которых значение эксцесса менее 3, имеют более легкие хвосты, чем хвосты нормального распределения; распределения (2.11), у которых значение эксцесса более 3, имеют более тяжелые хвосты, чем у нормального распределения. Примечание 3 - Для наблюдаемых значений эксцесса, значительно превосходящих 3, существует вероятность того, что хвосты рассматриваемого распределения значимо тяжелее, чем хвосты нормального распределения. Выборка может содержать наблюдения из другого источника или ошибочные записи. Примечание 4 - Выборочный коэффициент эксцесса является 4-м выборочным моментом стандартизованных выборочных случайных величин. | fr | coefficient d’aplatissement | ||||||||||
1.22 выборочная ковариация; | en | sample covariance | ||||||||||
| fr | covariance | ||||||||||
i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
x | 38 | 41 | 24 | 60 | 41 | 51 | 58 | 50 | 65 | 33 | ||
y | 73 | 74 | 43 | 107 | 65 | 73 | 99 | 72 | 100 | 48 | ||
z | 34 | 31 | 40 | 28 | 35 | 28 | 32 | 27 | 27 | 31 | ||
Выборочное среднее для X составляет 46,1, а для Y составляет 75,4. Соответствующая выборочная ковариация равна: Примечание 1 - Рассматриваемая как статистика (1.8) выборочная ковариация представляет собой функцию пар случайных величин Примечание 2 - В соответствии с определением выборочная ковариация имеет вид:
Примечание 3 - Деление на Примечание 4 - В примере, данные для которого представлены в таблице 1, приведены три переменные несмотря на то, что в определении говорится о парах переменных. На практике стандартными являются ситуации, в которых присутствует несколько переменных. | ||||||||||||
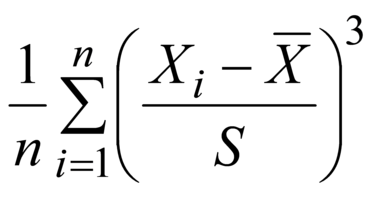 .
.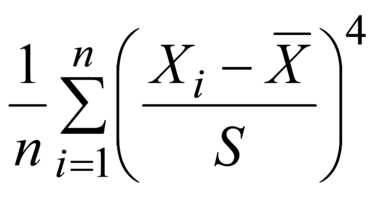 .
.1.23 выборочный коэффициент корреляции; | en | sample correlation coefficient |
Пример 1 - В примере 1, приведенном в 1.22, стандартное отклонение составляет 12,948 для X и 21,329 для Y. Поэтому полученный выборочный коэффициент корреляции (для X и Y) равен: 257,178/(12,948·21,329)=0,9312.
-54,356/(21,329·4,165)=-0,612. Примечание 1 - В соответствии с определением выборочный коэффициент корреляции имеет следующий вид:
Данное выражение представляет собой отношение выборочной ковариации к квадратному корню из произведения стандартных отклонений. Иногда символ Примечание 2 - Наблюдаемый выборочный коэффициент корреляции может принимать значения в промежутке [-1, 1], при этом значения, близкие к 1, указывают на сильную положительную корреляцию, а значения, близкие к -1, - на сильную отрицательную корреляцию. Выборочный коэффициент корреляции показывает степень близости к линейной зависимости между переменными со значениями -1 или 1 в случае линейной зависимости, значения, близкие к 0, указывают на слабую линейную зависимость. | fr | coefficient de |
1.24 стандартная ошибка; | en | standard error |
fr | erreur type | |
Пример - Если выборочное среднее (1.15) является оценкой математического ожидания (2.35) генеральной совокупности и Примечание 1 - Практически стандартная ошибка является естественной оценкой стандартного отклонения оценки. Примечание 2 - Не существует (целесообразного) понятия "нестандартная ошибка". Стандартную ошибку можно рассматривать как сокращение выражения "стандартное отклонение оценки". На практике под стандартной ошибкой неявно подразумевают стандартное отклонение выборочного среднего. Для стандартной ошибки выборочного среднего применяют обозначение | ||
1.25 интервальная оценка: Интервал, ограниченный верхней и нижней границами статистики (1.8). | en | nterval* estimator |
________________ * Текст документа соответствует оригиналу. - . | ||
Примечание 1 - Одной из граничных точек интервала могут быть Примечание 2 - Интервальная оценка может быть представлена при определении оценки (1.36) параметра (2.9). Предполагается, что интервальная оценка накрывает значение параметра в установленной доле случаев в условиях многократного повторения отбора выборки или в ином вероятностном смысле. Примечание 3 - Три часто используемых вида интервальных оценок включают доверительные интервалы (1.28) для параметра, предикционные интервалы (1.30) для будущих наблюдений и статистические толерантные интервалы (1.26) на долю распределения (2.11). | fr | estimateur par intervalle |
1.26 толерантный интервал: Интервал, определяемый по случайной выборке (1.6) таким образом, что с заданным уровнем доверия он накрывает, по меньшей мере, установленную долю генеральной совокупности (1.1). | en | statistical tolerance interval |
Примечание - Уровнем доверия в данном случае является доля интервалов, построенных таким образом, что включают, по крайней мере, заданную долю выборки при многократном повторении процедуры. | fr | intervalle statistique de dispersion |
1.27 толерантная граница: Статистика (1.8), представляющая собой конечную точку толерантного интервала (1.26). | en | statistical tolerance limit |
Примечание - Толерантные интервалы могут быть: - односторонними (когда одна из границ является фиксированной естественной границей случайной величины); в этом случае интервал имеет либо верхнюю, либо нижнюю статистическую толерантную границу; - двусторонними, когда интервал имеет обе границы. Естественная граница случайной величины может представлять собой предельное значение односторонней границы. | fr | limite statistique de dispersion |
1.28 доверительный интервал: Интервальная оценка (1.25) ( | en | confidence interval |
Примечание 1 - Уровень доверия отражает долю случаев, когда доверительный интервал накрывает истинное значение параметра для длинной серии повторяемых случайных выборок (1.6) при одинаковых условиях. Доверительный интервал не отражает вероятность (2.5) того, что полученный по наблюдениям доверительный интервал содержит истинное значение параметра (интервал может как накрывать, так и не накрывать истинное значение). Примечание 2 - По отношению к доверительному интервалу используют показатель | fr | intervalle de confiance |
1.29 односторонний доверительный интервал: Доверительный интервал (1.28), одна из конечных точек которого равна | en | one-sided confidence interval |
Примечание 1 - Определение 1.28 применимо и в том случае, когда значение Примечание 2 - Односторонние доверительные интервалы встречаются в ситуациях, когда исследуемый параметр имеет натуральную естественную границу значений, например равную нулю. Для распределения Пуассона (2.47), используемого при моделировании поступления жалоб потребителей, ноль является нижней границей. Другой пример - доверительный интервал для вероятности безотказной работы электронного компонента в виде (0,98;1), где единица - естественная верхняя граница значений вероятности. | fr | intervalle de confiance |
1.30 предикционный интервал: Диапазон значений переменной случайной выборки (1.6), отобранной из непрерывной генеральной совокупности, для которого с установленным уровнем доверия можно утверждать, что не менее заданного числа значений будущей случайной выборки из той же самой генеральной совокупности (1.1) попадет в данный диапазон. | en | prediction interval |
Примечание 2 - Как правило, исследуют единственное будущее наблюдение, получаемое в тех же условиях, что и наблюдения, используемые для построения предикционного интервала. На практике предикционные интервалы применяют также в регрессионном анализе, в котором предикционный интервал строят для спектра независимых значений. | fr | intervalle de |
1.31 значение оценки: Наблюдаемое значение (1.4) оценки (1.12). | en | estimate |
Примечание - Значение оценки представляет собой численное значение, полученное на основе наблюдаемых значений. По отношению к определению оценки (1.36) параметра (2.9) гипотетического распределения вероятностей (2.11) оценка связана со статистикой (1.8), предназначенной для определения оценки параметра, при этом значение оценки получают на основании наблюдаемых значений. Иногда после слова "значение" употребляют прилагательное "точечной", чтобы подчеркнуть, что получено только одно значение (значение точечной оценки), а не интервал значений. Подобным образом прилагательное "интервальной" употребляют перед словом "оценки" в том случае, когда определяют интервал значений. | fr | estimation |
1.32 ошибка оценивания: Разность значения оценки (1.31) и оцениваемого параметра (2.9), характеризующего свойство генеральной совокупности. | en | error of estimation |
Примечание 1 - Свойство генеральной совокупности может быть функцией параметра или параметров или другой величины, связанной с распределением вероятностей (2.11). Примечание 2 - Ошибка может включать составляющие, связанные с отбором выборки, неопределенностью результатов измерений, округлением результатов вычислений и др. По сути ошибка оценивания характеризует достоверность результатов. Определение основных составляющих ошибки оценивания является важным для повышения качества обработки данных. | fr | erreur d’estimation |
1.33 смещение: Математическое ожидание (2.12) ошибки оценивания (1.32). | en | bias |
Примечание 1 - Данное определение отличается от приведенного в [2] (3.3.2) и [4] (5.25, 5.28). Смещение рассмотрено в общем смысле, как указано в примечании 1 к 1.34. Примечание 2 - На практике наличие смещения может привести к нежелательным последствиям. Например, заниженная оценка прочности материала, вызванная смещением, может стать причиной неожиданных отказов устройства. | fr | biais |
1.34 несмещенная оценка: Оценка (1.12), смещение (1.33) которой равно нулю. | en | unbiased estimator |
Пример 1 - Для случайной выборки (1.36) n независимых случайных величин (2.10), подчиненных одному и тому же нормальному распределению (2.50) с математическим ожиданием (2.35) Примечание - Несмещенные оценки предпочтительны, т.к. в среднем их значения корректны. Данные оценки являются начальной точкой поиска "оптимальных" оценок параметров генеральной совокупности. Приведенное определение имеет статистический характер. В повседневной практике исследователи стараются избегать внесения смещения в исследование, например путем обеспечения репрезентативности случайной выборки по отношению к рассматриваемой генеральной совокупности. | fr | estimateur sans biais |
1.35 оценка максимального правдоподобия: Оценка (1.12), приписывающая параметру (2.9) значение, при котором функция правдоподобия (1.38) достигает максимального значения или является его приближением. | en | maximum likelihood estimator |
fr | estimateur du | |
Примечание 1 - Оценка максимального правдоподобия - общепринятый подход определения значений оценок параметров распределения в том случае, когда установлен вид распределения (2.11), например нормальное распределение (2.50), гамма-распределение (2.56), распределение Вейбулла (2.63) и т.д. Эти оценки имеют желаемые статистические свойства (например, инвариантность при монотонном преобразовании) и во многих ситуациях обеспечивают метод определения оценки. Когда оценка максимального правдоподобия является смещенной, иногда возможна простая коррекция смещения (1.33). Как упомянуто в примере 2 к 1.34, оценка максимального правдоподобия для дисперсии (2.36) является смещенной, однако она может быть скорректирована путем использования знаменателя Примечание 2 - Английскую аббревиатуру MLE, как правило, используют как для обозначения оценки максимального правдоподобия (англ. "maximum likelihood estimator"), так и для способа получения оценки максимального правдоподобия (англ. "maximum likelihood estimation"), при этом выбор соответствующего варианта зависит от контекста. | maximum de vraisemblance | |
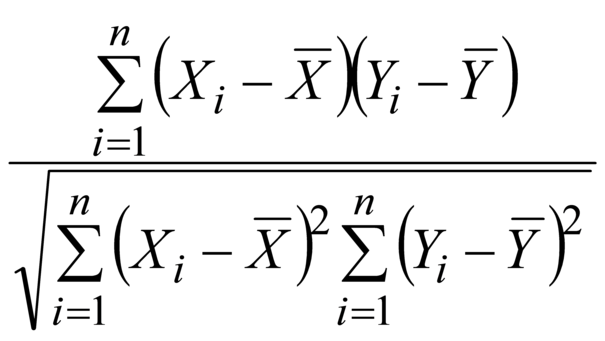 .
.1.36 определение оценки: Процедура, с помощью которой получают статистическое представление генеральной совокупности (1.1) на основе случайной выборки (1.6), полученной из данной генеральной совокупности. | en | estimation |
Примечание 1 - В частности, процедура определения значения оценки (1.31) на основе выражения для оценки (1.12) относится к определению оценки. Примечание 2 - Определение оценки следует понимать в широком смысле, включая определение точечных оценок, интервальных оценок или оценок свойств генеральной совокупности. Примечание 3 - Часто статистическое представление генеральных совокупностей связано с определением оценки параметра (2.9) или параметров или функции параметров предполагаемой модели. В более общем виде представление генеральной совокупности может быть менее конкретным, например в случае статистик, относящихся к воздействию природных катастроф (несчастные случаи, травмы, гибель людей, сельскохозяйственные потери и т.п.). Примечание 4 - Рассмотрение описательных статистик (1.5) может показать, что предполагаемая модель дает неадекватное представление данных, что может быть выявлено путем применения критериев согласия используемой модели полученным данным. В таких случаях могут быть рассмотрены другие модели, и процесс определения оценки может быть продолжен. | fr | estimation ( |
1.37 определение оценки максимального правдоподобия: Определение оценки (1.36), в результате которого получают оценку максимального правдоподобия (1.35). | en | maximum likelihood estimation |
Примечание 1 - Для нормального распределения (2.50) выборочное среднее (1.15) является оценкой максимального правдоподобия (1.35) параметра (2.9) Примечание 2 - Оценку максимального правдоподобия иногда используют для описания отклонения оценки (1.12) от функции правдоподобия. Примечание 3 - В некоторых случаях определение оценки максимального правдоподобия математически может представлять собой решение одного уравнения, однако имеют место ситуации, в которых получение оценки максимального правдоподобия требует итеративного решения нескольких уравнений. Примечание 4 - Английскую аббревиатуру MLE, как правило, используют как для обозначения оценки максимального правдоподобия (англ. "maximum likelihood estimator"), так и для обозначения определения оценки максимального правдоподобия (англ. "maximum likelihood estimation"), при этом выбор соответствующего варианта зависит от контекста. | fr | estimation du maximum de vraisemblance |
1.38 функция правдоподобия: Функция плотности распределения (2.26), вычисляемая на основе наблюдаемых значений (1.4) и рассматриваемая как функция параметров (2.9) семейства распределений (2.8). | en | likelihood function |
| fr | fonction de vraisemblance |
1.39 функция правдоподобия профиля: Функция правдоподобия (1.38), рассматриваемая как функция одного неизвестного параметра (2.9), если всем остальным параметрам присвоены значения, максимизирующие функцию правдоподобия. | en | profile likelihood function |
fr | fonction de vraisemblance partielle | |
1.40 гипотеза | en | hypothesis |
Примечание - Как правило, утверждение относительно генеральной совокупности связано с одним или несколькими параметрами (2.9) семейства распределений (2.8) или с семейством распределений. | fr |
|
1.41 нулевая гипотеза | en | null hypothesis |
Пример 1 - Для случайной выборки (1.6) независимых случайных величин (2.10) из одного и того же нормального распределения (2.50) при неизвестных математическом ожидании (2.35) и стандартном отклонении (2.37) нулевая гипотеза может состоять в том, что математическое ожидание Примечание 1 - Очевидно, что нулевая гипотеза может включать подмножество множества возможных распределений вероятности. Примечание 2 - Данное определение не может быть рассмотрено изолированно от определений альтернативной гипотезы (1.42) и статистического критерия (1.48), т.к. корректное применение процедур поверки гипотез требует наличия всех составляющих. Примечание 3 - На практике нулевую гипотезу никогда не доказывают; скорее, полученная в рассматриваемой ситуации оценка может не давать оснований для отклонения нулевой гипотезы. Примечание 4 - То обстоятельство, что нулевая гипотеза не отклонена, не является доказательством ее справедливости, а лишь указывает на то, что достаточные основания оспаривать ее отсутствуют. В данном случае либо нулевая гипотеза (или близкое ее приближение) является истинной, либо объем выборки недостаточен для обнаружения отклонений от нее. Примечание 5 - В некоторых ситуациях первоначально интерес направлен на нулевую гипотезу, однако затем предметом интереса могут стать отклонения от нулевой гипотезы. Надлежащее внимание к объему выборки и мощности обнаружения характерного отклонения или альтернативы может привести к построению процедуры критерия для соответствующей оценки нулевой гипотезы. Примечание 6 - Принятие альтернативной гипотезы в противоположность принятию нулевой гипотезы является положительным результатом в том смысле, что оно поддерживает рассматриваемую гипотезу. Отклонение нулевой гипотезы в пользу альтернативной представляет собой более однозначный результат, чем невозможность отклонить нулевую гипотезу в данном случае. Примечание 7 - Нулевая гипотеза служит основанием для построения соответствующей статистики критерия (1.52), используемой при проверке нулевой гипотезы. Примечание 8 - Нулевую гипотезу часто обозначают Примечание 9 - Набор параметров, задающих нулевую гипотезу, по возможности выбирают таким образом, чтобы они были несовместимыми с исследуемой гипотезой (см. примечание 2 к 1.48 и пример, приведенный в 1.49). | fr |
|
1.42 альтернативная гипотеза | en | alternative hypothesis |
Пример 1 - Альтернативная гипотеза для нулевой гипотезы, представленной в примере 1 к 1.41, состоит в том, что математическое ожидание (2.35) превосходит заданное значение, что записывают в следующем виде: Примечание 1 - Альтернативная гипотеза является дополнением к нулевой гипотезе. Примечание 2 - Альтернативная гипотеза может быть обозначена Примечание 3 - Альтернативная гипотеза является утверждением, которое опровергает нулевую гипотезу. Для выбора между нулевой и альтернативной гипотезами используют соответствующую статистику критерия (1.52). Примечание 4 - Альтернативная гипотеза не может быть рассмотрена отдельно как от нулевой гипотезы, так и от статистического критерия (1.48). Примечание 5 - Принятие альтернативной гипотезы в противовес невозможности принятия нулевой гипотезы является положительным результатом, состоящим в том, что в данном случае исследуемая гипотеза подтверждена. | fr |
|
1.43 простая гипотеза: Гипотеза (1.40), устанавливающая единственное распределение в семействе распределений (2.8). | en | simple hypothesis |
Примечание 1 - Простой гипотезой является либо нулевая гипотеза (1.41), либо альтернативная гипотеза (1.42), для которых выбранное подмножество возможных подходящих распределений составляет только одно распределение (2.11). Примечание 2 - Для случайной выборки (1.6) независимых случайных величин (2.10) с одним и тем же нормальным распределением (2.50) при неизвестных математическом ожидании (2.35) и стандартном отклонении (2.37) Примечание 3 - Простая гипотеза полностью определяет распределение (2.11). | fr |
|
1.44 сложная гипотеза: Гипотеза, задающая более одного распределения (2.11) из семейства распределений (2.8). | en | composite hypothesis |
Пример 1 - Нулевая гипотеза (1.41) и альтернативная гипотеза (1.42), представленные в примерах 1.41 и 1.42, являются примерами сложных гипотез. Примечание - Сложной гипотезой являются нулевая гипотеза (1.41) и/или альтернативная гипотеза (1.42), для которых выбранное подмножество распределений составляет более одного распределения (2.11). | fr |
|
1.45 уровень значимости; | en | significance level |
Примечание - Если нулевая гипотеза является простой гипотезой (1.43), то вероятность ошибочного отклонения нулевой гипотезы представляет собой единственное значение. | fr | niveau de signification |
1.46 ошибка первого рода: Отклонение нулевой гипотезы (1.41) в том случае, когда она верна. | en | Type I error |
Примечание 1 - Фактически ошибка первого рода является принятием неверного решения. Поэтому предпочтительно, чтобы вероятность (2.5) такой ошибки была настолько мала, насколько это возможно. При нулевой вероятности ошибки первого рода нулевая гипотеза никогда не будет отвергнута, т.е. она будет принята безотносительно к каким-либо основаниям. Примечание 2 - Возможно, что в некоторых ситуациях (например, исследование биномиального параметра | fr | erreur de |
1.47 ошибка второго рода: Принятие нулевой гипотезы (1.41) в том случае, когда она не верна. | en | Type II error |
Примечание - Фактически ошибка второго рода является принятием неверного решения. Поэтому желательно, чтобы вероятность (2.5) такой ошибки была настолько мала, насколько это возможно. Ошибка второго рода, как правило, имеет место в тех ситуациях, когда объем выборки недостаточен для выявления отклонений от нулевой гипотезы. | fr | erreur de seconde |
1.48 статистический критерий, критерий значимости: Процедура, предназначенная для принятия решения о том, может ли быть отклонена нулевая гипотеза (1.41) в пользу альтернативной гипотезы (1.42). | en | statistical test |
Пример 1 - Например, если непрерывная случайная величина (2.29) принимает значения от | fr | test statistique |
| ||
Во всех трех случаях гипотезы сформулированы на основе предположений относительно альтернативной гипотезы и ее отклонения от базового условия. Примечание 1 - Статистический критерий - это процедура, выполнение которой с заданными условиями на основе выборочных данных позволяет принимать решения о том, какая из гипотез относительно распределения наблюдаемой случайной величины (нулевая или альтернативная) является истинной. Примечание 2 - Перед применением статистического критерия на основе доступной информации определяют набор возможных функций распределений. Затем определяют распределения, которые на основе выдвинутого предположения могут быть истинными распределениями и составляют альтернативную гипотезу. Затем формулируют нулевую гипотезу как дополнение к альтернативной гипотезе. Во многих случаях возможная совокупность функций распределения, а следовательно, нулевая и альтернативная гипотезы могут быть определены на основе набора значений соответствующих параметров. Примечание 3 - Так как решение принимают на основе наблюдений из случайной выборки, то может иметь место ошибка первого рода (1.46), т.е. отклонение нулевой гипотезы, когда она верна, или ошибка второго рода (1.47), т.е. принятие нулевой гипотезы, когда альтернативная гипотеза верна. | ||
Примечание 4 - Случаи 1 и 2, рассмотренные в примере 3, представляют собой примеры односторонних критериев. Случай 3 - пример двустороннего критерия. Во всех трех случаях выбор применения одностороннего или двустороннего статистического критерия основан на рассмотрении области изменения значения параметра Примечание 5 - Выдвигаемые предположения тщательно продумывают, иначе применение статистического критерия может быть некорректным. Статистические критерии, позволяющие получить решения, на которые не влияет наличие неточностей в выдвигаемых предположениях, относятся к робастным. Считают, что | ||
1.49 p-значение: Вероятность (2.5) того, что наблюдаемое значение статистики критерия (1.52) или наблюдаемое значение некоторого соответствующего параметра не благоприятствует принятию нулевой гипотезы (1.41). | en | p-value |
| fr | valeur p |
Примечание 1 - Если, например, Примечание 2 - Термин | ||
1.50 мощность критерия: Единица минус вероятность (2.5) ошибки второго рода (1.47). | en | power of a test |
Примечание 1 - Мощность критерия для заданного значения неизвестного параметра (2.9) в семействе распределений (2.8) равна вероятности отклонения нулевой гипотезы (1.41) при данном значении параметра. Примечание 2 - На практике в большинстве случаев увеличение объема выборки приводит к увеличению мощности критерия. Другими словами, вероятность отклонения нулевой гипотезы, когда верна альтернативная гипотеза (1.42), возрастает вместе с увеличением выборки, тем самым снижая вероятность ошибки второго рода. Примечание 3 - Предпочтительно, чтобы объем выборки был достаточно большим, это важно для обнаружения даже небольших отклонений от нулевой гипотезы и, как следствие, для отклонения нулевой гипотезы. Другими словами, мощность критерия должна приближаться к единице для каждой альтернативы нулевой гипотезы вместе с неограниченным увеличением объема выборки. Такие критерии называют состоятельными. При сравнении двух критериев по мощности критерий с более высокой мощностью считают более эффективным при условии, что уровни значимости идентичны, а также совпадают нулевые и альтернативные гипотезы. Более формальное математическое описание состоятельности и эффективности критерия выходит за рамки настоящего стандарта. Для получения подобной информации могут быть использованы книги и справочники по статистике и математической статистике. | fr | puissance d’un test |
1.51 кривая мощности: Набор значений мощности критерия (1.50) как функция параметра (2.9) генеральной совокупности из семейства распределений (2.8). | en | power curve |
Примечание - См. также термин "кривая оперативной характеристики" (ИСО 3534-2:2006, 4.5.1). | fr | courbe de puissance |
1.52 статистика критерия: Статистика (1.8), используемая вместе со статистическим критерием (1.48). | en | test statistic |
Примечание - Статистику критерия используют для определения того, какой гипотезе - нулевой (1.41) или альтернативной (1.42) - соответствует распределение (2.11). | fr | statistique de test |
1.53 графическая описательная статистика: Описательная статистика (1.5), представленная в графической форме. | en | graphical descriptive statistics |
Примечание - Как правило, описательную статистику используют для редуцирования большого количества значений до небольшого управляемого числа или для представления в наглядной форме. Примерами графических представлений данных являются "ящики с усами", график вероятности, график "квантиль-квантиль", график нормального квантиля, точечная диаграмма, диаграмма рассеяния и гистограмма (1.61). | fr | statistique descriptive graphique |
1.54 числовая описательная статистика: Описательная статистика (1.5), представленная в числовой форме. | en | numerical descriptive statistics |
Примечание - Числовыми описательными статистиками являются выборочное среднее (1.15), выборочный размах (1.10), выборочное стандартное отклонение (1.17), интерквантильный размах и т.п. | fr | statistique descriptive |
1.55 классы | en | classes |
Примечание - Предполагают, что классы полны и не пересекаются. Действительная прямая представляет собой все действительные числа между | fr | classes |
1.55.1 класс (качественная характеристика): Подмножество элементов выборки (1.3). | en | class |
fr | classe | |
1.55.2 класс (порядковая характеристика): Множество, состоящее из одной или нескольких смежных категорий на порядковой шкале. | en | class |
fr | classe | |
1.55.3 класс (количественная характеристика): Отрезок действительной прямой. | en | class |
fr | classe | |
1.56 границы класса; пределы класса (количественная характеристика): Значения, определяющие верхнюю и нижнюю границы класса (1.55). | en | class limits, class boundaries |
Примечание - Данное определение относится к классам с количественной характеристикой. | fr | bornes de classe, |
1.57 середина класса (количественная характеристика): Среднее арифметическое верхней и нижней границ класса (1.56). | en | mid-point of class |
fr | centre de classe | |
1.58 ширина класса (количественная характеристика): Верхняя граница класса минус нижняя граница класса (1.55). | en | class width |
fr | effectif de la classe | |
1.59 частота: Количество событий или наблюдаемых значений (1.4) в заданом классе (1.55). | en | frequency |
fr |
| |
1.60 распределение частот: Эмпирическое соотношение между классами (1.55) и количеством событий или наблюдаемых значений (1.4) в классах. | en | frequency distribution |
fr | distribution de |
1.61 гистограмма: Графическое представление распределения частот (1.61) в виде прилегающих друг к другу прямоугольников, основаниями которых служат отрезки, равные ширине классов (1.58), а площади прямоугольника пропорциональны частотам в этих классах. | en | histogram |
Примечание - Осторожности требуют ситуации, в которых анализируемые данные относятся к классам с разной шириной класса. | fr | histogramme |
1.62 столбиковая диаграмма: Графическое представление распределения частот (1.61) номинальной характеристики, состоящее из прямоугольников, имеющих одинаковую ширину и высоту, пропорциональную частоте (1.59). | en | bar chart |
Примечание 1 - Иногда, очевидно в эстетических целях, диаграммы изображают как трехмерные объекты, хотя это не добавляет никакой дополнительной информации и не является рекомендуемым представлением диаграмм. В столбиковой диаграмме прямоугольники могут не прилегать друг к другу. Примечание 2 - Различие между гистограммой и столбиковой диаграммой становится все более размытым, что поддерживается в ряде программных пакетов статистической обработки данных, где данные понятия не разграничены приведенными выше определениями. | fr | diagramme en |
1.63 кумулятивная частота: Частота (1.59) для классов с накоплением, включая их установленные границы. | en | cumulative frequency |
Примечание - Это определение применимо только для заданных значений, соответствующих границам класса. | fr |
|
1.64 относительная частота: Частота (1.59), деленная на общее число событий или наблюдаемых значений (1.4). | en | relative frequency |
fr |
| |
1.65 кумулятивная относительная частота: Кумулятивная частота (1.59), деленная на число событий или наблюдаемых значений (1.4). | en | cumulative relative frequency |
fr |
|
2 Термины, используемые в теории вероятностей
2.1 пространство элементарных событий; | en | sample space |
fr | espace | |
Пример 1 - Рассмотрим время, за которое разряжается батарея, приобретенная потребителем. Если батарея разряжена еще до первого использования, то время разрядки считают равным нулю. Если батарея функционирует некоторое время, то время разрядки указывают в часах. Таким образом, пространство элементарных событий состоит из следующих исходов: {батарея разряжена до первого использования} и {батарея функционировала до разрядки x часов, где x более или равно нулю}. Настоящий пример и далее использован в данном разделе. В частности, обсуждение этого примера приведено в 2.68. Примечание 1 - Исходами могут быть результаты реального или гипотетического эксперимента. Множество исходов может быть явно предъявленным списком, счетным множеством, например таким, как положительные целые числа {1, 2, 3, ...} или действительная прямая. Примечание 2 - Пространство элементарных событий является первым компонентом вероятностного пространства (2.68). |
| |
2.2 событие; A: Подмножество пространства элементарных событий (2.1). | en | event |
Пример 1 - Продолжая пример 1 из 2.1, следующие примеры событий {0}, (0, 2), {5,7}, [7, Примечание - Предположительно в результате эксперимента произошло некоторое событие, если получен исход, принадлежащий данному событию. События принадлежат сигма-алгебре событий (2.69) - второму компоненту вероятностного пространства (2.68). События естественным образом возникают в контексте азартных игр (покер, рулетка и т.д.), в которых число исходов определяет планы на выигрыш. | fr |
|
2.3 дополнительное событие; | en | complementary event |
fr |
| |
Пример 1 - В примере 1 из 2.1 дополнительным событием к событию {0} является событие (0, Примечание 1 - Дополнительное событие дополняет событие до пространства элементарных событий. Примечание 2 - Дополнительное событие также является событием. Примечание 3 - Для события Примечание 4 - Во многих случаях легче найти вероятность дополнительного события, чем самого события. Например, событию "в случайной выборке объема 10, отобранной из генеральной совокупности объема 1000, для которой предполагаемый процент дефектов составляет единицу, встречается по крайней мере один дефект", соответствует очень большое число элементарных исходов. Гораздо легче работать с дополнительным событием "не обнаружено ни одного дефекта". |
| |
2.4 независимые события: Пара событий (2.2) таких, что вероятность (2.5) пересечения этих событий равна произведению их вероятностей. | en | independent events |
Пример 1 - Бросают две игральные кости, красную и белую, таким образом, что число возможных элементарных исходов равно 36, вероятность каждого элементарного исхода равна 1/36. Событие | fr |
|
Примечание - Приведенное определение дано для случая двух событий, но может быть расширено. Для событий
В общем случае, если число событий более двух, события | ||
2.5 вероятность события; A, P(A): Действительное число из замкнутого промежутка [0, 1], приписываемое событию (2.2). | en | probability of an event |
Пример - В примере 2 из 2.1 вероятность события может быть найдена как сумма вероятностей всех элементарных исходов, составляющих событие. Если вероятности всех 45 элементарных исходов совпадают, каждый из них имеет вероятность 1/45. Вероятность события может быть найдена путем подсчета всех соответствующих событию элементарных исходов и последующего деления этого числа на 45. Примечание 1 - Вероятностная мера (2.70) обеспечивает присвоение действительного числа каждому рассматриваемому событию, заданному на пространстве элементарных исходов. Для отдельного события вероятностная мера задает вероятность, связанную с этим событием. Другими словами, задает полный набор назначений для всех событий, тогда как вероятность представляет собой одно конкретное значение, приписанное отдельному событию. Примечание 2 - В данном определении вероятность рассматривают как вероятность отдельного события. Вероятность может быть связана с относительной частотой реализации события в длинной серии наблюдений или со степенью уверенности в возможной реализации события. Как правило, вероятность события | fr |
|
2.6 условная вероятность; | en | conditional probability |
Пример 1 - В рамках примера 1 (2.1) пусть событие (2.2) A определено как {батарея функционирует по крайней мере 3 ч}, т.е. ему соответствует интервал [3, Примечание 1 - Необходимо, чтобы вероятность события Примечание 2 - Используемое выражение " Примечание 3 - Если условная вероятность события | fr |
|
2.7 функция распределения (случайной величины X); F(x): Функция | en | distribution function of a random variable X | ||||
Примечание 1 - Полуинтервал ( | fr | fonction de | ||||
Примечание 2 - Функция распределения полностью описывает распределение вероятностей (2.11) случайной величины (2.10). Классификация распределений так же, как и классификация случайных величин на дискретные и непрерывные, основана на классификации функций распределения. Примечание 3 - Так как значениями случайных величин являются действительные числа или упорядоченные наборы Примечание 4 - Обычно функции распределения подразделяют на функции дискретных распределений (2.22) и функции непрерывных распределений (2.23), хотя это подразделение не исчерпывает все возможные случаи. Так, в примере со временем функционирования батареи, приведенном в 2.1, функция распределения может иметь следующий вид:
При таком задании функции распределения время функционирования батареи принимает неотрицательные значения. С вероятностью 0,1 батарея не будет функционировать при начальном использовании. Если батарея изначально функционировала, то время функционирования батареи имеет экспоненциальное распределение (2.58) с математическим ожиданием, равным 1 ч. Примечание 5 - Иногда применяют англоязычную аббревиатуру для обозначения функции распределения cdf (англ. "cumulative distribution function" - кумулятивная функция распределения). | ||||||
2.8 семейство распределений: Множество распределений вероятностей (2.8). | en | family of distributions | ||||
Примечание 1 - Множество распределений вероятностей часто индексируют с помощью параметра (2.9) функции распределения. Примечание 2 - Математическое ожидание (2.35) и/или дисперсию (2.36) распределения вероятностей часто используют для идентификации семейства распределений или для частичной идентификации, если для описания семейства распределений необходимо использовать более двух параметров. В некоторых случаях математическое ожидание и дисперсия представляют собой не явные параметры семейства распределений, а функции других параметров. | fr | famille de distributions | ||||
2.9 параметр: Признак семейства распределений (2.8). | en | parameter | ||||
Примечание 1 - Параметр может быть одномерным или многомерным. Примечание 2 - Иногда некоторые параметры называют параметрами положений, особенно в тех случаях, когда параметр непосредственно связан с математическим ожиданием семейства распределений. Некоторые параметры называют параметрами масштаба, особенно если такой параметр равен или пропорционален стандартному отклонению (2.37) распределения. Параметры, не являющиеся параметрами положения или параметрами масштаба, как правило, называют параметрами формы. | fr |
| ||||
2.10 случайная величина: Функция, определенная на пространстве элементарных событий (2.1), значениями которой являются упорядоченные наборы | en | random variable | ||||
Примечание 1 - Запись Примечание 2 - Размерность случайной величины часто обозначают латинской буквой Примечание 3 - Одномерная случайная величина - это функция, значениями которой являются действительные числа; она определена на пространстве элементарных событий (2.1), которое является одной из составляющих вероятностного пространства (2.68). Примечание 4 - Случайную величину, значениями которой являются упорядоченные пары действительных чисел, называют двумерной. Определение расширяет упорядоченные (пары) действительных чисел упорядоченного набора Примечание 5 - Компонент с номером | fr | variable | ||||
2.11 распределение (вероятностей): Вероятностная мера (2.70), индуцированная случайной величиной (2.10). | en | probability distribution, distribution | ||||
Пример - В примере с батареей, введенном в 2.1, распределение времени работы батареи полностью описывает вероятности возникновения установленных значений. Но невозможно с уверенностью определить ни время отказа данной батареи, ни даже то, будет ли она функционировать при начальном использовании. Вероятностное распределение полностью описывает вероятностные свойства неопределенности результата. В примечании 4 к 2.7 приведено одно из возможных представлений распределения вероятностей, а именно функция распределения. Примечание 1 - Существуют многочисленные, математически эквивалентные представления распределения, к ним относятся функция распределения (2.7), функция плотности распределения (2.27) [если существует] и характеристическая функция. Данные представления с различными уровнями сложности позволяют определять вероятность, с которой случайная величина принимает значения в заданном диапазоне. Примечание 2 - Так как случайная величина представляет собой функцию, заданную на подмножествах пространства элементарных событий и принимающую значения на действительной оси, то, например, вероятность того, что случайная величина примет некоторое действительное значение, равна единице. В примере с батареей Примечание 3 - Если случайная величина одномерна, то говорят об одномерном распределении вероятностей. Если случайная величина двумерна, говорят о двумерном распределении вероятностей. Если случайная величина имеет более двух компонент, говорят о многомерном распределении вероятностей. | fr | loi de | ||||
2.12 математическое ожидание: Интеграл функции случайной величины (2.10) по вероятностной мере (2.70) на пространстве элементарных событий (2.1). | en | expectation | ||||
Примечание 1 - Математическое ожидание функции
где Примечание 2 - Латинская буква " ________________ * Текст документа соответствует оригиналу. - . Примечание 3 - Для Примечание 4 - На практике приведенный выше интеграл представляют в более удобной для вычисления форме. Примеры представлены в примечаниях к терминам: момент порядка Примечание 5 - Данное определение не ограничено одномерными интегралами, как можно было бы предположить из приведенных примеров и замечаний. Ситуации более высоких размерностей представлены в 2.43. Примечание 6 - Для дискретной случайной величины (2.28) второй интеграл, приведенный в примечании 1, заменяют на символ суммирования. Примеры могут быть найдены в 2.35. | fr |
| ||||
2.13 квантиль уровня p; фрактиль уровня | en | p-quantile, | ||||
Пример 1 - Рассмотрим биномиальное распределение (2.46) с функцией распределения вероятностей, представленной в таблице 2. Данное множество значений соответствует биномиальному распределению параметрами n=6 и p=0,3. Для данного случая рассмотрены некоторые р-квантили: | fr | quantile d’ordre p, fractile d’ordre p | ||||
X | P[X=x] | P[X | P[X>x] | |||
0 | 0,117649 | 0,117649 | 0,882351 | |||
1 | 0,302526 | 0,420175 | 0,579825 | |||
2 | 0,324135 | 0,744310 | 0,255690 | |||
3 | 0,185220 | 0,929530 | 0,070470 | |||
4 | 0,059535 | 0,989065 | 0,010935 | |||
5 | 0,010206 | 0,999271 | 0,000729 | |||
6 | 0,000729 | 1,000000 | 0,000000 | |||
Пример 2 - Рассмотрим стандартное нормальное распределение (2.51), в таблице 3 представлены отдельные значения его функции распределения. | ||||||
| Значения | |||||
0,1 | -1,282 | |||||
0,25 | -0,674 | |||||
0,5 | 0,000 | |||||
0,75 | 0,674 | |||||
0,84134475 | 1,000 | |||||
0,9 | 1,282 | |||||
0,95 | 1,645 | |||||
0,975 | 1,960 | |||||
0,99 | 2,326 | |||||
0,995 | 2,576 | |||||
0,999 | 3,090 | |||||
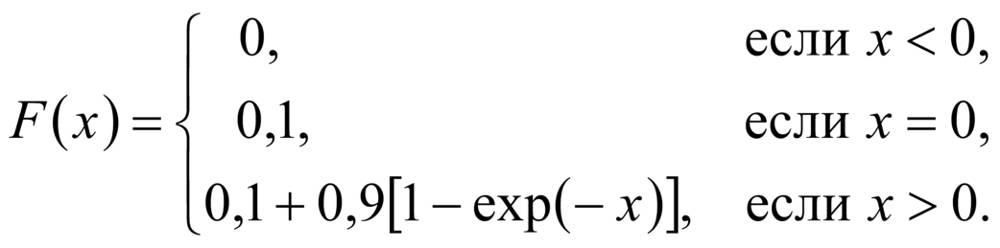
Так как распределение X непрерывно, то вторая колонка таблицы также могла бы иметь заглавие. Значения x такие, что P[X<x]=p. Примечание 1 - Для непрерывных распределений (2.23) при Примечание 2 - В общем случае Примечание 3 - Если Примечание 4 - Если на некотором промежутке функция распределения постоянна и равна Примечание 5 - Квантили уровня | ||
2.14 медиана: Квантиль уровня 0,5 (2.13). | en | median |
Пример - Для примера с батареей из примечания 4 к 2.7 медиана составляет 0,5878; данное значение найдено как решение относительно x уравнения 0,1+0,9[1-exp(-x)]=0,5. Примечание 1 - На практике медиана - наиболее часто применяемый квантиль (2.13). Медиана непрерывного одномерного распределения (2.16) - это такое значение, что половина значений в генеральной совокупности (1.1) более или равна ему, а другая половина значений менее или равна этому значению. Примечание 2 - Медиана определена для одномерного распределения (2.16). | fr |
|
2.15 квартиль: Квантиль уровня 0,25 (2.13) или 0,75. | en | quartile |
Пример - Для примера с батареей из 2.14 можно показать, что квантиль уровня 0,25 составляет 0,1823, а квантиль уровня 0,75 - 1,2809. Примечание 1 - Квантиль уровня 0,25 также называют нижним квартилем, а квантиль уровня 0,75 - верхним квартилем. Примечание 2 - Квартили определены для одномерного распределения (2.16). | fr | quartile |
2.16 одномерное распределение (вероятностей): Распределение (2.11) единственной случайной величины (2.10). | en | univariate probability distribution, univariate distribution |
Примечание - Одномерные распределения являются распределениями одной переменной. Примерами таких распределений могут быть биномиальное распределение (2.46), распределение Пуассона (2.47), нормальное распределение (2.50), гамма-распределение (2.56), | fr | loi de |
2.17 многомерное распределение (вероятностей): Распределение (2.11) двух или более случайных величин (2.10). Примечание 1 - Для распределения в точности двух случайных величин прилагательное "многомерное" обычно заменяют на "двумерное". Распределение одной случайной величины, как упомянуто ранее, называют одномерным распределением (2.16). Так как рассматривают распределение одной случайной величины, то, если не указано иное, предполагают, что распределение является одномерным. | en | multivariate probability distribution, multivariate distribution |
Примечание 2 - Многомерное распределение иногда называют совместным распределением. Примечание 3 - Полиномиальное распределение (2.45), двумерное нормальное распределение (2.65) и многомерное нормальное распределение (2.64) - примеры многомерных распределений, представленных в настоящем стандарте. | fr | loi de |
2.18 частное распределение (вероятностей): Распределение вероятностей (2.11) заданного непустого подмножества множества компонент случайной величины (2.10). | en | marginal probability distribution, marginal distribution |
Примечание 1 - Для совместного Примечание 2 - Для непрерывного (2.23) многомерного распределения (2.17), заданного его функцией плотности распределения (2.26), функцией плотности распределения частного распределения является интеграл от функции плотности исходного распределения, взятый по области изменения величин, не рассматриваемых в частном распределении. Примечание 3 - Для дискретного (2.22) многомерного распределения, представленного его функцией распределения (2.24), функцию распределения частного распределения определяют суммированием функции распределения по области изменения величин, не рассматриваемых в частном распределении. | fr | loi de |
2.19 условное распределение (вероятностей): Распределение (2.11), ограниченное непустым подмножеством пространства элементарных событий (2.1) и скорректированное таким образом, что общая вероятность событий на данном подмножестве составляет единицу. | en | conditional probability distribution, conditional distribution |
Пример 1 - В примере с батареей, рассмотренном в примечании 4 из 2.7, условное распределение времени работы батареи при условии изначального функционирования батареи является экспоненциальным (2.58). Примечание 1 - Например, для распределения двух случайных величин Примечание 2 - Частное распределение (2.18) следует рассматривать как безусловное распределение. Примечание 3 - Представленный выше пример 1 иллюстрирует ситуацию, когда одномерное распределение скорректировано условиями, накладываемыми другим одномерным распределением (отличным от первого). Напротив, для экспоненциального распределения условное распределение того, что батарея откажет в следующий час функционирования, при условии, что в течение предыдущих 10 ч она не отказала, также является экспоненциальным с тем же параметром. Примечание 4 - Условные распределения могут возникать для некоторых дискретных распределений в том случае, когда отдельные исходы являются невозможными. Например, распределение Пуассона может служить моделью распределения числа больных раком среди людей, имеющих опухоли. Примечание 5 - Условные распределения появляются при ограничении пространства элементарных событий до его конкретного подмножества. Для | fr | loi de |
2.20 кривая регрессии: Набор значений математических ожиданий (2.12) условного распределения (2.19) случайной величины (2.10) | en | regression curve |
Примечание - Кривая регрессии определена в предположении, что | fr | courbe de |
2.21 поверхность регрессии: Набор значений математических ожиданий (2.12) условного распределения (2.19) случайной величины (2.10) | en | regression surface |
Примечание - Как и 2.20, поверхность регрессии определена в предположении, что величина | fr | surface de |
2.22 дискретное распределение (вероятностей): Распределение (2.11), для которого пространство элементарных событий | en | discrete probability distribution, discrete distribution |
Примечание 1 - Термин "дискретное" подразумевает, что пространство элементарных событий может быть задано в виде конечного списка либо в виде начала бесконечного списка, для которого понятен способ получения следующего элемента списка, например количество дефектов может быть представлено рядом 0, 1, 2. Примером распределения, соответствующего конечному пространству элементарных событий {0,1,2,...,}, является биномиальное распределение; примером распределения, соответствующего бесконечному счетному пространству элементарных событий {0,1,2,...,}, - распределение Пуассона. Примечание 2 - В статистическом приемочном выборочном контроле случаи, когда данные имеют качественную характеристику, свидетельствуют о том, что данные соответствуют дискретному распределению. Примечание 3 - Областью значений функции распределения (2.7) дискретного распределения является дискретное множество. | fr | loi de |
2.23 непрерывное распределение (вероятностей): Распределение (2.11), для которого функция распределения (2.7) от | en | continuous probability distribution, continuous distribution |
Примечание 1 - Примеры непрерывных распределений: нормальное распределение (2.50), стандартное нормальное распределение (2.51), Примечание 2 - Неотрицательная функция, упоминаемая в определении, является функцией плотности распределения (2.62). Утверждение, состоящее в том, что функция распределения везде дифференцируема, является чрезмерно ограничительным. Однако при практическом рассмотрении многие часто используемые непрерывные распределения обладают тем свойством, что производная функции распределения является соответствующей функцией плотности распределения. Примечание 3 - В статистическом приемочном выборочном контроле случаи, когда данные имеют количественную характеристику, свидетельствуют о том, что данные соответствуют непрерывному распределению вероятностей. | fr | loi de |
2.24 функция вероятности: (Для дискретного распределения) функция, задающая вероятность (2.5) того, что случайная величина (2.10) равна заданному значению. | en | probability mass function |
Пример 1 - Функция вероятности, описывающая случайную величину X, равную числу выпадения "орлов" при бросании трех "идеальных" монет, имеет вид: Примечание 1 - Функция вероятности может быть задана в виде Примечание 2 - Функция вероятности введена в примере с квантилем уровня | fr | fonction de masse de |
2.25 мода функции вероятности: Значение, при котором функция вероятности (2.24) достигает локального максимума. | en | mode of probability mass function |
Пример - Биномиальное распределение (2.46) для n=6 и p=1/3 является унимодальным с модой, равной трем. Примечание - Дискретное распределение (2.22) является унимодальным, если его функция вероятности имеет единственную моду, двухмодальным, если его функция вероятности имеет ровно две моды, и мультимодальным, если число мод функции вероятности более двух. | fr | mode de fonction de masse de |
2.26 функция плотности распределения (вероятностей); f(x); плотность распределения: Неотрицательная функция, при интегрировании которой по интервалу от | en | probability density function |
Примечание 1 - Если функция распределения Примечание 2 - Графическое представление Примечание 3 - Для функции плотности распределения часто используют английскую аббревиатуру - pdf (англ. "probability density function"). | fr | fonction de |
2.27 мода функции плотности распределения (вероятностей): Значение, где функция плотности распределения (2.26) достигает локального максимума. | en | mode of probability density function |
Примечание 1 - Непрерывное распределение (2.23) является унимодальным, если его функция плотности распределения имеет одну моду, двухмодальным, если его функция плотности распределения имеет две моды, и мультимодальным, если его функция плотности распределения имеет более двух мод. Примечание 2 - Распределение, у которого моды составляют связное множество, также называют унимодальным. | fr | mode de fonction de |
2.28 дискретная случайная величина: Случайная величина (2.10), имеющая дискретное распределение (2.22). | en | discrete random variable |
Примечание - В настоящем стандарте рассмотрены дискретные случайные величины, подчиняющиеся биномиальному (2.46), пуассоновскому (2.47), гипергеометрическому (2.48) и полиномиальному (2.45) распределениям. | fr | variable |
2.29 непрерывная случайная величина: Случайная величина (2.10), имеющая непрерывное распределение (2.23). | en | continuous random variable |
Примечание - В настоящем стандарте рассмотрены непрерывные случайные величины, подчиняющиеся нормальному распределению (2.50), стандартному нормальному распределению (2.51), | fr | variable |
2.30 центрированное распределение: Распределение (2.11) центрированной случайной величины (2.31). | en | centred probability distribution |
fr | loi de | |
2.31 центрированная случайная величина: Случайная величина, представляющая собой разность случайной величины (2.10) и ее среднего (2.35). | en | centred random variable |
Примечание 1 - Центрированная случайная величина имеет математическое ожидание, равное нулю. Примечание 2 - Данный термин применим только к случайным величинам, имеющим среднее. Например, среднее для Примечание 3 - Если случайная величина | fr | variable |
2.32 стандартизованное распределение: Распределение (2.11) стандартизованной случайной величины (2.33). | en | standardized probability distribution |
fr | loi de | |
2.33 стандартизованная случайная величина: Центрированная случайная величина (2.31), стандартное отклонение (2.37) которой равно единице. | en | standardized |
Примечание 1 - Случайная величина (2.10) автоматически является стандартизованной, если ее среднее равно нулю, а стандартное отклонение - единице. Равномерное распределение на интервале (-3 Примечание 2 - Если распределение (2.11) случайной величины | fr | variable |
2.34 момент порядка r; | en | moment of order r, rth moment |
Пример - Пусть случайная величина имеет функцию плотности распределения (2.26) f(x)=exp(-x) для x>0. С помощью базовых приемов интегрирования (интегрирование по частям) получаем E(X)=1, Примечание 1 - В одномерном дискретном случае соответствующая формула имеет следующий вид:
Примечание 2 - Если случайная величина является Примечание 3 - Рассмотренные моменты случайной величины используют возведение в степень | fr | moment d’ordre r |
2.35 среднее | en | means |
fr | moyennes | |
2.35.1 среднее; момент порядка | en | mean, moment of order |
Примечание 1 - Среднее непрерывного распределения (2.23) обозначают символом
Примечание 2 - Среднее существует не для всех случайных величин (2.10). Например, если | fr | moyenne, moment d’ordre |
2.35.2 среднее; | en | mean |
fr | moyenne de | |
Пример 1 - Пусть дискретная случайная величина X (2.28) представляет собой число выпадений "орлов" при бросании трех "идеальных" монет. Функция распределения имеет следующий вид: Примечание - Среднее дискретного распределения (2.22) обозначают
|
|
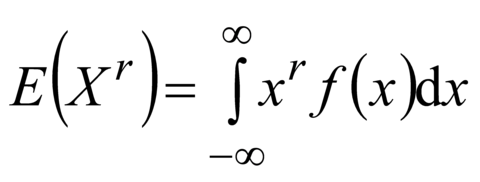 .
. .
.2.36 дисперсия; V: Момент порядка | en | variance | |||
Примечание - Эквивалентным определением дисперсии является "математическое ожидание (2.12) квадратичной случайной величины и ее среднего (2.35)". Дисперсию случайной величины | fr | variance | |||
2.37 стандартное отклонение; | en | standard deviation | |||
Пример - Для примера с батареей из 2.1 и 2.7 стандартное отклонение равно 0,995. | fr |
| |||
2.38 коэффициент вариации; CV: Для положительной случайной величины стандартное отклонение (2.37), деленное на среднее (2.35). | en | coefficient of variation | |||
Пример - Для примера с батареей из 2.1 и 2.7 коэффициент вариации равен 0,99/0,995=0,99497. Примечание 1 - Обычно используют представление коэффициента вариации, выраженного в процентах. Примечание 2 - Данный термин заменяет ранее используемый термин "относительное стандартное отклонение". | fr | coefficient de variation | |||
2.39 коэффициент асимметрии; | en | coefficient of skewness | |||
Пример - Для примера с батареей из 2.1 и 2.7, где распределение является смесью непрерывного и дискретного распределений, с учетом примера к 2.34 Примечание 1 - Эквивалентное определение основано на математическом ожидании (2.12) третьей степени величины Примечание 2 - Коэффициент асимметрии является мерой симметрии распределения (2.11), его иногда обозначают как | fr | coefficient | |||
2.40 коэффициент эксцесса; | en | coefficient of kurtosis | |||
Пример - Для примера с батареей из 2.1 и 2.7, учитывая, что Примечание 1 - Эквивалентным определением является математическое ожидание (2.12) четвертой степени Примечание 2 - Коэффициент эксцесса является мерой тяжести хвостов распределения (2.11). Для равномерного распределения (2.60) коэффициент эксцесса составляет 1,8; для нормального распределения (2.50) коэффициент эксцесса равен 3; для экспоненциального распределения (2.58) коэффициент эксцесса равен 9. Примечание 3 - При рассмотрении значений эксцесса нужна осторожность, так иногда из значения, вычисленного в соответствии с определением, вычитают тройку (эксцесс нормального распределения). | fr | coefficient d’aplatissement | |||
2.41 смешанный момент порядков r и s: Среднее (2.35) произведения | en | joint moment of orders r and s | |||
fr | moment | ||||
2.42 центральный смешанный момент порядков r и s: Среднее (2.35) произведения | en | joint central moment of orders r and s | |||
fr | moment | ||||
2.43 ковариация; | en | covariance | |||
Примечание 1 - Ковариация является центральным смешанным моментом порядков 1 и 1 (2.42) двух случайных величин. Примечание 2 - Ковариация имеет вид - | fr | covariance | |||
2.44 коэффициент корреляции: Среднее (2.35) произведения двух стандартизованных случайных величин (2.33) в их совместном распределении (2.11). | en | correlation coefficient | |||
Примечание - Коэффициент корреляции иногда более кратко называют просто корреляцией. Однако данное употребление накладывается на интерпретацию корреляции как связи между двумя случайными величинами. | fr | coefficient de | |||
2.45 полиномиальное [мультиномиальное] распределение: Дискретное распределение (2.22), имеющее функцию распределения (2.24) | en | multinomial distribution | |||
где
Примечание - Полиномиальное распределение дает число реализаций каждого из | fr | loi multinomiale | |||
2.46 биномиальное распределение: Дискретное распределение (2.22) с функцией вероятности (2.24) | en | binomial distribution | |||
где Примечание 1 - Биномиальное распределение представляет собой специальный случай полиномиального распределения (2.45) при Примечание 2 - Биномиальное распределение дает вероятность числа реализации каждого из двух возможных исходов в Примечание 3 - Среднее (2.35) биномиального распределения равно Примечание 4 - В записи функции вероятности биномиального распределения может быть использован биномиальный коэффициент:
| fr | loi binomiale | |||
2.47 распределение Пуассона: Дискретное распределение (2.22) с функцией распределения (2.24) | en | Poisson distribution | |||
где Примечание 1 - При Примечание 2 - И среднее (2.35), и дисперсия (2.36) распределения Пуассона равны Примечание 3 - Функция вероятности (2.24) распределения Пуассона дает вероятность числа появлений события в единичный интервал времени при заданных условиях, например при независимости интенсивности появления от времени. | fr | loi de Poisson | |||
2.48 гипергеометрическое распределение: Дискретное распределение (2.22) с функцией распределения (2.24) | en | hypergeometric distribution | |||
где
Примечание 1 - Гипергеометрическое распределение (2.11) дает число помеченных объектов в простой случайной выборке (1.7) объема Примечание 2 - Таблица 4 содержит информацию об объектах гипергеометрического распределения. Таблица 4 - Гипергеометрическое распределение | fr | loi | |||
Множество | Отмеченные или неотмеченные объекты | Отмеченные объекты | Неотмеченные объекты | ||
Генеральная совокупность |
|
|
| ||
Объекты, попавшие в выборку |
|
|
| ||
Объекты, не попавшие в выборку |
|
|
| ||
Примечание 3 - При определенных условиях (например, Примечание 4 - Среднее (2.35) гипергеометрического распределения равно | |||||
 .
. ,
,2.49 отрицательное биномиальное распределение: Дискретное распределение (2.22) с функцией распределения (2.24)
| en | negative binomial distribution |
где Примечание 1 - При Примечание 2 - Функция вероятности может быть записана в эквивалентном виде:
Термин "отрицательное биномиальное распределение" является следствием данной записи функции вероятности. Примечание 3 - Версию записи функции распределения, данную в определении, часто называют "распределение Паскаля" при условии, что Примечание 4 - Среднее (2.35) отрицательного биномиального распределения равно | fr | loi binomiale |
2.50 нормальное распределение; распределение Гаусса: Непрерывное распределение (2.23) с функцией плотности распределения (2.26)
| en | normal distribution, Gaussian distribution |
где Примечание 1 - Одно из наиболее широко используемых распределений вероятностей (2.11) в прикладной статистике. Из-за формы функции плотности распределения ее неформально называют "колоколообразная" кривая. Данное распределение является предельным распределением выборочных средних (1.15). В статистике данное распределение широко используют как опорное распределение для анализа необычности экспериментальных результатов. Примечание 2 - Параметром положения | fr | loi normale, loi de Gauss |
2.51 стандартное нормальное распределение; стандартное распределение Гаусса: Нормальное распределение (2.50) с Примечание - Функция плотности распределения (2.26) стандартного нормального распределения: | en | standardized normal distribution, standardized Gaussian distribution |
где В таблицах нормального распределения используют функцию плотности распределения для вычисления площади под графиком | fr | loi normale |
2.52 логнормальное распределение: Непрерывное распределение (2.23) с функцией плотности распределения (2.26) | en | lognormal distribution |
где
Примечание 1 - Если Примечание 2 - Средним логнормального распределения является величина Примечание 3 - Логнормальное распределение и распределение Вейбулла (2.63) широко используют при анализе надежности. | fr | distribution lognormale |
2.53 t-распределение; распределение Стьюдента: Непрерывное распределение (2.23) с функцией плотности распределения (2.26)
| en |
|
fr | distribution | |
где
Примечание 1 - На практике Примечание 2 - Примечание 3 - Гамма-функция определена в 2.56. | loi de Student | |
2.54 число степеней свободы; | en | degrees of freedom |
Примечание - Данная идея первоначально имела место в контексте использования | fr |
|
2.55 F-распределение: Непрерывное распределение (2.23) с функцией плотности распределения вероятности (2.26) | en | F distribution |
где
Примечание 1 - Примечание 2 - | fr | loi de F |
2.56 гамма-распределение: Непрерывное распределение (2.23) с функцией плотности распределения (2.26) | en | gamma distribution |
где
Примечание 1 - Гамма-распределение используют в исследованиях надежности для моделирования наработки до отказа. Оно охватывает экспоненциальное распределение (2.58) как специальный случай, а также другие случаи, когда интенсивность отказов возрастает вследствие старения. Примечание 2 - Гамма-функцию определяют следующим образом:
Для целых значений Примечание 3 - Среднее (2.35) гамма-распределения равно | fr | loi gamma |
2.57 хи-квадрат-распределение,
| en | chi-squared distribution, |
где Примечание 1 - Для данных, описываемых нормальным распределением (2.50) с известным стандартным отклонением (2.37) Примечание 2 - Данное распределение при Примечание 3 - Среднее (2.35) | fr | loi de chi deux, |
2.58 экспоненциальное распределение: Непрерывное распределение (2.23) с функцией плотности распределения (2.26) | en | exponential distribution |
где Примечание 1 - Экспоненциальное распределение является базовым в исследовании надежности в случае отсутствия "старения" или отсутствия "памяти". Примечание 2 - Экспоненциальное распределение является частным случаем гамма-распределения (2.56) при Примечание 3 - Среднее (2.35) экспоненциального распределения равно | fr | loi exponentielle |
2.59 бета-распределение: Непрерывное распределение (2.23) с функцией плотности распределения (2.26) | en | beta distribution |
fr | loi | |
где Примечание - Бета-распределение очень изменчиво, его функция плотности распределения принимает разнообразные формы (унимодальную, J-образную, U-образную). Данное распределение используют как модель неопределенности, связанную с долями. Например, при моделировании страховых случаев, вызванных ураганами, наблюдаемая доля ущерба, связанного с разрушением определенного вида конструкций при заданной скорости ветра, может составлять 0,40, хотя некоторые сооружения испытывают такой же ущерб при меньшей скорости ветра вследствие накопления разрушений. Бета-распределение со средним 0,40 может служить моделью диспропорции ущерба для данного типа сооружений. | ||
2.60 равномерное распределение; прямоугольное распределение: Непрерывное распределение (2.23) с функцией плотности распределения (2.26)
| en | uniform distribution, rectangular distribution |
где Примечание 1 - Равномерное распределение с Примечание 2 - Среднее (2.35) равномерного распределения равно Примечание 3 - Равномерное распределение является частным случаем бета-распределения при | fr | loi uniforme, loi rectangulaire |
2.61 распределение экстремальных значений типа I; распределение Гумбеля: Непрерывное распределение (2.23) с функцией распределения (2.7)
| en | type I extreme value distribution, Gumbel distribution |
где Примечание - Распределение экстремальных значений является подходящим опорным распределением для распределения крайних порядковых статистик (1.9) | fr | loi des valeurs |
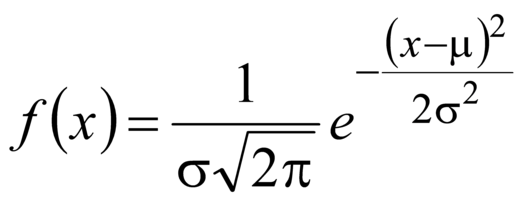 ,
, ,
, ,
, ,
,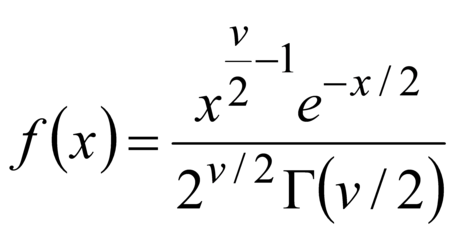 ,
,2.62 распределение экстремальных значений типа II; распределение Фреше: Непрерывное распределение (2.23) с функцией распределения (2.7)
| en | en type II extreme value distribution, |
где | fr | loi des valeurs |
2.63 распределение экстремальных значений типа III; распределение Вейбулла: Непрерывное распределение (2.23) с функцией распределения (2.7)
| en | type III extreme value distribution, Weibull distribution |
где Примечание 1 - В дополнение к тому, что данное распределение служит одним из трех возможных предельных распределений экстремальных порядковых статистик, распределение Вейбулла играет важную роль в различных приложениях, особенно в анализе надежности и инжиниринге. Оно дает эмпирическое приближение различных наборов данных. Примечание 2 - Параметр a является параметром положения в том смысле, что он является наименьшим значением, которого может достигать распределение Вейбулла. Параметр Примечание 3 - При | fr | loi des valeurs |
2.64 многомерное нормальное распределение: Непрерывное распределение (2.23) с функцией плотности вероятности (2.26):
| en | multivariate normal distribution |
где
жирным шрифтом выделены Примечание - Каждое из частных распределений (2.18) многомерного нормального распределения в данном случае имеет нормальное распределение. Однако кроме рассматриваемого распределения существует много других многомерных распределений, имеющих нормальные частные распределения. | fr | loi normale |
2.65 двумерное нормальное распределение: Непрерывное распределение (2.23) с функцией плотности распределения (2.26) | en | bivariate normal distribution |
где
Примечание 1 - Согласно приведенной записи для пары | fr | loi normale |
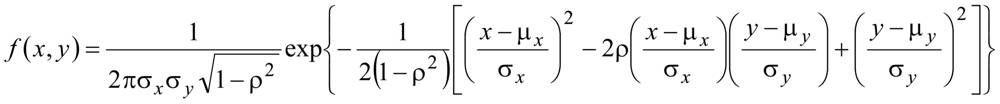 ,
,2.66 стандартное двумерное нормальное распределение: Двумерное нормальное распределение (2.65), имеющее стандартное нормальное распределение (2.51) компонент. | en | standardized bivariate normal distribution |
fr | loi normale | |
2.67 выборочное распределение: Распределение некоторой статистики. | en | sampling distribution |
Примечание - Иллюстрации некоторых выборочных распределений представлены в примечании 2 к 2.53, примечании 1 к 2.55 и примечании 1 к 2.57. | fr | distribution |
2.68 вероятностное пространство; ( | en | probability space |
| fr | espace de |
2.69 сигма-алгебра событий, a) события принадлежат | en | sigma algebra of events, |
b) если событие принадлежит c) если Примечание 1 - Сигма-алгебра - это множество, элементами которого являются множества. Множество всех возможных исходов Примечание 2 - Свойство с) касается набора операций на коллекции подмножеств (возможно, счетной мощности) сигма-алгебры событий. Его запись указывает на то, что все счетные объединения и пересечения этих множеств принадлежат сигма-алгебре событий. Примечание 3 - Согласно свойству с) сигма-алгебре событий также принадлежит замыкание конечного объединения или пересечения множеств. Спецификатор сигма используют, чтобы подчеркнуть, что множество замкнуто даже относительно счетного числа операций на множествах. | fr | sigma- tribu champ sigma |
2.70 вероятностная мера; | en | probability measure |
a) где b) где Примечание 1 - Вероятностная мера назначает каждому событию из сигма-алгебры событий число из замкнутого интервала [0, 1]. Значение вероятностной меры, равное единице, соответствует событию, которое обязательно произойдет. Вероятностная мера, приписываемая всему множеству элементарных событий, равна единице. Вероятностная мера невозможного события равна нулю. Примечание 2 - Свойство b) указывает на то, что при наличии последовательности событий, где каждая пара событий не содержит общих элементарных событий, вероятностная мера объединения данных событий равна сумме вероятностных мер отдельных событий. Данное свойство (как отражено в записи свойства) сохраняется для счетного числа событий. Примечание 3 - Три компонента вероятности действенным образом связаны через случайные величины. Вероятности (2.5) событий, соответствующие образу (множеству принимаемых значений) случайной величины (2.10), возникают как вероятности событий пространства элементарных событий. Событию, принадлежащему образу случайной величины, назначают вероятность события пространства элементарных событий, это отображение является отображением "на", производимым случайной величиной. Примечание 4 - Образ случайной величины - множество действительных чисел или множество упорядоченных наборов | fr | mesure de |
Приложение А
(справочное)
Обозначения
Обозначение | Термин | Номер в словаре |
| Событие | 2.2 |
| Дополнительное событие | 2.3 |
| Сигма-алгебра событий, | 2.69 |
| Уровень значимости | 1.45 |
| Параметр | |
| Коэффициент эксцесса (эксцесс) | 2.40 |
| Выборочный момент порядка | 1.14 |
| Математическое ожидание | 2.12 |
| Функция распределения случайной величины | 2.7 |
| Функция плотности вероятности | 2.26 |
| Коэффициент асимметрии | 2.39 |
| Гипотеза | 1.40 |
| Нулевая гипотеза | 1.41 |
| Альтернативная гипотеза | 1.42 |
| Размерность | |
| Порядок момента | 1.14, 2.34, 2.41, 2.42 |
| Среднее (математическое ожидание) | 2.35 |
Число степеней свободы | 2.54 | |
| Объем выборки | |
| Пространство элементарных событий | 2.1 |
( | Вероятностное пространство | 2.68 |
| Вероятность события | 2.5 |
| Условная вероятность, вероятность события | 2.6 |
| Вероятностная мера | 2.70 |
| Выборочный коэффициент корреляции | 1.23 |
Наблюдаемое значение выборочного стандартного отклонения | ||
| Выборочное стандартное отклонение | 1.17 |
| Выборочная дисперсия | 1.16 |
| Выборочная ковариация | 1.22 |
Стандартное отклонение | 2.37 | |
| Дисперсия | 2.36 |
| Ковариация | 2.43 |
| Стандартная ошибка | 1.24 |
| Стандартная ошибка выборочного среднего | |
| Параметр распределения | |
| Оценка | 1.12 |
| Дисперсия случайной величины | 2.36 |
|
| 1.9 |
| Наблюдаемое значение | 1.4 |
| Случайная величина | 2.10 |
|
| 2.13 |
| Среднее арифметическое, выборочное среднее | 1.15 |
Приложение В
(справочное)
Схемы для статистических терминов
|
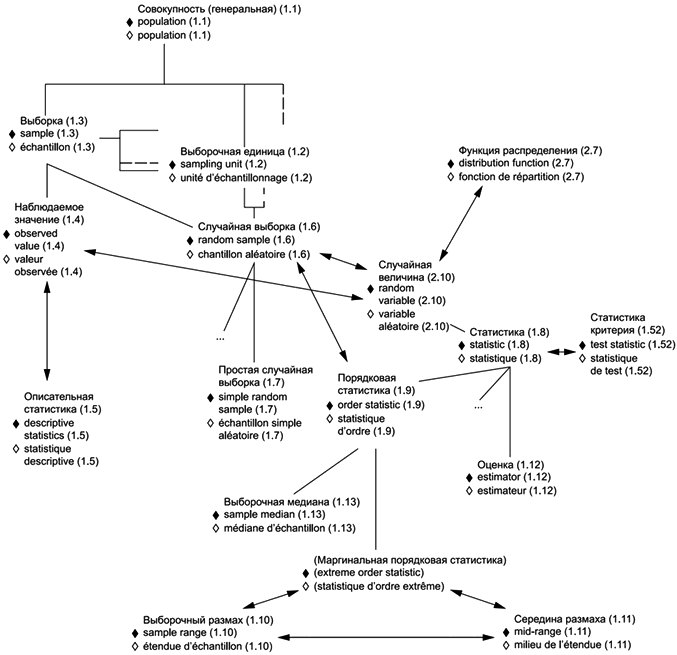
Рисунок В.1 - Основные понятия, связанные с выборкой и генеральной совокупностью
|
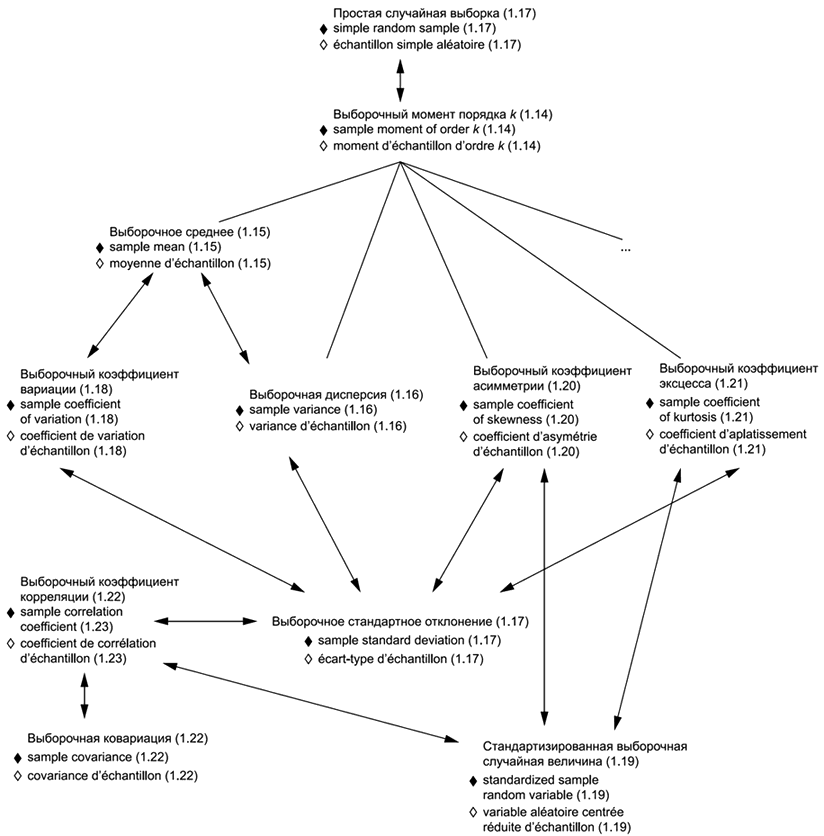
Рисунок В.2 - Основные понятия, связанные с выборочными моментами
|
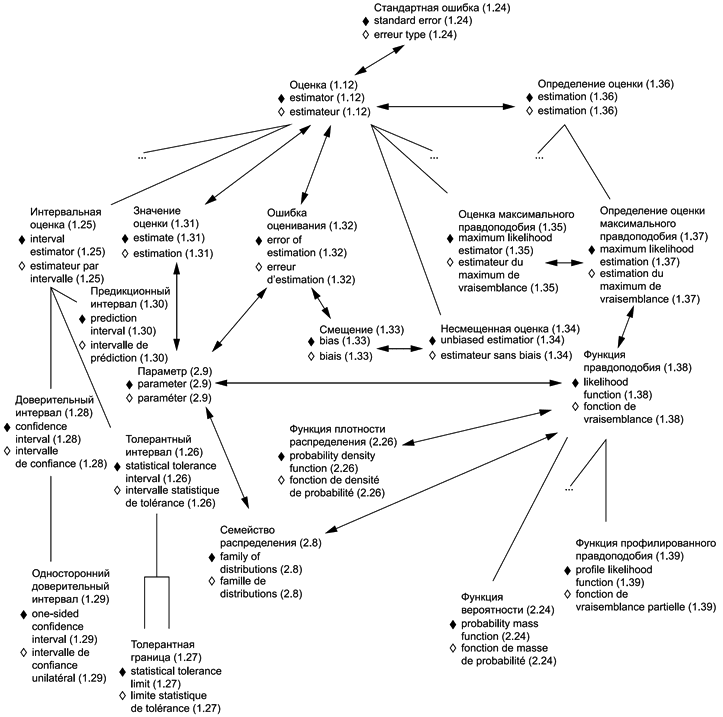
Рисунок В.3 - Понятия, связанные с получением оценок
|
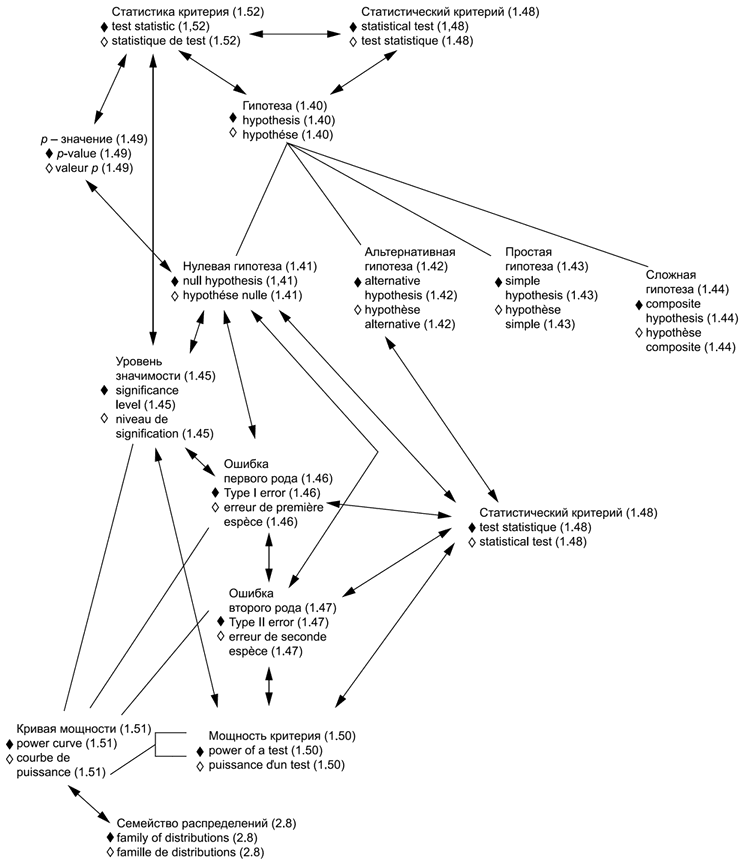
Рисунок В.4 - Понятия, связанные со статистическими критериями
|
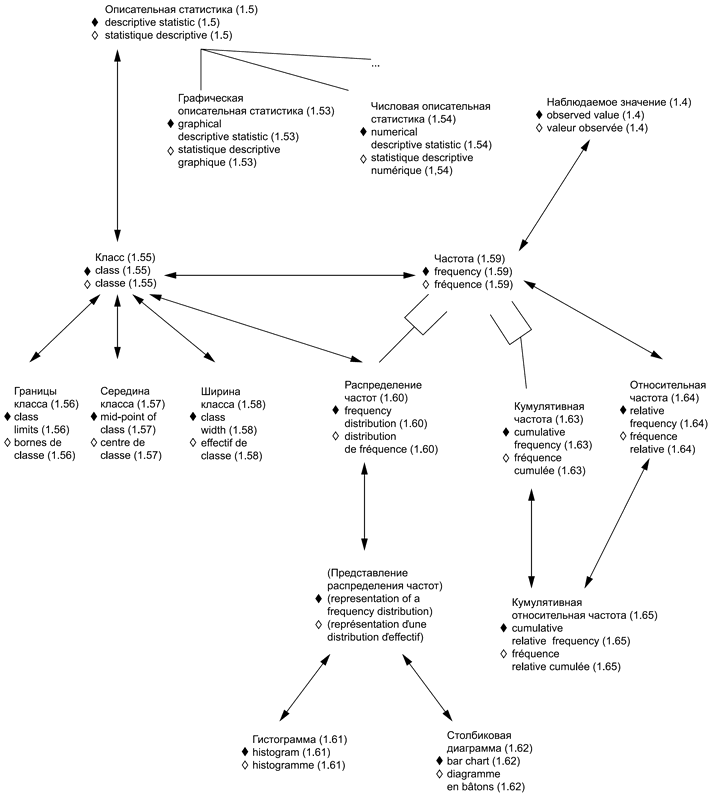
Рисунок В.5 - Понятия, связанные с классами и эмпирическими распределениями
|
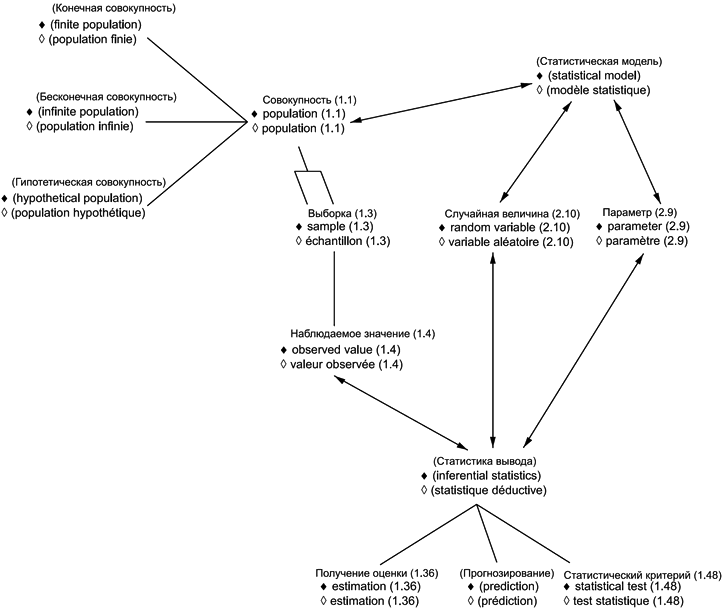
Рисунок В.6 - Понятия, связанные со статистическим выводом
Приложение С
(справочное)
Схемы для терминов, связанных с теорией вероятностей
|
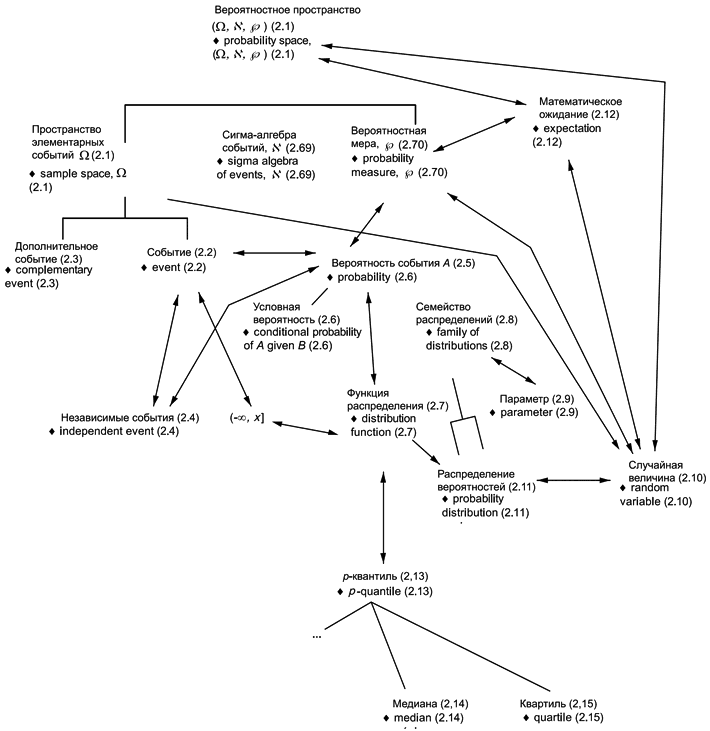
Рисунок С.1 - Основные понятия теории вероятностей
|
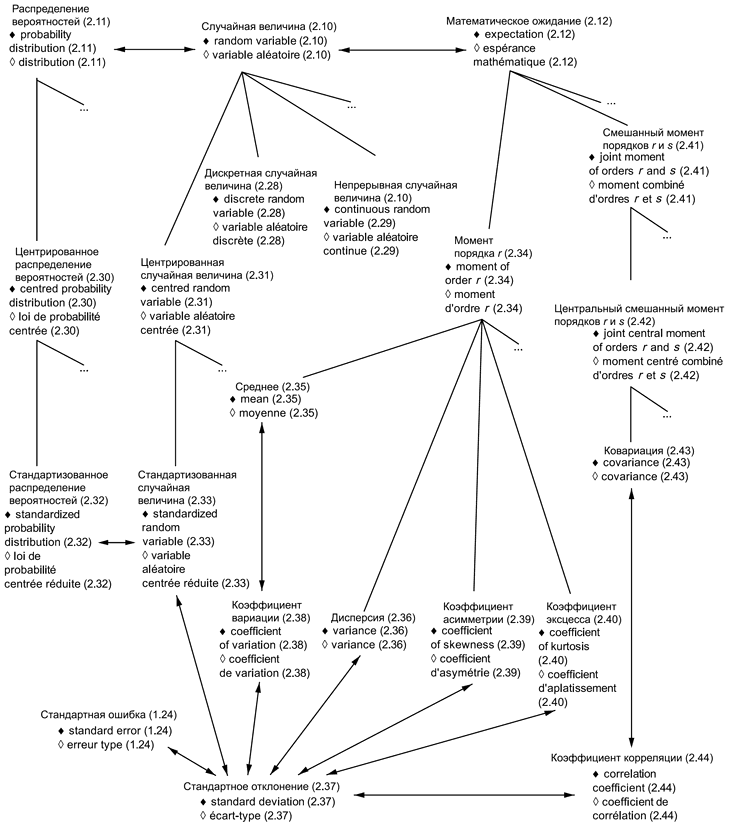
Рисунок С.2 - Основные понятия, связанные с моментами
|
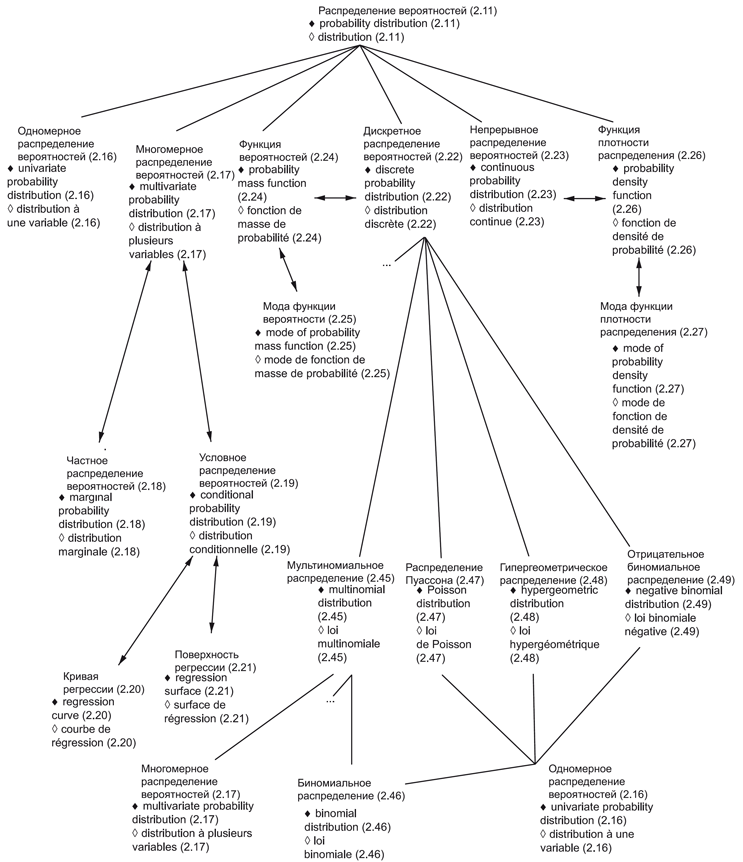
Рисунок С.3 - Понятия, связанные с распределениями вероятностей
|
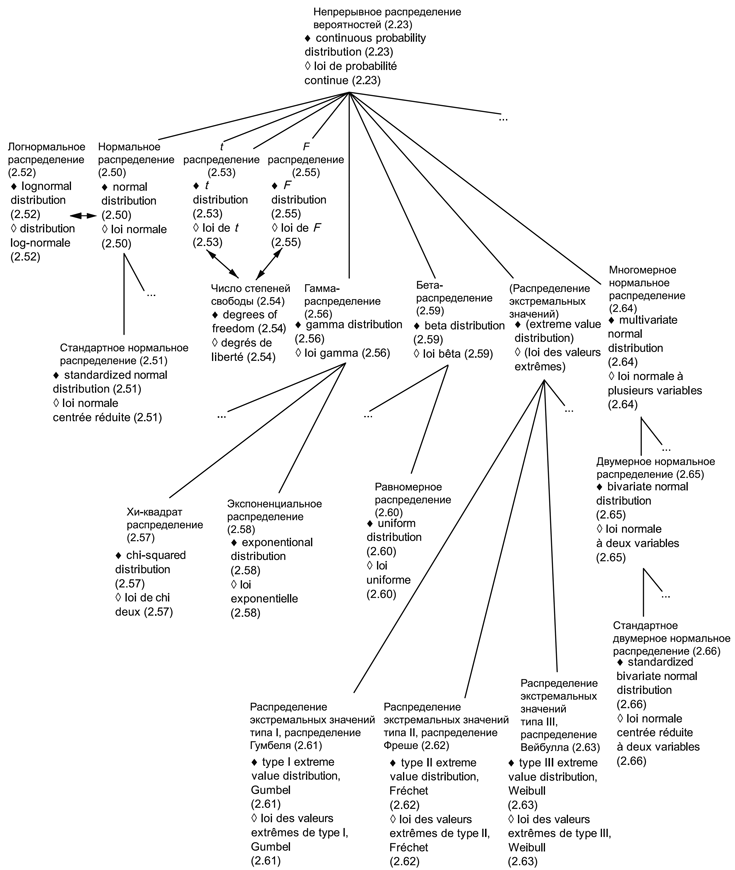
Рисунок С.4 - Понятия, связанные с непрерывными распределениями
Приложение D
(справочное)
Методология разработки словаря
D.1 Введение
Широкое применение стандартов ИСО требует наличия согласованного понятного словаря, доступного потенциальным пользователям стандартов по прикладным статистическим методам.
Анализ связи между понятиями, используемыми в прикладной статистике, создание диаграмм взаимосвязи между понятиями служат предпосылкой согласованности словаря. Данный анализ использован при разработке настоящего стандарта. Так как диаграммы, используемые при разработке, полезны в информативном смысле, они приведены в D.4.
D.2 Содержание словарных статей и правило подстановки
Понятие образует мультиязыковый модуль. На каждом языке выбран наиболее подходящий термин, делающий определение, представленное на данном языке, доступным для понимания, в связи с чем подход к переводу терминов не является буквальным переводом.
Определения сформированы с учетом только тех характеристик, которые составляют суть понятия. Важная информация, не составляющая суть определения, приведена в примечаниях к определению.
Словарь разработан с учетом того, что в случае замены понятия его определением с минимальным изменением синтаксиса не должен быть изменен смысл текста. Данная замена представляет собой простой метод проверки определений. Однако если определение является сложным в том смысле, что оно содержит в себе несколько понятий, такую подстановку лучше производить для одного или максимум для двух понятий одновременно. Полная замена всех понятий их определениями порождает синтаксические сложности и бесполезна в плане передачи смысла текста.
D.3 Взаимосвязь понятий и ее графическое представление
D.3.1 Общие положения
Терминологически словарь построен таким образом, что соотношения между понятиями основаны на иерархическом формировании характеристик некоторого класса, т.е. краткое описание понятия формируется путем наименования его класса и описания характеристик, отличающих его от родительских понятий или понятий того же уровня.
В данном приложении отражены три основные формы взаимосвязи понятий: общие (D.3.2), разделительные (D.3.3) и ассоциативные (D.3.4).
D.3.2 Общая взаимосвязь
В иерархии понятий подчиненные понятия наследуют все характеристики понятий более высокого уровня и содержат описание данных характеристик вместе с их отличиями от родительских понятий и понятий того же уровня, что и они сами, например соотношение между понятиями "весна", "лето", "осень", "зима" и "время года".
Общая взаимосвязь отображена с помощью "веера" или "дерева" без стрелок (см. рисунок D.1).
|
Рисунок D.1 - Графическое представление общей взаимосвязи
D.3.3 Разделительная взаимосвязь
В иерархии понятий подчиненные понятия являются составными частями понятия более высокого уровня, например: весна, лето, осень и зима могут быть составными частями понятия "год". В сопоставлении неуместно определять солнечную погоду (одну из возможных характеристик лета) как часть года.
Разделительные взаимосвязи отображают прямыми вертикальными линиями ("граблями") без стрелок (см. рисунок D.2). Единственную часть отображают с помощью одной линии, множественные - с помощью двойной линии.
|
Рисунок D.2 - Графическое представление разделительной взаимосвязи
D.3.4 Ассоциативная взаимосвязь
Ассоциативная взаимосвязь не дает возможности сократить описание, что обеспечивают общая и разделительная взаимосвязи, однако ассоциативная взаимосвязь полезна при определении природы отношений между системой понятий, например: причина и следствие, деятельность и расположение, деятельность и результат, инструмент и функция, материал и продукт.
Ассоциативную взаимосвязь отображают линией со стрелками на каждом конце (см. рисунок D.3).
|

Рисунок D.3 - Графическое представление ассоциативной взаимосвязи
D.4 Понятийные схемы
На рисунках В.1-В.5 представлены схемы, на основе которых построен раздел 1. На рисунке В.6 приведена дополнительная схема, отображающая взаимоотношение некоторых понятий, присутствующих ранее на рисунках В.1-В.5. На рисунках С.1-С.4 представлены схемы, на основе которых построен раздел 2. Некоторые термины присутствуют более чем в одной диаграмме, таким образом связывая схемы, как указано ниже.
Рисунок В.1 - Основные понятия, связанные с выборкой и генеральной совокупностью | |
Описательная статистика (1.5) | Рисунок В.5 |
Простая случайная выборка (1.7) | Рисунок В.2 |
Оценка (1.12) | Рисунок В.3 |
Статистика критерия (1.52) | Рисунок В.4 |
Случайная величина (2.10) | Рисунки С.1, С.2 |
Функция распределения (2.7) | Рисунок С.1 |
Рисунок В.2 - Основные понятия, связанные с выборочными моментами | |
Простая случайная выборка (1.7) | Рисунок В.1 |
Рисунок В.3 - Понятия, связанные с определением оценок | |
Оценка (1.12) | Рисунок В.1 |
Параметр (2.9) | Рисунок С.1 |
Семейство распределений (2.8) | Рисунки В.4, С.1 |
Функция плотности распределения (2.26) | Рисунок С.3 |
Функция распределения (2.24) | Рисунок С.3 |
Рисунок В.4 - Понятия, связанные со статистическими критериями | |
Статистика критерия (1.52) | Рисунок В.1 |
Функция плотности распределения (2.26) | Рисунки В.3, С.3 |
Функция вероятности (2.24) | Рисунки В.3, С.3 |
Семейство распределений (2.8) | Рисунки В.3, С.3 |
Рисунок В.5 - Понятия, связанные с классами и эмпирическими распределениями | |
Описательная статистика (1.5) | Рисунок В.1 |
Рисунок В.6 - Понятия, связанные со статистическим выводом | |
Совокупность (генеральная) | Рисунок В.1 |
Выборка (1.3) | Рисунок В.1 |
Наблюдаемое значение (1.4) | Рисунки В.1, В.5 |
Определение оценки (1.36) | Рисунок В.3 |
Статистический критерий (1.48) | Рисунок В.4 |
Параметр (2.9) | Рисунки В.3, С.1 |
Случайная величина (2.10) | Рисунки В.1, С.1, С.2 |
Рисунок С.1 - Основные понятия теории вероятностей | |
Случайная величина (2.10) | Рисунки В.1, С.2 |
Распределение вероятностей (2.11) | Рисунки С.2, С.3 |
Семейство распределений (2.8) | Рисунки В.3, В.4 |
Функция распределения (2.7) | Рисунок В.1 |
Параметр (2.9) | Рисунок В.3 |
Рисунок С.2 - Основные понятия, связанные с моментами | |
Случайная величина (2.10) | Рисунки В.1, С.1 |
Распределение вероятностей (2.11) | Рисунки С.1, С.3 |
Рисунок С.3 - Понятия, связанные с распределениями вероятностей | |
Распределение вероятностей (2.11) | Рисунки С.1, С.2 |
Функция распределения (2.24) | Рисунки В.3, В.4 |
Непрерывное распределение (2.23) | Рисунок С.4 |
Одномерное распределение (2.16) | Рисунок С.4 |
Многомерное распределение (2.17) | Рисунок С.4 |
Рисунок С.4 - Понятия, связанные с непрерывными распределениями | |
Одномерное распределение (2.16) | Рисунок С.3 |
Многомерное распределение (2.17) | Рисунок С.3 |
Непрерывное распределение (2.23) | Рисунок С.3 |
Представленные на рисунке С.4 распределения: нормальное -распределение,
-распределение, стандартное нормальное, гамма-, бета-, хи-квадрат-распределение, экспоненциальное, равномерное, экстремальных значений I типа, экстремальных значений II типа, экстремальных значений III типа распределения являются примерами одномерных распределений. Многомерное нормальное, двумерное нормальное и стандартное двумерное нормальное - примеры многомерных распределений. Включение одномерного распределения (2.16) и многомерного распределения (2.17) чрезмерно загромождает рисунок.
Алфавитный указатель терминов на русском языке
бета-распределение | 2.59 |
величина случайная | 2.10 |
величина случайная дискретная | 2.28 |
величина случайная непрерывная | 2.29 |
величина случайная стандартизованная | 2.33 |
величина случайная стандартизованная выборочная | 1.19 |
величина случайная центрированная | 2.31 |
вероятность события A | 2.5 |
вероятность условная | 2.6 |
выборка | 1.3 |
выборка простая случайная | 1.7 |
выборка случайная | 1.6 |
гамма-распределение | 2.56 |
гипотеза | 1.40 |
гипотеза альтернативная | 1.42 |
гипотеза нулевая | 1.41 |
гипотеза простая | 1.43 |
гипотеза сложная | 1.44 |
гистограмма | 1.61 |
граница толерантная | 1.27 |
границы класса | 1.56 |
диаграмма столбиковая | 1.62 |
дисперсия | 2.36 |
дисперсия выборочная | 1.16 |
единица выборочная | 1.2 |
значение наблюдаемое | 1.4 |
значение оценки | 1.31 |
интервал предикционный | 1.30 |
интервал доверительный | 1.28 |
интервал доверительный односторонний | 1.29 |
интервал толерантный | 1.26 |
квантиль уровня | 2.13 |
квартиль | 2.15 |
классы | 1.55 |
ковариация | 2.43 |
ковариация выборочная | 1.22 |
коэффициент асимметрии | 2.39 |
коэффициент асимметрии выборочный | 1.20 |
коэффициент вариации | 2.38 |
коэффициент вариации выборочный | 1.18 |
коэффициент корреляции | 2.44 |
коэффициент корреляции выборочный | 1.23 |
коэффициент эксцесса выборочный | 1.21 |
коэффициент эксцесса | 2.40 |
кривая мощности | 1.51 |
кривая регрессии | 2.20 |
критерий значимости | 1.48 |
критерий статистический | 1.48 |
медиана | 2.14 |
медиана выборочная | 1.13 |
мера вероятностная | 2.70 |
мода функции вероятности | 2.25 |
мода функции плотности распределения | 2.27 |
момент выборочный порядка k | 1.14 |
момент порядка r | 2.34 |
момент порядка | 2.35.1 |
момент порядков r и s смешанный | 2.41 |
момент порядков r и s смешанный центральный | 2.42 |
мощность критерия | 1.50 |
ожидание математическое | 2.12 |
определение оценки | 1.36 |
определение оценки максимального правдоподобия | 1.37 |
отклонение стандартное выборочное | 1.17 |
оценка | 1.12 |
оценка интервальная | 1.25 |
оценка максимального правдоподобия | 1.35 |
оценка несмещенная | 1.34 |
ошибка второго рода | 1.47 |
ошибка оценивания | 1.32 |
ошибка первого рода | 1.46 |
ошибка стандартная | 1.24 |
параметр | 2.9 |
поверхность регрессии | 2.21 |
пределы класса | 1.56 |
пространство вероятностное | 2.68 |
пространство элементарных событий | 2.1 |
равномерное распределение | 2.60 |
размах выборочный | 1.10 |
распределение (вероятностей) | 2.11 |
распределение (вероятностей) дискретное | 2.22 |
распределение (вероятностей) непрерывное | 2.23 |
распределение (вероятностей) одномерное | 2.16 |
распределение прямоугольное | 2.60 |
распределение (вероятностей) условное | 2.19 |
распределение (вероятностей) частное | 2.18 |
распределение биномиальное | 2.46 |
распределение Вейбулла | 2.63 |
распределение выборочное | 2.67 |
распределение Гаусса | 2.50 |
распределение Гаусса стандартное | 2.51 |
распределение гипергеометрическое | 2.48 |
распределение Гумбеля | 2.61 |
распределение логнормальное | 2.52 |
распределение мультиномиальное | 2.45 |
распределение нормальное | 2.50 |
распределение нормальное двумерное | 2.65 |
распределение нормальное двумерное стандартное | 2.66 |
распределение нормальное многомерное | 2.64 |
распределение нормальное стандартное | 2.51 |
распределение отрицательное биномиальное | 2.49 |
распределение полиномиальное | 2.45 |
распределение Пуассона | 2.47 |
распределение стандартизованное | 2.32 |
распределение Стьюдента | 2.53 |
распределение Фреше | 2.62 |
распределение центрированное | 2.30 |
распределение частот | 1.60 |
распределение экспоненциальное | 2.58 |
распределение экстремальных значений типа I | 2.61 |
распределение экстремальных значений типа II | 2.62 |
распределение экстремальных значений типа III | 2.63 |
семейство распределений | 2.8 |
середина класса | 1.57 |
середина размаха | 1.11 |
сигма-алгебра событий | 2.69 |
сигма-поле | 2.69 |
смещение | 1.33 |
событие | 2.2 |
событие дополнительное | 2.3 |
события независимые | 2.4 |
совокупность | 1.1 |
совокупность генеральная | 1.1 |
среднее | 2.35, 2.35.1, 2.35.2 |
среднее арифметическое | 1.15 |
среднее выборочное | 1.15 |
стандартное отклонение | 2.37 |
статистика | 1.8 |
статистика критерия | 1.52 |
статистика описательная | 1.5 |
статистика описательная графическая | 1.53 |
статистика описательная числовая | 1.54 |
статистика порядковая | 1.9 |
уровень значимости | 1.45 |
фрактиль уровня | 2.13 |
функция вероятности | 2.24 |
функция плотности распределения | 2.26 |
функция правдоподобия | 1.38 |
функция правдоподобия профиля | 1.39 |
функция распределения | 2.7 |
функция распределения вероятностей | 2.26 |
функция распределения (случайной величины X) | 2.7 |
характеристика количественная | 1.56 |
хи-квадрат-распределение | 2.57 |
частота | 1.59 |
частота кумулятивная | 1.63 |
частота относительная кумулятивная | 1.65 |
частота относительная | 1.64 |
число степеней свободы | 2.54 |
ширина класса | 1.58 |
| 2.57 |
F-распределение | 2.55 |
p-значение | 1.49 |
| 2.34 |
| 2.69 |
| 2.69 |
| 2.53 |
Алфавитный указатель эквивалентов терминов на английском языке
| 2.57 |
| 2.69 |
| 2.69 |
alternative hypothesis | 1.42 |
arithmetic mean | 1.15 |
average | 1.15 |
bar chart | 1.62 |
beta distribution | 2.59 |
bias | 1.33 |
binomial distribution | 2.46 |
bivariate normal distribution | 2.65 |
centred probability distribution | 2.30 |
centred random variable | 2.31 |
chi-squared distribution | 2.57 |
class | 1.55.1, 1.55.2, 1.55.3 |
class boundaries | 1.56 |
class limits | 1.56 |
class width | 1.58 |
classes | 1.55 |
coefficient of kurtosis | 2.40 |
coefficient of skewness | 2.39 |
coefficient of variation | 2.38 |
complementary event | 2.3 |
composite hypothesis | 1.44 |
conditional distribution | 2.19 |
conditional probability | 2.6 |
conditional probability distribution | 2.19 |
onfidence interval | 1.28 |
continuous distribution | 2.23 |
continuous probability distribution | 2.23 |
continuous random variable | 2.29 |
correlation coefficient | 2.44 |
covariance | 2.43 |
cumulative frequency | 1.63 |
cumulative relative frequency | 1.65 |
degrees of freedom | 2.54 |
descriptive statistics | 1.5 |
discrete distribution | 2.22 |
discrete probability distribution | 2.22 |
discrete random variable | 2.28 |
distribution | 2.11 |
distribution function of a random variable | 2.7 |
error of estimation | 1.32 |
estimate | 1.31 |
estimation | 1.36 |
estimator | 1.12 |
event | 2.2 |
expectation | 2.12 |
exponential distribution | 2.58 |
| 2.55 |
family of distributions | 2.8 |
Frechet distribution | 2.62 |
frequency | 1.59 |
frequency distribution | 1.60 |
gamma distribution | 2.56 |
Gaussian distribution | 2.50 |
graphical descriptive statistics | 1.53 |
Gumbel distribution | 2.61 |
histogram | 1.61 |
hypergeometric distribution | 2.48 |
hypothesis | 1.40 |
independent events | 2.4 |
interval estimator | 1.25 |
joint central moment of orders | 2.42 |
joint moment of orders | 2.41 |
likelihood function | 1.38 |
lognormal distribution | 2.52 |
marginal distribution | 2.18 |
marginal probability distribution | 2.18 |
maximum likelihood estimation | 1.37 |
maximum likelihood estimator | 1.35 |
mean | 1.15, 2.35.1, 2.35.2 |
median | 2.14 |
mid-point of class | 1.57 |
mid-range | 1.11 |
mode of probability density function | 2.27 |
mode of probability mass function | 2.25 |
moment of order | 2.34 |
moment of order | 2.35.1 |
multinomial distribution | 2.45 |
multivariate distribution | 2.17 |
multivariate normal distribution | 2.64 |
multivariate probability distribution | 2.17 |
negative binomial distribution | 2.49 |
normal distribution | 2.50 |
null hypothesis | 1.41 |
numerical descriptive statistics | 1.54 |
observed value | 1.4 |
one-sided confidence interval | 1.29 |
order statistic | 1.9 |
parameter | 2.9 |
| 2.13 |
Poisson distribution | 2.47 |
population | 1.1 |
power curve | 1.51 |
power of a test | 1.50 |
p-quantile | 2.13 |
prediction interval | 1.30 |
probability density function | 2.26 |
probability distribution | 2.11 |
probability mass function | 2.24 |
probability measure | 2.70 |
probability of an event | 2.5 |
probability space | 2.68 |
profile likelihood function | 1.39 |
| 1.49 |
quartile | 2.15 |
random sample | 1.6 |
random variable | 2.10 |
rectangular distribution | 2.60 |
regression curve | 2.20 |
regression surface | 2.21 |
relative frequency | 1.64 |
rth moment | 2.34 |
sample | 1.3 |
sample coefficient of kurtosis | 1.21 |
sample coefficient of skewness | 1.20 |
sample coefficient of variation | 1.18 |
sample correlation coefficient | 1.23 |
sample covariance | 1.22 |
sample mean | 1.15 |
sample median | 1.13 |
sample moment of order | 1.14 |
sample range | 1.10 |
sample space | 2.1 |
sample standard deviation | 1.17 |
sample variance | 1.16 |
sampling distribution | 2.67 |
sampling unit | 1.2 |
sigma algebra of events | 2.69 |
sigma field | 2.69 |
significance level | 1.45 |
significance test | 1.48 |
simple hypothesis | 1.43 |
simple random sample | 1.7 |
standard deviation | 2.37 |
standard error | 1.24 |
standardized bivariate normal distribution | 2.66 |
standardized Gaussian distribution | 2.51 |
standardized normal distribution | 2.51 |
standardized probability distribution | 2.32 |
standardized random variable | 2.33 |
standardized sample random variable | 1.19 |
statistic | 1.8 |
statistical test | 1.48 |
statistical tolerance interval | 1.26 |
statistical tolerance limit | 1.27 |
Student's distribution | 2.53 |
| 2.53 |
test statistic | 1.52 |
Type I error | 1.46 |
type I extreme value distribution | 2.61 |
Type II error | 1.47 |
type II extreme value distribution | 2.62 |
type III extreme value distribution | 2.63 |
unbiased estimator | 1.34 |
uniform distribution | 2.60 |
univariate distribution | 2.16 |
univariate probability distribution | 2.16 |
variance | 2.36 |
Weibull distribution | 2.63 |
Алфавитный указатель эквивалентов терминов на французском языке
| 2.57 |
| 2.69 |
| 2.69 |
| 2.69 |
biais | 1.33 |
bornes de classe | 1.56 |
centre de classe | 1.57 |
champ sigma | 2.69 |
classe | 1.55.1, 1.55.2, 1.55.3 |
classes | 1.55 |
coefficient d'aplatissement | 2.40 |
coefficient d'aplatissement d'echantillon | 1.21 |
coefficient d'asymetrie | 2.39 |
coefficient d'asymetrie d'echantillon | 1.20 |
coefficient de correlation | 2.44 |
coefficient de correlation d'echantillon | 1.23 |
coefficient de variation | 2.38 |
coefficient de variation d'echantillon | 1.18 |
courbe de puissance | 1.51 |
courbe de regression | 2.20 |
covariance | 2.43 |
covariance d'echantillon | 1.22 |
degres de liberte | 2.54 |
diagramme en batons | 1.62 |
distribution | 2.11 |
distribution a plusieurs variables | 2.17 |
distribution a une variable | 2.16 |
distribution conditionnelle | 2.19 |
distribution continue | 2.23 |
distribution de frequence | 1.60 |
distribution d'echantillonnage | 2.67 |
distribution discrete | 2.22 |
distribution log-normale | 2.52 |
distribution marginale | 2.18 |
distribution | 2.53 |
ecart-type | 2.37 |
ecart-type d'echantillon | 1.17 |
echantillon | 1.3 |
echantillon aleatoire | 1.6 |
echantillon simple aleatoire | 1.7 |
effectif de la classe | 1.58 |
erreur de premiere espece | 1.46 |
erreur de seconde espece | 1.47 |
erreur d'estimation | 1.32 |
erreur type | 1.24 |
espace de probabilite | 2.68 |
espace d'echantillon | 1.65 |
esperance mathematique | 2.12 |
estimateur | 1.12 |
estimateur du maximum de vraisemblance | 1.35 |
estimateur par intervalle | 1.25 |
estimateur sans biais | 1.34 |
estimation (operation) | 1.36 |
estimation (resultat) | 1.31 |
estimation du maximum de vraisemblance | 1.37 |
etendue d'echantillon | 1.10 |
evenement | 2.2 |
evenement complementaire | 2.3 |
evenements independents | 2.4 |
famille de distributions | 2.8 |
fonction de densite de probabilite | 2.26 |
fonction de masse de probabilite | 2.24 |
fonction de repartition d'une variable aleatoire | 2.7 |
fonction de vraisemblance | 1.38 |
fonction de vraisemblance partielle | 1.39 |
fractile d'ordre | 2.13 |
frequence | 1.59 |
frequence cumulee | 163* |
________________ * Текст документа соответствует оригиналу. - . | |
frequence relative | 1.64 |
frequence relative cumulee | 1.65 |
frontieres de classe | 1.56 |
histogramme | 1.61 |
hypothese | 1.40 |
hypothese alternative | 1.42 |
hypothese composite | 1.44 |
hypothese nulle | 1.41 |
hypothese simple | 1.43 |
intervalle de confiance | 1.28 |
intervalle de confiance unilateral | 1.29i* |
________________ * Текст документа соответствует оригиналу. - . | |
intervalle de prediction | 1.30 |
intervalle statistique de dispersion | 1.26 |
limite statistique de dispersion | 1.27 |
loi beta | 2.59 |
loi binomial | 2.46 |
loi binomiale negative | 2.49 |
loi de chi deux | 2.57 |
loi de | 2.55 |
loi de Fisher-Snedecor | 2.55 |
loi de Frechet | 2.62 |
loi de Gauss | 2.50 |
loi de Gauss centree reduite | 2.51 |
loi de Gumbel | 2.61 |
loi de Poisson | 2.47 |
loi de probabilite | 2.11 |
loi de probabilite a plusieurs variables | 2.17 |
loi de probabilite a une variable | 2.16 |
loi de probabilite centree | 2.30 |
loi de probabilite centree reduite | 2.32 |
loi de probabilite conditionnelle | 2.19 |
loi de probabilite continue | 2.23 |
loi de probabilite discrete | 2.22 |
loi de probabilite marginale | 2.18 |
loi de Student | 2.53 |
loi de Weibull | 2.63 |
loi des valeurs extremes de type | 2.61 |
loi des valeurs extremes de type | 2.62 |
loi des valeurs extremes de type | 2.63 |
loi exponentlelle | 2.58 |
loi gamma | 2.56 |
loi hypergeometrique | 2.48 |
loi multinomiale | 2.45 |
loi normale | 2.50 |
loi normale a deux variables | 2.65 |
loi normale a plusieurs variables | 2.64 |
loi normale centree reduite | 2.51 |
loi normale centree reduite a deux variables | 2.66 |
loi rectangulaire | 2.60 |
oi uniforme | 2.60 |
mediane | 2.14 |
mediane d'echantillon | 1.13 |
mesure de probability | 2.70 |
milieu de I'etendue | 1.11 |
mode de fonction de densite de probability | 2.27 |
mode de fonction de masse de probabilite | 2.25 |
moment centre combine d'ordres | 42 |
moment combine d'ordres | 2.41 |
moment d'echantillon d'ordre it | 1.14 |
moment d'ordre | 2.34 |
moment d'ordre | 2.35.1 |
moyenne | 1.15, 2.35.1, 2.35.2, 1.15 |
moyenne arithmetique | 1.15 |
moyenne d'echantillon | 1.15 |
niveau de significatiniveau de signification | 1.45 |
parameter | 2.9 |
population | 1.1 |
probabilite conditionnelle | 2.6 |
probabilite d'un evenement | 2.5 |
puissance d'un test | 1.50 |
quantile d'ordre | 2.13 |
quartile | 2.15 |
sigma-algebre des evenements | 2.69 |
statistique | 1.8 |
statistique de test | 1.52 |
statistique descriptive | 1.5 |
statistique descriptive graphique | 1.53 |
statistique descriptive numerique | 1.54 |
statistique d'ordre | 1.9 |
surface de regression | 2.21 |
test de signification | 1.48 |
test statistique | 1.48 |
tribu | 2.69 |
unite d'echantillonnage | 1.2 |
valeur observe | 1.4 |
valeur | 1.49 |
variable aleatoire | 2.10 |
variable aleatoire centree | 2.31 |
variable aleatoire centree reduite | 2.33 |
variable aleatoire centree reduite d'echantillon | 1.19 |
variable aleatoire continue | 2.29 |
variable aleatoire discrete | 2.28 |
variance | 2.36 |
variance d'echantillon | 1.16 |
Библиография
[1] | ISO 31-11:1992, Quantities and units - Part 11: Mathematical signs and symbols for use in the physical sciences and technology |
[2] | ISO 3534-2:2006, Statistics - Vocabulary and symbols - Part 2: Applied statistics |
[3] | ISO 5725 (all parts), Accuracy (trueness and precision) of measurement methods and results |
[4] | VIM:1993, International vocabulary of basic and general terms in metrology, BIPM, IEC, IFCC, ISO, OIML, IUPAC, IUPAP |
УДК 658.562.012.7:65.012.122:006.354 | ОКС 01.040.03; 03.120.30 |
Ключевые слова: статистика, теория вероятностей | |
Электронный текст документа
и сверен по:
, 2019

{kind=link}