ГОСТ ISO 8587-2015
МЕЖГОСУДАРСТВЕННЫЙ СТАНДАРТ
Органолептический анализ
МЕТОДОЛОГИЯ
Ранжирование
Organoleptic analysis. Methodology. Ranking
МКС 67.050
67.240
Дата введения 2017-07-01
Предисловие
Цели, основные принципы и основной порядок проведения работ по межгосударственной стандартизации установлены ГОСТ 1.0-2015 "Межгосударственная система стандартизации. Основные положения" и ГОСТ 1.2-2015 "Межгосударственная система стандартизации. Стандарты межгосударственные, правила и рекомендации по межгосударственной стандартизации. Правила разработки, принятия, обновления и отмены"
Сведения о стандарте
1 ПОДГОТОВЛЕН Республиканским унитарным предприятием "Научно-практический центр Национальной академии наук Беларуси по продовольствию" на основе собственного перевода на русский язык англоязычной версии стандарта, указанного в пункте 5
2 ВНЕСЕН Государственным комитетом по стандартизации Республики Беларусь
3 ПРИНЯТ Межгосударственным советом по стандартизации, метрологии и сертификации по переписке (протокол от 27 февраля 2015 г. N 75-П)
За принятие проголосовали:
Краткое наименование страны по МК (ИСО 3166) 004-97 | Код страны по | Сокращенное наименование национального органа по стандартизации |
Армения | AM | Минэкономики Республики Армения |
Беларусь | BY | Госстандарт Республики Беларусь |
Казахстан | KZ | Госстандарт Республики Казахстан |
Киргизия | KG | Кыргызстандарт |
Молдова | MD | Молдова-Стандарт |
Россия | RU | Росстандарт |
Таджикистан | TJ | Таджикстандарт |
Узбекистан | UZ | Узстандарт |
4 Приказом Федерального агентства по техническому регулированию и метрологии от 28 июля 2016 г. N 892-ст межгосударственный стандарт ГОСТ ISO 8587-2015 введен в действие в качестве национального стандарта Российской Федерации с 1 июля 2017 г.
5 Настоящий стандарт идентичен международному стандарту ISO 8587:2006* "Сенсорный анализ. Методология. Ранжирование" ("Sensory analysis - Methodology - Ranking", IDT).
________________
* Доступ к международным и зарубежным документам, упомянутым в тексте, можно получить, обратившись в Службу поддержки пользователей. - .
Международный стандарт разработан подкомитетом SC 12 "Сенсорный анализ" Технического комитета по стандартизации ТС 34 "Пищевые продукты" Международной организации по стандартизации (ISO).
Наименование настоящего стандарта изменено относительно наименования указанного международного стандарта для приведения в соответствие с принятой в Российской Федерации терминологией и требованиями ГОСТ 1.5 (подраздел 3.6).
При применении настоящего стандарта рекомендуется вместо ссылочных международных стандартов использовать соответствующие им межгосударственные стандарты, сведения о которых приведены в дополнительном приложении ДА.
6 ВВЕДЕН ВПЕРВЫЕ
Информация об изменениях к настоящему стандарту публикуется в ежегодном по состоянию на 1 января текущего года информационном указателе "Национальные стандарты", а текст изменений и поправок - в ежемесячном информационном указателе "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ежемесячном информационном указателе "Национальные стандарты". Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет ()
ВНЕСЕНА поправка, опубликованная на официальном сайте Росстандарта России rst.gov.ru по состоянию на 09.07.2024
Поправка внесена изготовителем базы данных
1 Область применения
Настоящий стандарт устанавливает метод органолептической оценки с целью расположения ряда образцов для тестирования в упорядоченной последовательности.
Настоящий метод позволяет оценивать различия среди нескольких образцов на основе интенсивности одного, нескольких свойств или общего ощущения. Его используют для установления факта существования различий, но при его применении нельзя определить степень различия между образцами.
________________
В данном случае каждое свойство проверяют путем различных тестов, в которых одни и те же продукты имеют разные коды и их представляют в различном порядке одному и тому же дегустатору.
Метод применяют в следующих случаях:
a) оценка работы дегустаторов
1) обучение дегустаторов;
2) установление порога органолептических ощущений индивидуумов или групп;
b) оценка качества продукта
1) предварительная сортировка образцов
i) по описательному критерию;
ii) по гедоническому предпочтению (т.е. полученному удовольствию);
2) определение влияния уровней интенсивности одного или нескольких параметров (например, порядок разбавления, влияние исходных материалов и условий производства, упаковка или способы хранения)
i) по описательному критерию;
ii) по гедоническому предпочтению;
3) установление порядка предпочтения при проведении общего гедонического теста.
2 Нормативные ссылки
Нижеприведенные международные стандарты являются обязательными при применении настоящего стандарта*. В случае недатированных ссылок применяют последнее издание ссылочного стандарта (с учетом всех его изменений).
________________
* Таблицу соответствия национальных стандартов международным см. по ссылке. - .
ISO 3534-1 Statistics. Vocabulary and symbols. Part 1: General statistical terms and terms used in probability (Статистика. Словарь и условные обозначения. Часть 1. Общие статистические термины и термины, используемые в теории вероятности);
ISO 5492 Sensory analysis - Vocabulary (Органолептический анализ. Словарь);
ISO 6658 Sensory analysis - Methodology - General guidance (Сенсорный анализ. Методология. Общее руководство);
ISO 8586-1 Sensory analysis - General guidance for the selection, training and monitoring of assessors - Part 1: Selected assessors (Сенсорный анализ. Общее руководство по отбору, обучению и контролю испытателей. Часть 1. Отобранные испытатели);
________________
В настоящее время действует ISO 8586:2012 "Сенсорный анализ. Общие руководящие указания по отбору, обучению и контролю за работой отобранных испытателей и экспертов-испытателей в области сенсорного анализа".
ISO 8586-2 Sensory analysis - General guidance for the selection, training and monitoring of assessors - Part 2: Experts (Сенсорный анализ. Общее руководство по отбору, обучению и контролю испытателей. Часть 2. Эксперты);
________________
В настоящее время действует ISO 8586:2012 "Сенсорный анализ. Общие руководящие указания по отбору, обучению и контролю за работой отобранных испытателей и экспертов-испытателей в области сенсорного анализа".
ISO 8589 Sensory analysis - General guidance for the design of test rooms (Органолептический анализ. Общее руководство по проектированию помещений для испытаний);
ISO 11035 Sensory analysis - Identification and selection of descriptors for establishing a sensory profile by a multidimensional approach (Органолептический анализ. Идентификация и выбор дескрипторов для установления органолептического профиля при многостороннем подходе);
ISO 11036 Sensory analysis - Methodology - Texture profile (Органолептический анализ. Методология. Характеристики структуры).
3 Термины и определения
В настоящем стандарте применены термины, приведенные в ISO 3534-1 и ISO 5492.
4 Сущность метода
Дегустаторы получают одновременно три или больше образцов в произвольном порядке.
Примечание - Можно расположить в ряд два образца методом парного сравнения, описание которого приведено в [1], является обычно предпочтительным.
Дегустаторов просят расположить в ряд образцы по заданному критерию, безразмерному критерию (т.е. особому свойству или специфической характеристике атрибута) или глобальной интенсивности (например, общему ощущению).
Устанавливаются ранговые суммы и проводятся статистические сравнения.
5 Общие условия тестирования
При отборе образцов руководствуются ISO 6658. Для проведения испытаний используют оборудование и помещение, соответствующее требованиям ISO 8589.
При подготовке образцов необходимо принимать во внимание следующие важные вопросы:
a) приготовление, кодирование и презентацию образцов для тестирования;
b) число образцов для надежного сравнения [которое должно устанавливаться на основе особенностей испытываемого продукта (эффектов насыщения чувствительности)] и выбранного дизайна; число образцов должно быть адаптировано на основе следующего:
1) типа продукта [например, до 15 образцов может быть протестировано отобранными дегустаторами (ISO 8586-1) или экспертами (ISO 8586-2) на мягких образцах, в то время как три образца могут представлять действительный максимум для продуктов твердой консистенции, острого вкуса и очень жирных продуктов по оценкам потребителей], и
2) критерия, подлежащего оценке (например, сладкий вкус менее насыщенный, чем горький)
c) возможную подсветку образцов.
6 Дегустаторы
6.1 Квалификация
Квалификация дегустаторов зависит от цели теста (см. приложение А).
Все дегустаторы должны иметь одинаковый уровень квалификации, при этом уровень выбирают в соответствии с целью теста:
a) отобранные дегустаторы или эксперты:
1) для практических занятий с дегустаторами,
2) оценки по описательному критерию для установления, например, влияния уровней интенсивности одного или больше параметров (порядок разбавления, влияние исходных материалов и производства, упаковка или методы хранения),
3) установления порогов восприятия отдельных дегустаторов (экспертов) или групп;
b) неподготовленные дегустаторы или потребители, уже обученные по определенному методу
1) для гедонического предпочтения,
2) в случае предварительной сортировки образцов (чтобы выбрать несколько продуктов из большого количества для подготовительного тестирования).
Условия, которым дегустаторы должны соответствовать, приведены в ISO 6658, ISO 8586-1 и ISO 8586-2. Дегустаторы должны быть специально обучены процедуре ранжирования по используемым отобранным дескрипторам.
6.2 Количество дегустаторов
Количество дегустаторов зависит от цели теста (см. приложение А).
В случае проверки работы дегустаторов, при их обучении или определении порогов восприятия отдельных дегустаторов (экспертов) или групп не требуется минимальное или максимальное количество.
Для описательной оценки продукта минимальное количество дегустаторов определяют по уровням принятых статистических рисков, и оно должно соответствовать требованиям ISO 11035 или ISO 11036, т.е. предпочтительно от 12 до 15 выбранных дегустаторов.
Для установления порядка предпочтения в гедоническом тесте минимальное количество дегустаторов определяют по уровням принятых статистических рисков, например, минимум 60 дегустаторов на группу потребительского типа.
Для статистического анализа результатов при равенстве других обстоятельств (например, условия теста, квалификация дегустаторов) чем больше количество дегустаторов, тем больше вероятность выявления любого систематического различия в ранге среди продуктов.
6.3 Предварительное обсуждение
Дегустаторы должны быть информированы о цели теста, т.е. о ранжировании образцов для тестирования.
При необходимости может быть демонстрация процедуры ранжирования. В этом тесте важно обеспечить понимание всеми дегустаторами проверяемого критерия. Предварительное обсуждение не должно влиять на ожидаемые результаты дегустаторов.
7 Проведение анализа
7.1 Представление образцов
Дегустаторы не должны иметь возможность делать заключение в отношении образцов в зависимости от способа их представления.
Образцы необходимо готовить вне поля зрения дегустаторов одинаковым способом: применяют одинаковую аппаратуру, сосуды, одинаковое количество продуктов, одна и та же температура, одинаковое представление. Все не отвечающие целям теста показатели должны быть исключены, т.е. не рассматриваются при ранжировании. Образцы представляют при температуре, с которой продукт обычно потребляется.
Сосуды кодируют трехзначными числами, выбранными случайным образом и разными от образца к образцу в пределах одной серии анализа (и предпочтительно от одного дегустатора к другому).
Презентация учитывает выбранную модель тестирования. В модели "полного блока" каждый дегустатор располагает все образцы в ряд. Это есть предпочтительная процедура. Но, если количество или особенности образцов делают их ранжирование некорректным, то может быть использована модель "сбалансированного неполного блока". В любом случае необходимо гарантировать, что все дегустаторы завершают свою часть модели и не пропускают какую-либо оценку.
Для моделей сбалансированного неполного блока каждому дегустатору предоставляют специальное подмножество образцов, упорядоченных наугад (см. для примера приложение А).
Примечание - Использование сбалансированного неполного блока возможно только в случае, когда изменение такого блока существует в реальности. Поэтому необходимо искать предопределенный блок в литературе, например, в [5].
Каждому дегустатору дают образцов из
(
). Подмножество к образцов устанавливают таким образом, что за один проход через модель сбалансированного неполного блока каждый образец оценивают
дегустаторы из
(
), а каждую пару образцов оценивают
дегустаторы. Возможно, что необходимо будет повторить оценку всего сбалансированного неполного блока несколько раз, чтобы получить адекватный уровень чувствительности анализа. Число повторов отмечают символом
. В итоге каждый образец оценивают
, а каждую пару образцов -
дегустаторы.
7.2 Контрольные образцы
Допускается использование контрольных образцов. В этом случае их включают в серию как неопознанные.
7.3 Способ тестирования
Все дегустаторы должны работать в одинаковых условиях тестирования.
Дегустаторы оценивают представленные образцы в произвольном порядке и размещают их по рангу на основе назначенного атрибута.
Дегустаторы должны быть предупреждены о том, чтобы они избегали совпадающих рангов. Если дегустатор не может различать два или больше образцов, то необходимо проинструктировать о том, что он должен разместить образы в ранговом порядке, а в форме для ответов (секция комментариев) необходимо указать те образцы, которые не было возможности дифференцировать.
________________
Совпадающие ранги (идентичные ранги) следует избегать и использовать только в случае, когда дегустаторы реально не имеют возможности проводить различия между образцами.
При отсутствии риска органолептической адаптации и достаточной стабильности продуктов, необходимо инструктировать каждого дегустатора провести начальное предварительное упорядочение, а затем проверить его путем повторной оценки образцов в ранговом порядке.
Единичный атрибут должен оцениваться за один тест. Если необходимо получить информацию о ранжировании больше чем одного атрибута, то каждый атрибут должен оцениваться отдельно.
7.4 Форма для ответов
Пример формы для ответов приведен в приложении D.
Коды образцов не следует первоначально указывать на бланке ответов в случае, если позиции образцов влияют на ожидания дегустаторов в отношении их рангового порядка. Ранги, присвоенные отдельным образцам, дегустаторы должны указать в форме для ответов.
В зависимости от цели теста и образцов для тестирования необходимо регистрировать дополнительную информацию в соответствующей форме для ответов.
8 Обработка результатов
8.1 Сводка результатов и вычисление ранговых сумм
Таблица 1 иллюстрирует ранжирования по одному атрибуту семью дегустаторами для четырех образцов. Если ранжирование выполняется в отношении нескольких атрибутов, то для каждого атрибута требуется отдельная таблица.
Если имеются совпадающие ранги, то необходимо записывать средний ранг образцов, которые считаются идентичными. В таблице 1 дегустатор N 2 присвоил один и тот же ранг образцам B и C. Дегустатор N 3 присвоил одинаковый ранг образцам B, C и D.
Если нет пропущенных данных и правильно вычислены совпадающие ранги, то все ряды будут иметь одинаковую сумму. Ранговую сумму для каждого образца получают путем сложения рангов в каждом столбце. Ранговая сумма показывает последовательность рангов, присвоенных целой группой дегустаторов. Если они согласуются, то ранговые суммы будут очень разными, но если они противоречивые, то ранговые суммы будут подобными.
8.2 Статистический анализ и интерпретация
Выбор статистического анализа зависит от цели теста (см. приложение A).
8.2.1 Определение индивидуальной характеристики: коэффициент корреляции Спиермана
Чтобы проанализировать согласие между двумя ранговыми порядками (например, ранжирования двумя дегустаторами или ранговый порядок дегустатора и расположение в определенном порядке, прогнозируемое на основе информации об образцах), коэффициент корреляции Спиермана, , может быть вычислен по формуле
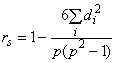 , (1)
, (1)
где - количество упорядоченных продуктов;
- разница меду двумя расстановками для
-го образца.
Если значение коэффициента корреляции Спиермана приближается к +1, то существует соответствие между двумя ранговыми порядками. Если он близок к 0, то ранговые порядки являются несвязанными.
Если значение коэффициента корреляции Спиермана приближается к -1, то существует разногласие между двумя расстановками в определенном порядке. Следует рассмотреть возможность, что дегустатор неправильно интерпретировал инструкции и расположил образцы в порядке, противоположном задуманному.
Критические значения , чтобы устанавливать значимость наблюдаемой корреляции, приведены в таблице 2.
8.2.2 Определение групповой характеристики в случае заранее заданного или подтверждения заранее заданного порядка образцов: тест Пейджа [3]
Этот анализ может быть использован для того, чтобы установить, соглашается ли комиссия дегустаторов или может ли она воспринимать ранговый порядок по некоторому свойству, которое должен иметь набор образцов согласно имеющейся информации или прогнозу.
Если , ....,
являются теоретическими ранговыми суммами
образцов в их предварительно установленном порядке, то нуль-гипотезу отсутствия различий между образцами можно записать как
![]() .
.
Тогда альтернативная гипотеза имеет вид:![]() , где, по меньшей мере, одно из этих неравенств является строгим.
, где, по меньшей мере, одно из этих неравенств является строгим.
Для всех продуктов вычисляют ранговые суммы ...,
(где
есть ранговая сумма для образца, который является первым в известном ранговом порядке, и так далее до
для образца, который является последним в известном порядке).
Чтобы проверить нулевую гипотезу вычисляют коэффициент Пейджа
по формуле
![]() . (2)
. (2)
Этот коэффициент будет самым большим при воспроизведении дегустаторами теоретического ранжирования продуктов.
В случае моделей полного блока сравнивают с критическими значениями (см. таблицу 3), соответствующими количеству дегустаторов, количеству образцов и выбранному риску, для а=0,05 или а=0,01.
- Если меньше значения, указанного в таблице, то не обнаруживаются какие-либо значимые различия между продуктами.
- Если равно или больше значения, указанного в таблице, то имеются значимые различия между ранговыми суммами продуктов.
исключается, а
принимается. Делают заключение, что дегустаторы имеют склонность к ранжированию образцов в предварительно установленном порядке.
Если количество дегустаторов или количество образцов другое, чем в таблице 3, то коэффициент Пейджа вычисляют по формуле
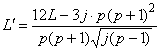 , (3)
, (3)
где - количество дегустаторов;
- количество ранжированных продуктов.
Это количество приблизительно следует стандартному нормальному распределению.
исключается, если
1,64 (с риском 0,05) или
2,33 (с риском 0,01) (см. таблицу 3).
В случае моделей сбалансированного неполного блока вычисляют по формуле
![]() , (4)
, (4)
где - количество продуктов, ранжированных каждым дегустатором;
- суммарное количество ранжированных продуктов.
Снова можно отметить, что это количество следует стандартному нормальному распределению.
исключается, если
>1,64 (с риском 0,05) или
>2,33 (с риском 0,01) (см. таблицу 3).
Так как была принята гипотеза , что все теоретические ранговые суммы являются равными, то значимый результат не свидетельствует о восприятии всех различий образца, а только о том, что в прогнозируемом порядке постоянно воспринималось различие между продуктами, по меньшей мере, в одной паре образцов.
8.2.3 Сравнение продуктов в случае, когда нет предполагаемого порядка
Тест по Фридману (анализ вариантности по рангам, см. [2]) дает максимальные возможности для демонстрации признания дегустаторами различий среди образцов.
8.2.3.1 Тест, если есть различие, по меньшей мере, между двумя продуктами
Этот тест применяют в случае, когда у дегустаторов ранжировали одно и то же продуктов.
Вычисляют ранговые суммы ,
, ...,
образцов с участием
дегустаторов.
Если , ...,
являются теоретическими ранговыми суммами
образцов, то нулевую гипотезу отсутствия различий между образцами можно записать следующим образом
![]() (5)
(5)
Альтернативная гипотеза заключается в том, что ранговые суммы для совокупности не все являются равными.
Для моделей "полного блока" значение теста по Фридману имеет следующий вид
![]() , (6)
, (6)
где - ранговая сумма
-го продукта.
Если ![]() (см. таблицу 4) с учетом количества дегустаторов, количества продуктов и выбранного риска, то
(см. таблицу 4) с учетом количества дегустаторов, количества продуктов и выбранного риска, то исключается. Дают заключение о наличии последовательных различий среди ранговых порядков продуктов.
Для моделей сбалансированного неполного блока уравнение имеет следующий вид
|
где - число повторов основной модели сбалансированного неполного блока;
- число разовых оценок каждого образца в основной модели сбалансированного неполного блока;
- количество образцов для ранжирования каждым дегустатором;
- число разовых оценок каждой пары вместе в основной модели сбалансированного неполного блока.
Если ![]() (см. таблицу 4) с учетом количества дегустаторов, количества продуктов и выбранного риска, то
(см. таблицу 4) с учетом количества дегустаторов, количества продуктов и выбранного риска, то исключается. Делают заключение о наличии последовательных различий среди ранговых порядков продуктов.
Если количество образцов или количество дегустаторов отличается от данных таблицы 4, то критические значения находят путем аппроксимации, которая рассматривает как
со степенями свободы
, где
есть количество продуктов. Критические значения
представлены в таблице 5.
8.2.3.2 Тест, когда одни продукты значимо отличаются от других
Если на основании теста по Фридману сделано заключение, что имеются последовательные различия среди ранговых порядков продуктов, то, чтобы установить, какие продукты являются значимо разными, вычисляют наименее значимое различие [Least Significant Difference (LSD)] при выбранном риске (а=0,05 или а=0,01).
При рассмотрении уровня а (уровень значимости или риск заключения, что имеется различие, когда оно отсутствует) должен быть выбран один из двух следующих подходов:
a) Если уровень риска применяется к каждой паре индивидуально, тогда ассоциируемый риск есть a. Например, если а=0,05 (т.е. риск 5%), тогда при вычислении LSD значение z (соответствующее двухсторонней нормальной вероятности а) составляет 1,96. Он известен как правильное сравнение или индивидуальный риск. Если риск есть для каждой пары, то имеется риск, который намного выше, чем a неправильного определения признака значимого различия в одной или большем числе пар за весь эксперимент в целом.
b) Если риск a применяется к полному эксперименту, тогда риск, который должен ассоциироваться с каждой парой продуктов, есть а', где а'=2а/p(p-1). Например, если p=8 и риск а=0,05, то тогда а'=0,0018 и значение z (соответствующее двухсторонней нормальной вероятности а' ) составляет или равен 2,91. Он известен как правильный эксперимент или глобальный риск.
В большинстве случаев второй подход, правильный экспериментальный риск, является наиболее уместным для практических решений, касающихся продуктов.
Для моделей полного блока
![]() , (8)
, (8)
Для моделей сбалансированного неполного блока
![]() , (9)
, (9)
Если наблюдаемая разность между ранговыми суммами двух продуктов равна или больше LSD, тогда дают заключение, что два продукта имеют разные ранги.
Если наблюдаемая разность меньше чем LSD, тогда два продукта имеют одинаковые ранги.
(Поправка).
8.2.4 Связанные ранги
Если два или больше рангов связаны вместе, то для моделей полного блока меняется на
![]() , (10)
, (10)
где получают следующим образом.
Пусть ,
, ....,
есть число связанных рангов в каждой группе связанных рангов
![]() . (11)
. (11)
Например, в таблице 1 имеются две группы связанных рангов:
- первая группа происходит от дегустатора 2 (два образца B и C связаны, следовательно, =2);
- вторая группа происходит от дегустаторов 3 (три образца B, C и D связаны, следовательно, =3).
Отсюда:
![]() .
.
Так как; =7 и
=4, выполняют тест, имея вычисленное
и используя определенное значение
![]() .
.
Затем сравнивают с критическими значениями из таблицы 4 или 5.
8.2.5 Сравнение двух продуктов: проверка знака
В частном случае, если только два продукта подлежат ранжированию, то можно использовать проверку знака.
Примечание - В этом случае тест парного сравнения (ISO 5495) является более подходящим.
В случае, когда имеются два продукта A и B, если есть количество оценок, в которых первым ранжируется продукт A и
есть количество оценок, в которых первым ранжируется продукт B, то пусть
будет меньшим числом
или
.
Любые отклики "нет различия" следует не принимать во внимание.
Нулевая гипотеза имеет следующее выражение:
![]() ,
,
где и
- теоретические числа рангов первой позиции для продуктов A и B, соответственно (A и B были бы ранжированы одинаково в полной совокупности).
Альтернативная гипотеза имеет следующее выражение:
![]() (A и B были бы по-разному ранжированы в полной совокупности).
(A и B были бы по-разному ранжированы в полной совокупности).
Если меньше критического значения в таблице 6 для количества решающих оценок, то
исключается и дают заключение, что A и B получили значимо разные ранги.
9 Протокол испытания
Протокол испытания должен включать следующую информацию:
a) цель теста;
b) всю информацию, необходимую для полной идентификации образца (или образцов)
1) количество образцов;
2) применяли ли контрольные образцы;
c) принятые параметры теста
1) количество дегустаторов и уровень их квалификации;
2) характеристики окружающей среды при тестировании,
3) материальные условия;
d) полученные результаты вместе с их статистической интерпретацией;
e) ссылку на настоящий стандарт;
f) отклонения, которые имели место при осуществлении метода, установленного в настоящем стандарте;
g) Ф.И.О. лица, осуществляющего надзор за ходом тестирования;
h) дату и время проведения испытания.
Таблица 1 - Сводка результатов и вычисление ранговых сумм
Номер дегустатора | Образцы | Ранговая сумма | |||
A | B | C | D | ||
1 | 1 | 2 | 3 | 4 | 10 |
2 | 4 | 1,5 | 1,5 | 3 | 10 |
3 | 1 | 3 | 3 | 3 | 10 |
4 | 1 | 3 | 4 | 2 | 10 |
5 | 3 | 1 | 2 | 4 | 10 |
6 | 2 | 1 | 3 | 4 | 10 |
7 | 2 | 1 | 4 | 3 | 10 |
Ранговые суммы для образцов | 14 | 12,5 | 20,5 | 23 | 70 |
Примечание - Так как каждому дегустатору назначен один и тот же набор рангов, суммы для строк являются идентичными и каждая сумма для строк равна 0,5 | |||||
Таблица 2 - Критические значения для коэффициента Спиермана
Количество образцов | Уровень значимости, | |
|
| |
6 | 0,886 | - |
7 | 0,786 | 0,929 |
8 | 0,738 | 0,881 |
9 | 0,700 | 0,833 |
10 | 0,648 | 0,794 |
11 | 0,618 | 0,755 |
12 | 0,587 | 0,727 |
13 | 0,560 | 0,703 |
14 | 0,538 | 0,675 |
15 | 0,521 | 0,654 |
16 | 0,503 | 0,635 |
17 | 0,485 | 0,615 |
18 | 0,472 | 0,600 |
19 | 0,460 | 0,584 |
20 | 0,447 | 0,570 |
21 | 0,435 | 0,556 |
22 | 0,425 | 0,544 |
23 | 0,415 | 0,532 |
24 | 0,406 | 0,521 |
25 | 0,398 | 0,511 |
26 | 0,390 | 0,501 |
27 | 0,382 | 0,491 |
28 | 0,375 | 0,483 |
29 | 0,368 | 0,475 |
30 | 0,362 | 0,467 |
Таблица 3 - Критические значения для теста по Пейджу в случае модели полного блока
Кол-во дегус- | Количество образцов (или продуктов), | |||||||||||
3 | 4 | 5 | 6 | 7 | 8 | 3 | 4 | 5 | 6 | 7 | 8 | |
Уровень значимости | Уровень значимости | |||||||||||
7 | 91 | 189 | 338 | 550 | 835 | 1204 | 93 | 193 | 346 | 563 | 855 | 1232 |
8 | 104 | 214 | 384 | 625 | 950 | 1371 | 106 | 220 | 393 | 640 | 972 | 1401 |
9 | 116 | 240 | 431 | 701 | 1065 | 1537 | 119 | 246 | 441 | 717 | 1088 | 1569 |
10 | 128 | 266 | 477 | 777 | 1180 | 1703 | 131 | 272 | 487 | 793 | 1205 | 1736 |
11 | 141 | 292 | 523 | 852 | 1295 | 1868 | 144 | 298 | 534 | 869 | 1321 | 1905 |
12 | 153 | 317 | 570 | 928 | 1410 | 2035 | 156 | 324 | 584 | 946 | 1437 | 2072 |
13 | 165 | 343* | 615* | 1003* | 1525* | 2201* | 169 | 350* | 628* | 1022* | 1553* | 2240* |
14 | 178 | 368* | 661* | 1078* | 1639* | 2367* | 181 | 376* | 674* | 1098* | 1668* | 2407* |
15 | 190 | 394* | 707* | 1153* | 1754* | 2532* | 194 | 402* | 721* | 1174* | 1784* | 2574* |
16 | 202 | 420* | 754* | 1228* | 1868* | 2697* | 206 | 427* | 767* | 1249* | 1899* | 2740* |
17 | 215 | 445* | 800* | 1303* | 1982* | 2862* | 218 | 453* | 814* | 1325* | 2014* | 2907* |
18 | 227 | 471* | 846* | 1378* | 2097* | 3028* | 231 | 479* | 860* | 1401* | 2130* | 3073* |
19 | 239 | 496* | 891* | 1453* | 2217* | 3193* | 243 | 505* | 906* | 1476* | 2245* | 3240* |
20 | 251 | 522* | 937* | 1528* | 2325* | 3358* | 256 | 531 | 953* | 1552* | 2360* | 3406* |
Примечание - Значения, отмеченные звездочкой (*), являются критическими значениями, вычисленными путем аппроксимации с использованием нормального распределения. | ||||||||||||
Таблица 4 - Критические значения, , для теста по Фридману (риски 0,05 и 0,01, см. [6])
Кол-во дегустаторов | Количество образцов (или продуктов), | |||||||||
3 | 4 | 5 | 6 | 7 | 3 | 4 | 5 | 6 | 7 | |
Уровень значимости | Уровень значимости | |||||||||
7 | 7,143 | 7,8 | 9,11 | 10,62 | 12,07 | 8,857 | 10,371 | 11,97 | 13,69 | 15,35 |
8 | 6,250 | 7,65 | 9,19 | 10,68 | 12,14 | 9,000 | 10,35 | 12,14 | 13,87 | 15,53 |
9 | 6,222 | 7,66 | 9,22 | 10,73 | 12,19 | 9,667 | 10,44 | 12,27 | 14,01 | 15,68 |
10 | 6,200 | 7,67 | 9,25 | 10,76 | 12,23 | 9,600 | 10,53 | 12,38 | 14,12 | 15,79 |
11 | 6,545 | 7,68 | 9,27 | 10,79 | 12,27 | 9,455 | 10,60 | 12,46 | 14,21 | 15,89 |
12 | 6,167 | 7,70 | 9,29 | 10,81 | 12,29 | 9,500 | 10,68 | 12,53 | 14,28 | 15,96 |
13 | 6,000 | 7,70 | 9,30 | 10,83 | 12,37 | 9,385 | 10,72 | 12,58 | 14,34 | 16,03 |
14 | 6,143 | 7,71 | 9,32 | 10,85 | 12,34 | 9,000 | 10,76 | 12,64 | 14,40 | 16,09 |
15 | 6,400 | 7,72 | 9,33 | 10,87 | 12,35 | 8,933 | 10,80 | 12,68 | 14,44 | 16,14 |
16 | 5,99 | 7,73 | 9,34 | 10,88 | 12,37 | 8,79 | 10,84 | 12,72 | 14,48 | 16,18 |
17 | 5,99 | 7,73 | 9,34 | 10,89 | 12,38 | 8,81 | 10,87 | 12,74 | 14,52 | 16,22 |
18 | 5,99 | 7,73 | 9,36 | 10,90 | 12,39 | 8,84 | 10,90 | 12,78 | 14,56 | 16,25 |
19 | 5,99 | 7,74 | 9,36 | 10,91 | 12,40 | 8,86 | 10,92 | 12,81 | 14,58 | 16,27 |
20 | 5,99 | 7,74 | 9,37 | 10,92 | 12,41 | 8,87 | 10,94 | 12,83 | 14,60 | 16,30 |
5,99 | 7,81 | 9,49 | 11,07 | 12,59 | 9,21 | 11,34 | 13,28 | 15,09 | 16,81 | |
Примечание 1 - Количество Примечание 2 - Значения, выделенные курсивом, получены с использованием аппроксимации к распределению | ||||||||||
Таблица 5 - Критические значения распределения (риски: 0,05 и 0,01)
Количество образцов (или продуктов), | Число степеней свободы | Уровень значимости, | |
( |
|
| |
3 | 2 | 5,99 | 9,21 |
4 | 3 | 7,81 | 11,34 |
5 | 4 | 9,49 | 13,28 |
6 | 5 | 11,07 | 15,09 |
7 | 6 | 12,59 | 16,81 |
8 | 7 | 14,07 | 18,47 |
9 | 8 | 15,51 | 20,09 |
10 | 9 | 16,92 | 21,67 |
11 | 10 | 18,31 | 23,21 |
12 | 11 | 19,67 | 24,72 |
13 | 12 | 21,03 | 26,22 |
14 | 13 | 22,36 | 27,69 |
15 | 14 | 23,68 | 29,14 |
16 | 15 | 25,00 | 30,58 |
17 | 16 | 26,30 | 32,00 |
19 | 18 | 28,87 | 34,80 |
20 | 19 | 30,14 | 36,19 |
21 | 20 | 31,4 | 37,6 |
22 | 21 | 32,7 | 38,9 |
23 | 22 | 33,9 | 40,3 |
24 | 23 | 35,2 | 41,6 |
25 | 24 | 36,4 | 43,0 |
26 | 25 | 37,7 | 44,3 |
27 | 26 | 38,9 | 45,6 |
28 | 27 | 40,1 | 47,0 |
29 | 28 | 41,3 | 48,3 |
30 | 29 | 42,6 | 49,6 |
Таблица 6 - Критические значения для проверки знака (на основе двойной выборки)
Количество оценок, | Уровень значимости, | Количество оценок, | Уровень значимости, | ||
|
|
|
| ||
1 | 46 | 15 | 13 | ||
2 | 47 | 16 | 14 | ||
3 | 48 | 16 | 14 | ||
4 | 49 | 17 | 15 | ||
5 | 50 | 17 | 15 | ||
6 | 0 | 51 | 18 | 15 | |
7 | 0 | 52 | 18 | 16 | |
8 | 0 | 0 | 53 | 18 | 16 |
9 | 1 | 0 | 54 | 19 | 17 |
10 | 1 | 0 | 55 | 19 | 17 |
11 | 1 | 0 | 56 | 20 | 17 |
12 | 2 | 1 | 57 | 20 | 18 |
13 | 2 | 1 | 58 | 21 | 18 |
14 | 2 | 1 | 59 | 21 | 19 |
15 | 3 | 2 | 60 | 21 | 19 |
16 | 3 | 2 | 61 | 22 | 20 |
17 | 4 | 2 | 62 | 22 | 20 |
18 | 4 | 3 | 63 | 23 | 20 |
19 | 4 | 3 | 64 | 23 | 21 |
20 | 5 | 3 | 65 | 24 | 21 |
21 | 5 | 4 | 66 | 24 | 22 |
22 | 5 | 4 | 67 | 25 | 22 |
23 | 6 | 4 | 68 | 25 | 22 |
24 | 6 | 5 | 69 | 25 | 23 |
25 | 7 | 5 | 70 | 26 | 23 |
26 | 7 | 6 | 71 | 26 | 24 |
27 | 7 | 6 | 72 | 27 | 24 |
28 | 8 | 6 | 73 | 27 | 25 |
29 | 8 | 7 | 74 | 28 | 25 |
30 | 9 | 7 | 75 | 28 | 25 |
31 | 9 | 7 | 76 | 28 | 26 |
32 | 9 | 8 | 77 | 29 | 26 |
33 | 10 | 8 | 78 | 29 | 27 |
34 | 10 | 9 | 79 | 30 | 27 |
35 | 11 | 9 | 80 | 30 | 28 |
36 | 11 | 9 | 81 | 31 | 28 |
37 | 12 | 10 | 82 | 31 | 28 |
38 | 12 | 10 | 83 | 32 | 29 |
39 | 12 | 11 | 84 | 32 | 29 |
40 | 13 | 11 | 85 | 32 | 30 |
41 | 13 | 11 | 86 | 33 | 30 |
42 | 14 | 12 | 87 | 33 | 31 |
43 | 14 | 12 | 88 | 34 | 31 |
44 | 15 | 13 | 89 | 34 | 31 |
45 | 15 | 13 | 90 | 35 | 32 |
Для значений | |||||
Приложение A
(обязательное)
Определение условий теста
Таблица A.1 - Выбор параметров теста на основе его цели
Цель теста | Квалификация дегустатора | Количество дегустаторов | Статистический метод | ||
Сравнение до известного порядка (работа дегустатора) | Порядок неизвестных продуктов (сравнение продуктов) | ||||
2 продукта | более 2 продуктов | ||||
Оценка работы индивидуумов | Отобранные дегустаторы или эксперты по органолептическому анализу | Неограниченное | Тест по Спиерману | Проверка знака | Тест по Фридману |
Оценка работы группы | Отобранные дегустаторы или эксперты по органолептическому анализу | Неограниченное | Тест по Пейджу | ||
Оценка продукта по описательному критерию | Отобранные дегустаторы или эксперты по органолептическому анализу | Предпочтительно от 12 до 15 | |||
Оценка продукта по гедоническому предпочтению | Потребители | Минимум 60 на группу типа потребителей (ячейка и сегмент) |
| ||

Приложение B
(справочное)
Практический пример применения. Модель полного блока
Результаты четырнадцати дегустаторов, проведших тестирование одной последовательности образцов, приведены в таблице B.1.
Таблица B.1 - Пример оценки
Дегустатор | Образцы | ||||
A | B | C | D | E | |
1 | 2 | 4 | 5 | 3 | 1 |
2 | 4 | 5 | 3 | 1 | 2 |
3 | 1 | 4 | 5 | 3 | 2 |
4 | 1 | 2 | 5 | 3 | 4 |
5 | 1 | 5 | 2 | 3 | 4 |
6 | 2 | 3 | 4 | 5 | 1 |
7 | 4 | 5 | 3 | 1 | 2 |
8 | 2 | 3 | 5 | 4 | 1 |
9 | 1 | 3 | 4 | 5 | 2 |
10 | 1 | 2 | 5 | 3 | 4 |
11 | 4 | 5 | 2 | 3 | 1 |
12 | 2 | 4 | 3 | 5 | 1 |
13 | 5 | 3 | 4 | 2 | 1 |
14 | 3 | 5 | 2 | 4 | 1 |
Ранговые суммы | 33 | 53 | 52 | 45 | 27 |
Значение из теста по Фридману вычисляют следующим образом.
Так как =14,
=5,
=33,
=53,
=52,
=45,
=27
![]() .
.
Величина 15,31 больше значения, приведенного в таблице 4 для =14,
=5 на уровне значимости 0,05 (т.е. 9,32). Поэтому можно сделать заключение с риском ошибки не более 5%, что дегустаторы восприняли пять образцов как имеющие различия.
Более того, можно также решить, что два отдельных образца являются разными, если абсолютная разность между их ранговыми суммами больше следующей величины.
![]() (при риске 0,05).
(при риске 0,05).
На уровне риска 0,05 различия между A и B, A и C, E и B, E и C, E и D являются значимыми, разности между их ранговыми суммами показаны ниже соответственно:
A-B:|33-53|=20 | E-B:|27-53|=26 |
Этот последний анализ мог бы иметь результатом следующее представление:
E | A | D | C | B | ||||||
Смысл подчеркивания заключается в следующем:
- два образца, которые не соединятся непрерывным подчеркиванием, воспринимаются дегустаторами как значимо разные (с риском 0,05);
- два образца, которые соединятся непрерывным подчеркиванием, воспринимаются дегустаторами как не имеющие значимого различия;
- A и E, которые не различимы, ранжируются значимо перед D, C и B, которые сами не различаются. Присутствуют три группы, из которых одна содержит A и E, еще одна - A и D, вторая - B, D и C.
В случае, когда имеются убедительные или обоснованные причины, чтобы перед тестированием допускать априорно следующее ранг (E) ранга (A)
ранга (D)
ранга (C)
ранга (B), тогда тест по Пейджу можно было бы использовать, чтобы проверить эту одностороннюю гипотезу.
Затем значение из теста по Пейджу вычисляют следующим образом
![]() .
.
Критическое значение из теста по Пейджу для =5,
=14, a=0,05 составляет 661 (см. таблицу 3).
Так как больше чем 661, поэтому нулевую гипотезу всестороннего отсутствия различий между образцами при уровне риска a=0,05 можно исключить.
Заключение по этому примеру:
a) на основе теста по Фридману:
- с риском 0,05, Е не отличается от A; D - ни от C и ни от B; A - от D, но A значимо отличается от C и B, E - от D, C и B;
b) принимая во внимание Пейдж-тест:
- дегустаторы выявляют различия между образцами с риском a=0,05; принятый предварительно установленный порядок подтверждается.
Приложение C
(справочное)
Практический пример применения. Модель сбалансированного неполного блока
Результаты десяти дегустаторов, которые провели тестирование трех из пяти образцов, относящихся к модели сбалансированного неполного блока, приведены в таблице C.1.
Таблица C.1 - Пример оценки
Дегустатор | Образцы | ||||
A | B | C | D | E | |
1 | 1 | 2 | 3 | ||
2 | 1 | 2 | 3 | ||
3 | 2 | 3 | 1 | ||
4 | 1 | 2 | 3 | ||
5 | 2 | 3 | 1 | ||
6 | 1 | 3 | 2 | ||
7 | 1 | 3 | 2 | ||
8 | 2 | 3 | 1 | ||
9 | 3 | 2 | 1 | ||
10 | 1 | 3 | 2 | ||
Ранговые суммы | 8 | 13 | 15 | 16 | 8 |
Значение для теста по Фридману вычисляют следующим образом.
Так как =10,
=5,
=3,
=6,
=3,
=1,
=8,
=13,
=15,
=16,
=8
![]() .
.
Величина 11,6 больше значения, данного в таблице 4 для =5 на уровне значимости 0,05 (т.е. 9,25); поэтому можно сделать заключение с риском ошибки меньше или равной 5%, что дегустаторы восприняли пять образцов как имеющие различия.
Более того, можно также решить, что два отдельных образца являются разными, если абсолютная разность между их ранговыми суммами больше следующей величины
![]() (при риске 0,05).
(при риске 0,05).
С риском 0,05, различия между A и C, A и D, C и E, D и E являются значимыми, разности между их ранговыми суммами показаны ниже соответственно:
A-C:|8-15|=7 | C-E:|15-8|=7 |
Этот последний анализ мог бы иметь результатом следующее представление
A | E | B | C | D. | ||||||
В случае, когда имеются убедительные или обоснованные причины, чтобы перед тестированием допускать априорно следующее: ранг (E)ранга (A)
ранга (D)
ранга (C)
ранга (B), тогда тест по Пейджу можно было бы использовать, чтобы проверить эту одностороннюю гипотезу.
Значение из теста по Пейджу вычисляют следующим образом:
1=(1х8)+(2х8)+(3х16)+(4х15)+(5х13)=197.
Поскольку =5,
=3,
=10, то значение
принимает следующий вид:
![]() .
.
Так как больше чем 2,33, поэтому нулевую гипотезу всестороннего отсутствия различий между образцами при уровне риска a=0,05 можно исключить.
Заключение по этому примеру:
a) на основе теста по Фридману
с риском 0,05, A и E имеют ранговые суммы значимо меньше чем C и D. B не отличается значимо от любого из четырех других образцов;
b) на основе Пейдж-теста
дегустаторы выявляют различия между образцами с риском 0,01. Принятый предварительно установленный порядок подтверждается.
Приложение D
(справочное)
Пример формы для ответа
Фамилия: | Дата: | N теста: | ||||||||
Попробуйте на вкус образцы слева направо. | ||||||||||
Напишите коды в порядке увеличения сладкого вкуса в нижеследующих квадратах. | ||||||||||
Код | Наименьший | Наибольший | ||||||||
Комментарии: | ||||||||||
Приложение ДА
(справочное)
Сведения о соответствии ссылочных межгосударственных стандартов международным стандартам
Таблица ДА.1
Обозначение ссылочного международного стандарта | Степень соответствия | Обозначение и наименование межгосударственного стандарта |
ISO 3534-1 | - | * |
ISO 5492 | IDT | ГОСТ ISO 5492-2014 "Органолептический анализ. Словарь" |
ISO 6658 | - | * |
ISO 8586-1 | IDT | ГОСТ ISO 8586-2015 "Органолептический анализ. Общие руководящие указания по отбору, обучению и контролю за работой отобранных испытателей и экспертов-испытателей" |
ISO 8586-2 | IDT | ГОСТ ISO 8586-2015 "Органолептический анализ. Общие руководящие указания по отбору, обучению и контролю за работой отобранных испытателей и экспертов-испытателей" |
ISO 8589 | IDT | ГОСТ ISO 8589-2014 "Органолептический анализ. Общее руководство по проектированию лабораторных помещений" |
ISO 11035 | - | * |
ISO 11036 | - | * |
* Соответствующий межгосударственный стандарт отсутствует. До его принятия рекомендуется использовать официальный перевод на русский язык данного международного стандарта. Примечание - В настоящей таблице использовано следующее условное обозначение степени соответствия стандартов: - IDT - идентичные стандарты. | ||
Библиография
[1] | ISO 5495 Сенсорный анализ. Методология. Метод парного сравнения |
[2] | Friedman, М. Использование рангов, чтобы избежать допущений нормальности, подразумеваемой в дисперсионном анализе, Journal of the American Statistical Association, 32, 1937, pp.675-701 |
[3] | Page, E.B. Порядковые гипотезы для множественных обращений: критерий значимости для линейных рангов, Journal of the American Statistical Association, 58, 1963, pp.216-230 |
[4] | XP V09-500, Analyse sensorielle - Methodologie - Directives generates pour la realisation d'epreuves hedoniques en laboratoire devaluation sensorielle ou en salle en conditions controlees impliquant des consommateurs |
[5] | Cochran, W.G. and Cox, G.M. Экспериментальные дизайны. John Wiley & Sons, Inc., Глава 11, Сбалансированные неполные блоки, 1950, pp.315-346 |
[6] | Lothar, S. Прикладные статистики, Руководство по техническим приемам, Springer Series in Statistics, Springer-Verlag, 1982 |
УДК 658.562.4:543.92:006.35 | МКС 67.050 | IDT |
Ключевые слова: органолептический анализ, методология, ранжирование, дегустатор, ранговые суммы | ||
Редакция документа с учетом
изменений и дополнений подготовлена

{kind=link}