ГОСТ Р ИСО 24616-2013
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Менеджмент языковых ресурсов. Многоязычная информационная система
Language resources management. Multilingual information framework
ОКС 01.020
Дата введения 2015-01-01
Предисловие
1 ПОДГОТОВЛЕН Закрытым акционерным обществом "Проспект" (ЗАО "Проспект") на основе собственного перевода на русский язык международного стандарта, указанного в пункте 4
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 55 "Терминология, элементы данных и документация в бизнес-процессах и электронной торговле"
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 8 ноября 2013 г. N 1385-ст
4 Настоящий стандарт идентичен международному стандарту ИСО 24616:2012* "Менеджмент языковых ресурсов. Многоязычная информационная система" (ISO 24616:2012 "Language resources management - Multilingual information framework", IDT).
________________
* Доступ к международным и зарубежным документам, упомянутым в тексте, можно получить, обратившись в Службу поддержки пользователей. - .
При применении настоящего стандарта рекомендуется использовать вместо ссылочных международных стандартов соответствующие им национальные стандарты, сведения о которых приведены в дополнительном приложении ДА
5 ВВЕДЕН ВПЕРВЫЕ
6 ПЕРЕИЗДАНИЕ. Апрель 2020 г.
Правила применения настоящего стандарта установлены в статье 26 Федерального закона от 29 июня 2015 г. N 162-ФЗ "О стандартизации в Российской Федерации". Информация об изменениях к настоящему стандарту публикуется в ежегодном (по состоянию на 1 января текущего года) информационном указателе "Национальные стандарты", а официальный текст изменений и поправок - в ежемесячном информационном указателе "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ближайшем выпуске ежемесячного информационного указателя "Национальные стандарты". Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет (www.gost.ru)
1 Область применения
Настоящий стандарт предоставляет общую платформу для моделирования и организации многоязычной информации в различных областях применения, таких как локализация, перевод, мультимедийное аннотирование, управление документооборотом, поддержка электронных библиотек и разнообразные прикладные информационные модели и моделирование предприятий. Описываемая в стандарте многоязычная информационная система MLIF (multilingual information framework) содержит в себе метамодель и совокупность общих категорий данных (по ИСО 12620:2009) для различных областей применения. В рамках MLIF описываются также соответствующие стратегии связывания и обеспечения взаимодействия, в частности, между моделями XLIFF, ТМХ, smilText и ITS.
2 Нормативные ссылки
В настоящем стандарте использованы нормативные ссылки на следующие стандарты. Для датированных ссылок применяют только указанное издание ссылочного стандарта, для недатированных - последнее издание (включая все изменения).
ISO 12620:2009*, Terminology and other language and content resources - Specification of data categories and management of a Data Category Registry for language resources (Терминология, другие языковые ресурсы и ресурсы содержания. Спецификация категорий данных и ведение реестра категорий данных для языковых ресурсов)
________________
* Заменен на ISO 12620:2019.
ISO 8879, Information processing; Text and office systems; Standard Generalized Markup Language (SGML) (Обработка информации. Текстовые и офисные системы. Стандартный обобщенный язык разметки (SGML)
3 Термины и определения
В настоящем стандарте применены следующие термины с соответствующими определениями:
3.1 обрамление (adornment): Категория данных, присваиваемая компоненту метамодели.
3.2 внутристрочный код (inline code): Команда, встроенная в первичный документ.
Примечание - Такой внутренний код может содержать в себе инструкции по оформлению (например, коды HTML).
3.3 субтитр (subtitle): Текстовое представление диалога в кинофильмах, телепрограммах, видеоиграх и т.п., обычно отображаемое в нижней строке экрана.
3.4 рабочий язык (working language): Язык, на котором представляются лингвистические последовательности.
4 Принципы представления спецификации
4.1 Ключевой нормативный документ спецификации - унифицированный язык моделирования UML (Unified Modeling Language)
Спецификация MLIF соответствует принципам моделирования UML, которые определены Консорциумом по разработке и продвижению объектно-ориентированных технологий Object Management Group (OMG) [UML]. В спецификации используется подмножество языка UML, подходящее для целей MLIF.
4.2 Метамодель и ее расширение
Как и в системе терминологической разметки TMF (Terminological Markup Framework), описанной в ИСО 16642, спецификация MLIF определяет метамодель, которая "обрамлена" категориями данных, определенными в ИСО 12620.
4.3 Сериализация ХМL
Наряду со средствами языка XML, определенными в ИСО 8879, спецификация MLIF вместе с метамоделью и ее обрамлением обеспечивает тип представления на языке XML, называемый "сериализациeй XML".
5 Спецификация метамодели
Метамодель MLIF представлена в виде диаграммы объектов на рисунке 1.
Метамодель MLIF определяется следующими шестью "центральными компонентами", представленными ниже в том порядке, который задается сериализацией XML:
- <MLDC> (Multilingual Data Collection) - многоязычная коллекция данных, которая содержит общую информацию и несколько многоязычных блоков;
- <GI> (Global Information) - общая информация, содержащая сведения технического и административного характера, касающиеся всей коллекции многоязычных данных;
- <GroupC> (Grouping components) - компоненты группировки, представляющие собой подчиненную коллекцию многоязычных данных с общим источником или с общим целевым назначением в рамках конкретного проекта;
- <MultiC> (Multilingual Component) - многоязычный компонент, в рамках которого сгруппированы все варианты данного текстового контента;
- <MonoC> (Monolingual Component) - одноязычный компонент, в рамках которого сгруппирована информация, относящаяся к одному языку, и который является частью многоязычного компонента (MultiC);
- <HistoC> (History Component) - компонент предыстории, отслеживающий изменения того компонента, к которому он привязан (т.е. отслеживающий версии);
- <SegC> (Segmentation Component) - компонент сегментации, позволяющий производить сегментацию текстовой информации на любом уровне; такая сегментация может быть рекурсивной.
|
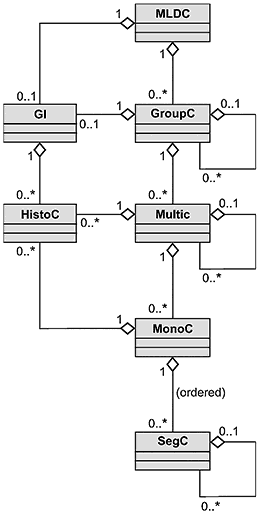
Рисунок 1 - Метамодель MLIF
6 Соответствие MLIF
Для обеспечения соответствия настоящему стандарту необходимо, чтобы в рамках используемого формата метамодель MLIF применялась одним из двух возможных способов:
- путем ее полномасштабной реализации, начиная с уровня <MLDC> или
- посредством специального вложения информации, совместимой с MLIF, в другую модель путем реализации одного из элементов MLIF более низкого уровня, а именно - <GroupC>, <MultiC> или <MonoC>.
7 Обрамление метамодели
7.1 Вводные замечания
В результате выполнения XML-сериализации метамодели MLIF получается совокупность элементов и атрибутов XML, которые описываются в последующих разделах, где символы "<" и ">" являются разделителями имени элемента. В соответствии с рекомендациями TEI (http://www.tei-c.org), некоторые атрибуты определяются их классом, с учетом соглашения, что имени атрибута "класс" должен предшествовать префикс "att." (например, "att.xlink"). Перечисление других XML-атрибутов осуществляется в соответствии с соглашением о заключении имени атрибута в кавычки (например, "xml:lang"). При этом должны применяться спецификации, представленные в приложении Ж.
7.2 Общие принципы использования обобщенных атрибутов консорциума W3C
Во всех приложениях, соответствующих спецификации MLIF, подлежат использованию следующие атрибуты W3C:
- согласно рекомендациям W3C, для представления рабочего языка следует использовать атрибут xml:lang, особенно при систематическом повторении реализации MonoC;
- согласно рекомендациям W3C, в качестве уникального идентификатора элемента метамодели MLIF должен использоваться атрибут xml:id.
7.3 Рекомендуемое обрамление для компонентов GI
- <domain>
- <project>
- <source>
- <sourceType>
- <sourceLanguage>
- <sourceFormat>
- <targetLanguage>
- <formatVersion>
- <legalStatus>
- <creationTool>
- <creationToolVersion>
- <creationDate>
- <creationIdentifier
- <changeDate>
- <changeldentifier>
7.4 Рекомендуемое обрамление для компонентов GroupC
- <groupType>
7.5 Рекомендуемое обрамление для компонентов MultiC
- <class>
- <changeDate>
- <changeldentifier>
- <creationTool>
- <creationToolVersion>
- <creationldentifier>
- <creationDate>
- <translationStatus>
- <matchQuality>
7.6 Рекомендуемое и обязательное обрамление для компонентов MonoC
- att.lang
- <translationRole>
- <segmentation>
- att.xlink
Атрибут языка обязателен только в случае компонента MonoC. Во всех остальных случаях этот атрибут не обязателен.
7.7 Рекомендуемое обрамление для компонентов SegC
- <traslationRole>
- <beginPairedTag>
- <endPairedTag>
- <genericGroupPlaceholder>
- <placeholder>
- <genericPlaceholder>
- <translate>
- att.linguistic
- att.xlink
7.8 Рекомендуемое обрамление для компонентов HistoC
HistoC - это обобщенный компонент, отслеживающий изменения того компонента, к которому он привязан (например, его создание, модификацию и контроль). В метамодели MLIF компонент HistoC может быть привязан к компонентам Gl, MultiC или MonoC. Это обеспечивает возможность регистрации всех изменений или расширений контролируемого компонента.
Компонент HistoC может быть обрамлен четырьмя элементами:
- <author>
- <version>
- <transaction>
- <date>
7.9 Рекомендуемое обрамление для оперативного аннотирования
Многоязычные текстовые документы зачастую бывают всего лишь одним из этапов формирования сложного информационного потока, в котором задействованы внешние источники документов, представленных в самых разных форматах. Поэтому часто возникает потребность во внутреннем механизме разметки, который указывает, какие свойства представляемой информации подлежат сохранению в целевом переводном документе. Отсюда следует, что в приложениях, совместимых с MLIF, применительно к элементам <SegC>, которые отображаются на аналогичные подмножества в ТМХ и XLIFF, должны использоваться следующие элементы:
- <beginPairedTag>
- <endPairedTag>
- <genericGroupPlaceholder>
- <genericPlaceholder>
- <placeholder>
7.10 Рекомендуемое обрамление для локализации
Для предоставления информации, имеющей отношение к локализации, должны использоваться все следующие элементы:
- <translationRole>
- <translationStatus>
7.11 Рекомендуемое обрамление для интернационализации
- <translate>
7.12 Рекомендуемое обрамление для временной синхронизации
В тех случаях, когда текстовый контент подлежит передаче (в письменной или устной форме) вместе с действующими ограничениями, должны использоваться следующие элементы:
- <duration>
- <begin>
- <next>
8 Связи с другими стандартами
Подобно структуре терминологической разметки TMF в сфере терминологии [ИСО 16642], многоязычная информационная структура MLIF представляет собой метамодель, которая в сочетании с определенными категориями данных обеспечивает взаимодействие между несколькими многоязычными приложениями и корпусами. MLIF работает с многоязычными корпусами, многоязычными фрагментами, которые связаны между собой отношениями перевода. Применительно к каждой сфере использования MLIF могут устанавливаться конкретные ограничения по крупности разбиения для целей сегментации и описания. Два этих процесса могут выполняться на основе MAF [ИСО 24611], SynAF [ИСО 24615] и TMF - для морфологического описания, синтаксического аннотирования и терминологического описания, соответственно.
MLIF поддерживает функции создания и организации взаимодействия ресурсов локализации и ресурсов памяти переводов, а также обеспечивает описание метамодели многоязычного контента. В рамках MLIF не предлагается какой-то исчерпывающий перечень элементов такого описания, а лишь устанавливается список категорий данных, который может легко обновляться и расширяться. Этот список является отправным пунктом для содержательной многоязычной информации в контексте многочисленных сценариев приложений.
Однако MLIF не только описывает элементарные лингвистические сегменты (например, предложение, синтаксический фрагмент, слово или часть речи), но может также использоваться для представления структуры документа (к примеру, заголовка, аннотации, абзаца и раздела). Кроме того, MLIF позволяет устанавливать внешние и внутренние связи (через аннотации и ссылки).
MLIF предназначается для обеспечения удобной общей основы взаимодействия систем, работающих с разными форматами, такими как ТМХ (LISA OSCAR) и XLIFF (OASIS). MLIF может рассматриваться как родительский уровень этих форматов, поскольку каждый из них присущ многоязычным данным, выраженным в форме сегментов или текстовых единиц, и может храниться, участвовать в разных операциях и переводиться одинаковым способом. Примеры использования MLIF приведены в приложениях А-Е.
Приложение А
(справочное)
Примеры использования MLIF в системах автоматизированного перевода (CAT)
Основная причина использования таких элементов, как лемма, часть речи и морфологические особенности, состоит в том, чтобы обеспечить инструментальным средствам CAT систем переводческой памяти (translation memory) возможность перевода новых слов и предложений, отсутствующих в базе переводов.
Например, в рамках памяти переводов, которая содержит английское предложение "The meal is nice" и его перевод на французский язык "Le repas est bon", существующие инструментальные средства наподобие модуля Translator's Workbench системы SDL TRADOS* не способны самостоятельно вывести перевод предложения "The meals are nice", даже несмотря на то, что текстовые леммы "The meal is nice" и "The meals are nice" фактически совпадают. Причина подобной слабости систем CAT заключается в том, что в них в процессе перевода используется строго ограниченный набор лингвистических критериев.
_______________
* SDL TRADOS Translator's Workbench является примером подходящего продукта, имеющегося в продаже. Эта информация приведена исключительно для удобства пользователей настоящего стандарта и не может рассматриваться как рекомендация ИСО относительно использования вышеуказанного продукта.
Так, информация, порождаемая модулем TRADOS, который называется "Translator's Workbench", выглядит следующим образом:
|

Для перевода заканчивающегося точкой предложения "The meals are nice" MLIF-совместимое инструментальное средство должно реализовать процедуру, представленную ниже.
Шаг 1: представить в рамках MLIF и добавить соответствующие лингвистические свойства применительно ко всем словам, находящимся в памяти переводов.
Шаг 2: запустить программу разметки частей речи для работы над предложением с целью получения правильных категорий морфосинтаксических категорий слов.
Шаг 3: перевести леммы, используя двуязычный англо-французский словарь.
Шаг 4: обратиться к французскому словарю форм склонения для извлечения корректной падежной формы с учетом леммы и морфологических особенностей.
Шаг 5: дать перевод предложения "The meals are nice" посредством замены каждого английского слова его французской падежной формой по следующей схеме:
"The meals are nice." => "Les repas sont bons."
Данные на языке XML должны содержать объявление структуры элемента путем определения набора тегов (например, для "nS"), сегментированное слово и набор тегов, определенный в MAF:
| |
| |


Приложение Б
(справочное)
Пример: представление данных в формате ТМХ
Б.1 Введение
ТМХ (Translation Memory eXchange) - это открытый стандарт среды XML для обмена данными памяти переводов (Translation Memory), созданными в рамках системы автоматизированного перевода (CAT) и инструментальными средствами локализации. Назначение стандарта ТМХ состоит в том, чтобы упростить такой обмен между CAT и поставщиками переводческих услуг, минимизировав или полностью исключив в рамках этого процесса потерю критической информации. Формат ТМХ, присутствующий на рынке с 1998 года, представляет собой стандарт, по которому осуществляется сертификация. Он был разработан и поддерживается Специальной группой OSCAR по открытым стандартам для информационных контейнеров и контента повторного использования (Open Standards for Container/Content Allowing Re-use) Ассоциации по стандартам в области локализации (LISA).
Б.2 Отображение формата ТМХ на формат MLIF
Формат ТМХ практически изоморфен метамодели MLIF. Ключевые элементы макроструктуры ТМХ отображаются на формат MLIF следующим образом:
- элемент <tmx> отображается на элемент <MLDC>;
- элемент <header> отображается на элемент <GI>;
- элемент <body> становится контейнером для элемента <tuv> и отображается на элемент <GroupC>;
- элемент <tu> отображается на элемент <MultiC>;
- элемент <tuv> отображается на элемент <MonoC>;
- <seg> отображается на элемент <SegC>;
- элемент <hi> описания шрифта отображается на шрифтовой элемент <SegC>.
Далее порядок отображения элементов ТМХ и их атрибутов на элементы MLIF следующий:
- Атрибут "creationtool" отображается на элемент <creationTool>;
- Атрибут "creationdate" отображается на элемент <creationDate>;
- Атрибут "tuid" отображается на элемент <creationldentifier> внутри MultiC.
- Элемент <prop> не отображается ни на какой конкретный элемент, поскольку он представляет собой заполнитель для данных, зависящих от приложения. При возможности конкретный элемент <prop> явным образом отображается на элементы MLIF или на стандартизованную категорию данных комитета ISO/TC 37, доступную в ISOCat.
Б.3 Пример данных
В приведенном ниже примере, относящемся к ТМХ версии 1.4, внимание сосредоточивается на многоязычных блоках ТМХ-документа, и не воспроизводятся все детали заголовка.
| |
| |


Соответствующее представление в MLIF, выбираемое по умолчанию, будет иметь вид:
|

Б.4 Пример взаимодействия между ТМХ и MLIF
Рисунок Б.1 иллюстрирует взаимодействие между ТМХ и MLIF. Этот процесс состоит из последовательных шагов извлечения, перевода и слияния. Начинается он с рассмотрения ТМХ-документа (TMX-Document) с лингвистическим контентом на английском (en) и немецком (de) языках. Процедура извлечения (Extract) (1) порождает так называемый "скелетный файл" (2), содержащий всю информацию о форматировании памяти переводов (ТМ), и лингвистический контент документа MLIF (3), в котором хранится лишь релевантная лингвистическая информация. Так как большинство переводчиков (каковыми могут быть и люди, и автоматические программные модули) работает с инструментальными средствами ТМХ, ориентированными на использование программных модулей, список стилей XSL делает возможным преобразование документа MLIF к документу ТМХ. Файл стилей не содержит никакой информации о форматировании. Как только переводчик добавляет соответствующий японский перевод (ja), другим списком стилей XSL осуществляется преобразование (Transformation) ТМХ-документа к документу MLIF (4). Наконец, новый документ MLIF (содержащий перевод на японский язык) сливается со скелетным файлом для получения нового документа в формате ТМХ (5).
|

Рисунок Б.1 - Схема взаимодействия ТМХ и MLIF
Приложение В
(справочное)
Пример представления данных в формате XLIFF
В.1 Введение
Формат XLIFF предназначен для определения и продвижения приемлемой спецификации обмена объектами локализуемых программ и документов, а также соответствующими метаданными.
В.2 Отображение XLIFF на MLIF
Формат XLIFF отличается от метамодели MLIF тем, что он четко обозначает различие между исходным и целевым языками для моноязычной информации. Такое различие проводится путем соответствующего применения категории данных <translationRole> в элементе <MonoC> совместно с объявлениями языков (<sourceLanguage> и <targetLanguage>) в элементе <GI>.
Отображение ключевых элементов макроструктуры XLIFF на MLIF производится следующим образом:
- элемент <xliff> отображается на элемент <MLDC>;
- элемент <header> отображается на элемент <GI>;
- элемент <body> является контейнером для элемента <tuv> и отображается на элемент <GroupC>;
- элемент <phase> отображается на элемент <HistoC>;
- элемент <trans-unit> отображается на элемент <MultiC>;
- элемент <source> отображается на элемент <MonoC> и одновременно задает значение элемента <translationRole> для элемента <sourceLanguage>. Надлежащий текстовый контент помещается в элемент <SegC>;
- элемент <target> отображается на элемент <MonoC> и одновременно задает значение элемента <translationRole> для элемента <targetLanguage>. Надлежащий текстовый контент помещается в элемент <SegC>;
- элемент <alt-trans> отображается на элемент <MultiC> и одновременно задает значение элемента <translationStatus> для изменения.
Далее элементы и атрибуты XLIFF отображаются на элементы MLIF так:
- атрибут инструментария XLIFF отображается на элемент <creationTool>.
В.3 Пример данных
В следующем примере, основанном на XLIFF версии 1.2, основное внимание сосредоточено на двуязычной части документа XLIFF:
|
|


Соответствующее стандартное представление MLIF будет иметь вид:
|

|

Приложение Г
(справочное)
Пример: представление данных модуля smilText
Г.1 Введение
В рамках рекомендаций консорциума W3C по языку разметки для создания интерактивных мультимедийных презентаций SMIL 3.0 (http://www.w3.orq/TR/2008/REC-SMIL3-20081201), модули smilText предоставляют текстовый контейнерный элемент с явно определенной моделью контента для описания синхронизируемого текста (http://www.w3.orq/TR/2008/REC-SMIL3-20081201/smil-text.html). Модуль smilText может стать важным прикладным контекстом для MLIF, так как связывает и синхронизирует мультимедийный и текстуальный типы контента.
Г.2 Использование общих атрибутов SMIL в MLIF
Общие схемы синхронизации, определенные в рекомендации по SMIL (Synchronized Multimedia Integration Language), могут применяться в рамках MLIF-совместимого контента для обеспечения механизмов синхронизации в текстовом контенте. Для этого в общую спецификацию MLIF интегрируются такие элементы SMIL, как "begin" (начать), "next" (следующий) и "dur" (длительность).
Г.3 Упрощенное отображение моноязычного контента
Типичным применением MLIF в соединении со SMIL является создание моноязычного результирующего продукта SMIL из многоязычной презентации в MLIF-совместимом формате. Такая потребность возникает при выборке контента, соответствующего конкретному языку, и его интеграции в один или несколько контейнеров <smilText> - например, в конструкцию <seq>. По возможности, существующая информация, касающаяся синхронизации, продвигается в информационные представления SMIL.
В этом плане ключевые отображения между MLIF и спецификацией smilText выполняются следующим образом:
- элементы <MonoC> отображаются на спецификацию <smilText> вместе со всеми соответствующими атрибутами (в частности - с характеристиками языка);
- элементы <SegC> отображаются однозначно на элементы <tev> вместе со всеми соответствующими дескрипторами (особенно - с дескрипторами временного типа).
Процедура вложения многоязычного контента в целостное информационное представление SMIL основана на использовании конструкций <switch> (переключатель) в рамках следующей скелетной схемы:
|

Другие атрибуты, не относящиеся ко времени, как, например, регион, спецификацией MLIF не охватываются и, следовательно, должны формироваться отдельно от MLIF-совместимой структуры.
Возможно и обратное использование отображений - для формирования MLIF-совместимого контента из информационного представления SMIL. Такое применение ассоциируется обычно с подготовкой MLIF-совместимой структуры, которая в дальнейшем должна содержать в себе дополнительные переводы.
Г.4 Отображение элементов smilText на MLIF
Отображение элементов smilText на элементы MLIF выполняются следующим образом*:
_______________
* Используемые определения взяты из рекомендации консорциума W3C по языку SMIL: http://www.w3.orq/TR/2008/REC-SMIL3-20081201/smil-text.html.
- элемент <smilText> функционирует как логический и временной структурирующий компонент, который позволяет включать в SMIL-презентацию внутристрочный текстовый контент. Элемент smilText может также использоваться как внешний автономный синхронизируемый текстовый формат; это достигается путем применения профиля элемента smilText из версии SMIL 3.0;
- элемент <tev> определяет нужный "момент времени" внутри содержимого элемента smilText; в зависимости от значений атрибутов "begin" или "next" он планирует время, в течение которого должен воспроизводиться соответствующий текстовый контент (вплоть до следующего элемента <tev> либо <clear>, или до конца элемента smilText);
- производя отображение на элемент <SegC>, элемент <clear> определяет внутри блока контента smilText "момент времени", в который все блоки контента воспроизводимой области подвергаются очистке.
Перечисленные ниже атрибуты SMIL отображаются следующим образом:
- атрибут "dur" отображается на элемент <duration>;
- атрибут "begin" отображается на элемент <begin>;
- атрибут "next" отображается на элемент <next>.
Приложение Д
(справочное)
Пример использования MLIF для субтитрирования (вставки титров)
Д.1 Введение
Субтитры - это текстовые варианты диалогов в кинофильмах, телевизионных программах, видеоиграх и т.п., отображаемые иногда в нижней части экрана. Они могут представлять собой либо письменное представление диалога на том же языке, либо воспроизведение в письменной форме того же диалога на ином языке по сравнению с исходным языком диалога. В субтитры может включаться дополнительная информация - для оказания помощи глухим или плохо слышащим зрителям в отслеживании происходящего на экране диалога [SUB].
Специалисты по субтитрированию обычно работают со специализированными компьютерными программами и аппаратными средствами, где видеокадры хранятся в оцифрованной форме, благодаря чему нужный кадр отыскивается мгновенно. В дополнение к созданию субтитров такой специалист обычно определяет точные положения, в которых каждый субтитр должен появиться и исчезнуть. Применительно к кинофильму эта задача традиционно решается отдельным техническим персоналом. В конечном итоге создается файл, содержащий текст субтитров и позиционные маркеры, указывающие, когда каждый субтитр появляется и исчезает. Применительно к электронным носителям (телепередачам, видеофильмам и DVD-дискам) эти маркеры обычно шифруются временным кодом, а если субтитры предназначены для обычной кинопленки, то маркеры наносятся по длине ленты (с указанием расстояния в футах или метрах и номеров кадров).
Д.2 Использование MLIF для представления информации субтитров
Существует несколько форматов для субтитров. Одни из них стали стандартами де-юре (как, например, MPEG-4 ТТ), другие же, хотя и не являются стандартами де-юре, широко применяются во всем мире (например, формат SubRip, идентифицируемый расширением SRT). Формат SRT, видимо, наиболее популярен для внешних источников файлов субтитров.
Все форматы субтитров должны обеспечивать тот или иной способ синхронизации видео кадров с показом субтитров. Очевидно, что синхронизация означает привязку временных маркеров к текстовой информации.
Ниже приводится в качестве примера очень короткий фрагмент SRT-файла.
|

В настоящем приложении показывается, каким образом MLIF может использоваться применительно к субтитрам. Примеры Фрагмент-2 и Фрагмент-3 построены в соответствии с самой последней спецификацией SMIL, в частности, smilText.
Возможность использования MLIF для работы с многоязычными субтитрами очевидна, так как анализ любых представляемых MLIF-документов для извлечения SRT-файлов не представляет никаких проблем.
Однако в зависимости от заложенного сценария (или алгоритма) записи информация субтитров может представляться двумя разными способами.
При первом из них (Фрагмент-2) определяется одиночный элемент <MultiC>, и внутрь него вкладываются два элемента <MonoC> следующим образом:
Фрагмент-2:
|

При втором способе MLIF (Фрагмент-3) определяются два элемента <MultiC>, каждый из которых содержит внутри себя одиночный элемент <MonoC> соответствующей структуры:
Фрагмент-3:
|
|

Первый подход может быть более удобен в случае нескольких языковых пар, тогда как второй может оказаться удобней для фильтрации и отбора одного языка (например, можно легко выделить моноязычный блок).
Возможны и другие реализации - в зависимости от того, как должна извлекаться временная информация, ассоциируемая с представлением субтитров. В приведенных ниже примерах атрибуты SMIL используются двумя разными способами: с маркерами <end> (Фрагмент-4) или с маркерами <duration> (Фрагмент-5).
Фрагмент-4
|
Фрагмент-5
|

Д.3 Полномасштабный пример
Д.3.1 Введение
В следующем примере осуществляется привязка SRT-представления с совместимым форматом на базе MLIF.
Д.3.2 Исходные SRT-файлы
Д.3.2.1 Английские субтитры
Английские субтитры имеют вид:
|

Французские субтитры имеют вид:
|

Д.4 MLIF-представление - парные предложения
Результирующие данные MLIF на основе структуры Фрагмента-2 будут выглядеть так:
|

|

Д.5 MLIF-представление сценария вставки заголовков
Результирующие данные MLIF на основе структуры Фрагмента-3 будут выглядеть так:
|

|

Приложение Е
(справочное)
Использование метамодели MLIF для представления данных MAF
Метамодель MLIF может использоваться для включения в контент существующих данных в формате, отличном от MLIF, - например порождаемых процессором естественного языка. Цель приводимого ниже примера состоит в том, чтобы показать, как надо представлять автономную аннотацию, выходящую из процесса морфосинтаксического анализа. Входная информация представляет собой текстовый фрагмент на английском языке "to eventually decide", в котором фигурирует разрывная глагольная форма. Проблема здесь заключается в сохранении положения каждого элемента в потоке словоформ. В следующем XML-фрагменте MLIF включение XML-элементов производится без использования каких-либо трансформаций.
|

Приложение Ж
(обязательное)
Детализированная спецификация
Ж.1 Общие положения
Настоящим стандартом в основном определяются общие принципы построения и применения метамодели MLIF. В приложении Ж подробно рассматриваются различные классы MLIF и отношения, в которых они участвуют.
В данной спецификации каждый компонент метамодели реализуется как конкретный элемент, связывающий определенными отношениями другие элементы, участвующие в реализации метамодели MLIF.
Эта спецификация описывает также ряд категорий данных, который должен рассматриваться как нормативный в рамках любого применения MLIF. Такие категории можно также найти в реестре категорий данных, который ведется техническим комитетом ISO/TC 37 (на веб-странице www.isocat.org).
Ж.2 Классы моделей
Ж.2.1 Класс model.GIPart
model.GIPart | |
Группы элементов, которые могут присоединяться на уровне GI. | |
Использующий элемент | <GI> |
Члены класса | <changeDate> <changeldentifier> <creationDate> <creationldentifier> |
<creationTool> <creationToolVersion> <domain> <formatVersion> <legalStatus> | |
<project> <source> <sourceFormat> <sourceLanguage> <sourceType> | |
<targetLanguage> | |
Ж.2.2 Класс model.GroupCPart
model.GroupCPart | |
Группы элементов, которые могут присоединяться на уровне GroupC. | |
Использующий элемент | <GroupC> |
Члены класса | <groupType> |
Ж.2.3 Класс model.HistoCPart
model.HistoСPart | |
Группы элементов, которые могут присоединяться на уровне HistoCI. | |
Использующий элемент | <HistoC> |
Члены класса | <author> <date> <transaction> <version> |
Ж.2.4 Класс model.I18N
model.I18N | |
Группирует вместе всю информацию, которая может использоваться в приложениях, ориентированных на интернационализацию. | |
Использующий элемент | |
Члены класса | <translate> |
Ж.2.5 Класс model.L10N
model.L10N | |
(Элементы, связанные с локализацией) Отображает информацию для целей локализации. | |
Использующий элемент | |
Члены класса | <matchQuality> <translationRole> <translationStatus> |
Примечание | Основные входные данные принимаются из спецификации XLIFF |
Ж.2.6 Класс model.MonoCPart
model.MonoCPart | |
Группирует элементы, которые могут быть присоединены на уровне MonoC. | |
Использующий элемент | <MonoC> |
Члены класса | <segmentation> <translationRole> |
Ж.2.7 Класс model.MultiCPart
model.MultiCPart | |
Группирует элементы, которые могут быть присоединены на уровне MultiC. | |
Использующий элемент | <MultiC> |
Члены класса | <changeDate> <changeldentifier> <class> <creationDate> <creationldentifier> |
<creationTool> <creationToolVersion> <translationStatus> | |
Ж.2.8 Класс model.SeqCPart
model.SegCPart | |
Группирует элементы, которые могут быть присоединены на уровне SegC. | |
Использующий элемент | <SegC> |
Члены класса | model.inline [<beginPairedTag> <endPairedTag> <genericGroupPlaceholder> |
<genericPlaceholder> <placeholder>] <segmentation> <translate> | |
Ж.2.9 Класс model.inline
model.inline | |
(Внутренние элементы). Группирует информацию, которая может появиться внутри компонента SegC. За исключением элементов <hi> и <sub>, все остальные элементы содержат внутри себя либо замещают любые форматные или управляющие коды, которые не являются текстовыми, но постоянно хранятся в компоненте SegC. | |
Использующий элемент | model.SegCPart |
Члены класса | <beginPairedTag> <endPairedTag> <genericGroupPlaceholder> |
<genericPlaceholder> <placeholder> | |
Примечание | Источник: ТМХ; используется также в XLIFF |
Ж.2.10 Класс model.temporal
model.temporal | |
Группирует вместе все элементы и атрибуты, требуемые для синхронизации временной информации и текстового контента. | |
Использующий элемент | model.MonoCPart model.SegCPart |
Члены класса | <begin> <duration> <end> <next> |
Примечание | Большинство элементов, относимых к этому классу, являются атрибутами в спецификации SMIL. |
Ж.2.11 Класс model.workflow
model.workflow | |
(Элементы, связанные с информационным потоком). Служит для создания контента и управления им. | |
Использующий элемент | |
Члены класса | <changeDate> <changeldentifier> <creationDate> <creationldentifier> |
<creationTool> <creationToolVersion> | |
Ж.3 Классы атрибутов
Ж.3.1 Класс att.classed
att.classed | |||
Определяет иерархию компонента, к которому этот атрибут привязан. | |||
Члены класса | <MonoC> <MultiC> <SegC> | ||
Атрибуты | class | Статус | факультативный |
Тип данных | текст | ||
Ж.3.2 Класс att.id
att.id | |||
Предоставляет общее определение элемента xml:id для однозначной идентификации компонентов в рамках метамодели MLIF. | |||
Члены класса | <HistoC> <MonoC> <MultiC> <SegC> | ||
Атрибуты | xml:id | Статус | факультативный |
Тип данных | текст | ||
corresp | Указывает на эквивалентный текстовой сегмент в другом языке | ||
Статус | факультативный | ||
Тип данных | текст | ||
Примечание | Этот атрибут эквивалентен атрибуту corresp в TEI. | ||
Ж.3.3 Класс att.lang
att.Iang | |||
Предоставляет общее определение элемента xml:lang для описания рабочего языка в метамодели MLIF и соответствующих категорий данных, когда это необходимо. | |||
Члены класса | <MonoC> | ||
Атрибуты | xml:lang | Статус | факультативный |
Тип данных | текст | ||
Ж.3.4 Класс att.linguistic
att.linguistic | |||
Определяет лингвистические атрибуты. | |||
Члены класса | <SegC> | ||
Атрибуты | pos (часть речи) | Указывает грамматическую категорию слова, подлежащего разметке. | |
Статус | факультативный | ||
Тип данных | текст | ||
lemma | Предоставляет абстрактную ссылку на лексическую единицу, которая может ассоциироваться со словом, подлежащим разметке. | ||
Статус | факультативный | ||
Тип данных | текст | ||
tag | Определяет атрибут морфологических свойств, относящийся к словоформе, подлежащей разметке. Конкретное значение должно указывать на определение структур элементов. | ||
Статус | факультативный | ||
Тип данных | текст | ||
Ж.3.5 Класс att.xlink
att.xlink | ||||
Обеспечивает определение всех атрибутов XLink, необходимых для MLIF. | ||||
Члены класса | <MonoC> <SegC> | |||
Атрибуты | label | Помечает ресурс элемента указателя. | ||
Статус | факультативный | |||
Тип данных | text | |||
Примечание | атрибут отслеживания XLink | |||
href | Предоставляет данные для поиска удаленного ресурса. | |||
Статус | факультативный | |||
Тип данных | текст | |||
Примечание | Определяет документ (URI) и указатель XPointer | |||
type | Указывает тип элемента XLink. | |||
Статус | факультативный | |||
Включаемая выборка значений | ||||
simple | Создает простую ссылку. | |||
extended | Создает расширенную ссылку. | |||
locator | Создает ссылку на идентификатор, который указывает на ресурс. | |||
arc | Создает дугу, ведущую к множественным ресурсам, со многими путями отслеживания. | |||
resource | Создает ссылку, указывающую на конкретный ресурс. | |||
title | Создает ссылку на заголовок. Такие элементы полезны для целей интернационализации. | |||
title | Разрешает описание на естественном языке. | |||
Статус | факультативный | |||
Тип данных | текст | |||
from | Идентифицирует исходный ресурс дуги. | |||
Статус | факультативный | |||
Тип данных | текст | |||
Примечание | атрибут отслеживания XLink | |||
to | Идентифицирует целевой ресурс дуги. | |||
Статус | факультативный | |||
Тип данных | текст | |||
Примечание | атрибут отслеживания XLink | |||
Ж.4 Элементы
Ж.4.1 Элемент <GI>
<GI> (Global Information/Глобальная информация) Представляет техническую и административную информацию, применяемую ко всей коллекции многоязычных данных. | |
Использующий элемент | <GroupC> <MLDC> |
Возможное содержание | <HistoC> <changeDate> <changeldentifier> <creationDate> <creationldentifier> |
<creationTool> <creationToolVersion> <domain> <formatVersion> <legalStatus> | |
<project> <source> <sourceFormat> <sourceLanguage> <sourceType> | |
<targetLanguage> | |
Объявление | element Gl {(model.GIPart | <HistoC> )* } |
Примечание | Пример: заголовок коллекции данных, история пересмотра, контекст... |
Ж.4.2 Элемент <GroupC>
<GroupC> (Grouping components/Компоненты группы) Представляет частичную коллекцию многоязычных данных, имеющих общий источник или связанных общим назначением в рамках данного проекта. | |
Использующий элемент | <GroupC> <MLDC> |
Возможное содержание | <GI> <GroupC> <MultiC> <groupType> |
Объявление | element GroupC {<GI>?, model.GroupCPart*, (<GroupC>* | <MultiC>*)} |
Примечание | Эта модель для элемента GroupC не допускает смешения элементов GroupC и SegC. |
Ж.4.3 Элемент <HistoC>
<HistoC> (History Component/Компонент предыстории) Отслеживает изменения того компонента, к которому привязан (т.е. следит за версиями). | |
Дополняет глобальные атрибуты | att.id (@id, @corresp) |
Использующий элемент | <GI> <MonoC> <MultiC> |
Возможное содержание | <author> <date> <transaction> <version> |
Объявление | element HistoC { att.id, model.HistoCPart* } |
Примечание | Пример: автор изменения, дата изменения, номер версии... |
Ж.4.4 Элемент <MLDC>
<MLDC> (Multilingual Data Collection/Многоязычная коллекция данных) Представляет коллекцию данных, в которых содержится глобальная информация и несколько многоязычных блоков. | |
Использующий элемент | |
Возможное содержание | <GI><GroupC> |
Объявление | element MLDC { <GI>?, <GroupC>* } |
Ж.4.5 Элемент <MonoC>
<MonoC> (Monolingual Component/Моноязычный компонент) Группирует информацию, относящуюся к одному языку, и является частью многоязычного компонента (MultiC). | |
Дополняет глобальные атрибуты | att.lang (@lang) att.id (@id, @corresp) att.xlink (@label, @href, @type, @title, @from, @to) att.classed (@class) |
Использующий элемент | <MultiC> |
Возможное содержание | <HistoC> <SegC> <segmentation> <translationRole> |
Объявление | element MonoC |
{ | |
att.lang, | |
att.id, att.xlink, | |
att.classed, | |
<HistoC>*, (<SegC> | model.MonoCPart)* | |
} | |
Ж.4.6 Элемент <MultiC>
<MultiC> (Multilingual Component/Многоязычный компонент) Группирует вместе все варианты данного текстового контента. | |
Дополняет глобальные атрибуты | att.id (@id, @corresp) att.classed (@class) |
Использующий элемент | <GroupC> <MultiC> |
Возможное содержание | <HistoC> <MonoC> <MultiC> <changeDate> <changeldentifier> <class> |
<creationDate> <creationldentifier><creationTool> <creationToolVersion> | |
<translationStatus> | |
Объявление | element MultiC |
{ | |
att.id, | |
att.classed, | |
<HistoC>*, | |
model.MultiCPart*, | |
<MonoC>*, | |
<MultiC>* | |
} | |
Ж.4.7 Элемент <SegC>
<SegC> (Segmentation Component/Сегментирующий компонент) Допускает любой уровень сегментации для текстовой информации, возможно, рекурсивной. | |
Дополняет глобальные атрибуты | att.id (@id, @corresp) att.xlink (@label, @href, @type, @title, @from, @to) |
att.classed (@class) att.linguistic (@pos, @lemma, @tag) | |
Использующий элемент | <MonoC> <SegC> |
Возможное содержание | <SegC> <beginPairedTag> <endPairedTag> <genericGroupPlaceholder> |
<genericPlaceholder> <placeholder> <segmentation> <translate> | |
Объявление | element SegC {att.id, att.xlink, att.classed, att.linguistic, (text | <SegC> | model.SegCPart)* } |
Ж.4.8 Элемент <author>
<author> Указывает имена лиц, ответственных за создание контента. Этот элемент отображается на категорию данных "originator" [ИСО 12620:2009; ТС37 DCR], доступную через каталог ISOCat. | |
Использующий элемент | model.HistoCPart |
Возможное содержание | только символьные данные |
Объявление | element author { text } |
Ж.4.9 Элемент <begin>
<begin> Определяет абсолютное время активизации контролируемого компонента. | |
Использующий элемент | model.temporal |
Возможное содержание | только символьные данные |
Объявление | element begin { текст } |
Ж.4.10 Элемент <beginPairedTag>
<beginPairedTag> (начало парного тега) Отмечает начало парной последовательности внутренних кодов. В рамках сегмента каждому тегу <beginPairedTag> соответствует свой элемент <endPairedTag>. | |
Использующий элемент | model.inline |
Возможное содержание | только символьные данные |
Объявление | element beginPairedTag {text} |
Примечание | Реализуется в ТМХ и XLIFF как <bpt> |
Ж.4.11 Элемент <changeDate>
<changeDate> (изменение даты) Изменяет дату последней модификации контролируемого компонента с использованием формата представления, определенного в ИСО 8601. Этот элемент отображается на категорию данных "modification date" [ИСО 12620:2009; ТС37 DCR], доступную в каталоге ISOCat. | |
Использующий элемент | model.GIPart model.MultiCPart model.workflow |
Возможное содержание | только символьные данные |
Объявление | element changeDate { text } |
Примечание | cp. creationDate |
Ж.4.12 Элемент <changeldentifier>
<changeldentifier> (смена идентификатора) Определяет идентификатор пользователя, который последним внес изменение в контролируемый компонент. Этот элемент отображается на категорию данных "updater" (инициатор изменения) [ИСО 12620:2009; ТС37 DCR], доступную в каталоге ISOCat. | |
Использующий элемент | model.GIPart model.MultiCPart model.workflow |
Возможное содержание | только символьные данные |
Объявление | element changeldentifier {текст} |
Ж.4.13 Элемент <class>
<class> Определяет иерархическое описание компонента, к которому этот элемент привязан. | |
Использующий элемент | model.MultiCPart |
Возможное содержание | только символьные данные |
Объявление | element class { текст } |
Ж.4.14 Элемент <creationDate>
<creationDate> (дата создания) определяет дату создания элемента в формате ИСО 8601. Этот элемент отображается на категорию данных "origination date" [ИСО 12620:2009; ТС37 DCR], доступную в каталоге ISOCat. | |
Использующий элемент | model.GIPart model.MultiCPart model.workflow |
Возможное содержание | только символьные данные |
Объявление | element creationDate { text } |
Пример | Например, запись date="20020125T210600Z" указывает 25 января 2002 года, 9 часов 6 минут вечера по Гринвичу; 2 часа 6 минут дня 25 января 2002 года по горному времени США и 6 часов 6 минут утра 26 января 2002 года по японскому стандартному времени |
Примечание | Дата представлена в формате ИСО 8601. Рекомендуемый для использования шаблон имеет вид: YYYYMMDDThhmmssZ, где YYYY - это год (4 цифры), ММ - месяц (2 цифры), DD - число месяца (2 цифры), hh - часы (2 цифры), mm - минуты (2 цифры), ss - секунды (2 цифры), a Z обозначает всеобщее скоординированное время. |
Ж.4.15 Элемент <creationldentifier>
<creationldentifier> (идентификатор создателя) Определяет идентификатор пользователя, который создал отслеживаемый компонент. Этот элемент отображается на категорию данных "originator" по ИСО 12620:2009; ТС37 DCR, доступную в каталоге ISOCat. | |
Использующий элемент | model.GIPart model.MultiCPart model.workflow |
Возможное содержание | только символьные данные |
Объявление | element creationldentifier { текст } |
Ж.4.16 Элемент <creationTool>
<creationTool> (Creation tool) Идентифицирует инструментарий, с помощью которого был создан контент отслеживаемого компонента. | |
Использующий элемент | model.GIPart model.MultiCPart model.workflow |
Возможное содержание | только символьные данные |
Объявление | element creationTool { текст } |
Ж.4.17 Элемент <creationToolVersion>
<creationToolVersion> (версия инструментария) Идентифицирует номер версии инструментального средства, с помощью которого был создан моноязычный или многоязычный контент. Возможные значения идентификатора версий данным стандартом не определяются, но каждый поставщик инструментальных средств обязан публиковать используемый им строковый идентификатор. | |
Использующий элемент | model.GIPart model.MultiCPart model.workflow |
Возможное содержание | только символьные данные |
Объявление | element creationToolVersion { text ) |
Ж.4.18 Элемент <date>
<date> Определяет дату создания элемента HistoC в формате ИСО 8601. | |
Использующий элемент | model.HistoCPart |
Возможное содержание | только символьные данные |
Объявление | element date { текст } |
Примечание | Дата представляется в формате ИСО 8601. Рекомендуемый для использования шаблон имеет вид: YYYYMMDDThhmmssZ, где YYYY - это год (4 цифры), ММ - месяц (2 цифры), DD - число месяца (2 цифры), hh - часы (2 цифры), mm - минуты (2 цифры), ss - секунды (2 цифры), a Z обозначает всеобщее скоординированное время. |
Ж.4.19 Элемент <domain>
<domain> Определяет предметную область, от которой зависит многоязычная коллекция данных MLDC. | |
Использующий элемент | model.GIPart |
Возможное содержание | только символьные данные |
Объявление | element domain { текст } |
Ж.4.20 Элемент <duration>
<duration> Указывает продолжительность действия отслеживаемого компонента (SegC, MonoC или MultiC), выраженную в обычных единицах времени. | |
Использующий элемент | model.temporal |
Возможное содержание | только символьные данные |
Объявление | element duration { текст } |
Ж.4.21 Элемент <end>
<end> Определяет абсолютное время, когда действие отслеживаемого компонента должно быть прекращено. | |
Использующий элемент | model.temporal |
Возможное содержание | только символьные данные |
Объявление | element end { текст } |
Ж.4.22 Элемент <endPairedTag>
<endPairedTag> (конечный тег пары) Обозначает конец парной последовательности внутренних кодов. Внутри сегмента каждому тегу <endPairedTag> соответствует парный элемент <beginPairedTag>. | |
Использующий элемент | model.inline |
Возможное содержание | только символьные данные |
Объявление | element endPairedTag { text } |
Примечание | Реализуется в ТМХ и XLIFF как <ept> |
Ж.4.23 Элемент <formatVersion>
<formatVersion> Указывает, когда это уместно, соответствующую версию формата, из которого были сформированы данные MLIF совместимого приложения. Эта информация должна использоваться в сочетании с данными sourceFormat. | |
Использующий элемент | model.GIPart |
Возможное содержание | только символьные данные |
Объявление | element formatVersion { text } |
Ж.4.24 Элемент <genericGroupPlaceholder>
<genericGroupPlaceholder> (универсальный групповой заполнитель) Замещает любой код первичного документа, который имеет начало и конец, не перекрывая другие парные внутренние коды, и может перемещаться внутри родительского структурного элемента. | |
Использующий элемент | model.inline |
Возможное содержание | только символьные данные |
Объявление | element genericGroupPlaceholder { текст } |
Примечание | Реализуется в ТМХ и XLIFF как <g> |
Ж.4.25 Элемент <genericPlaceholder>
<genericPlaceholder> (универсальный заполнитель) Замещает любой внутренний код первичного документа. | |
Использующий элемент | model.inline |
Возможное содержание | только символьные данные |
Объявление | element genericPlaceholder { текст } |
Примечание | Реализуется в ТМХ и XLIFF как <х> |
Ж.4.26 Элемент <groupType>
<groupType> (тип группы) Определяет основу для группирования информации MultiC. | |
Использующий элемент | model.GroupCPart |
Возможное содержание | только символьные данные |
Объявление | element groupType { текст } |
Ж.4.27 Элемент <legalStatus>
<legalStatus> Определяет юридический статус организации, которая участвует в создании ресурса, инструментария или услуги, управлении ими или предоставлении доступа к ним. | |
Использующий элемент | model.GIPart |
Возможное содержание | только символьные данные |
Объявление | element legalStatus { текст } |
Ж.4.28 Элемент <matchQuality>
<matchQuality> (соответствие стандартам качества) Указывает уровень качества перевода исходного текста на разные языки, возможно, в процентном выражении или с помощью произвольного неколичественного показателя (например, match-quality="высокое"). | |
Использующий элемент | model.L10N |
Возможное содержание | только символьные данные |
Объявление | element matchQuality { текст } |
Ж.4.29 Элемент <next>
<next> Определяет относительное время активизации, отсчитываемое от момента запуска родительского компонента MonoC или от момента активизации самого последнего компонента SegC в рамках родительского компонента. | |
Использующий элемент | model.temporal |
Возможное содержание | только символьные данные |
Объявление | element next { текст } |
Ж.4.30 Элемент <placeholder>
<placeholder> (заполнитель) Разделяет последовательность внутренних кодов в сегменте, который содержит вложенный текст, подлежащий переводу, или начальную либо конечную часть парных тегов, для которой в рамках сегмента нет соответствующей второй части. | |
Использующий элемент | model.inline |
Возможное содержание | только символьные данные |
Объявление | element placeholder { текст } |
Примечание | Реализуется в ТМХ и XLIFF как <ph> |
Ж.4.31 Элемент <project>
<project> Определяет проект в рамках предметной области, от которой зависит MLDC. | |
Использующий элемент | model.GIPart |
Возможное содержание | только символьные данные |
Объявление | element project { текст } |
Ж.4.32 Элемент <segmentation>
<segmentation> Определяет временные указатели или метки, индицирующие процесс сегментации. | |
Использующий элемент | model.SegCPart model.MonoCPart |
Возможное содержание | пустой элемент |
Ж.4.33 Элемент <source>
<source> Определяет полную цитату библиографической информации, переносимую в документ или в иной ресурс согласно ИСО 12620:1999. | |
Использующий элемент | model.GIPart |
Возможное содержание | только символьные данные |
Объявление | element source { текст } |
Примечание | Ссылка на ресурс, из которого был извлечен данный ресурс |
Ж.4.34 Элемент <sourceFormat>
<sourceFormat> Указывает формат, из которого MLIF-совместимым приложением были сформированы данные MLIF. | |
Использующий элемент | model.GIPart |
Возможное содержание | только символьные данные |
Объявление | element sourceFormat { текст } |
Ж.4.35 Элемент <sourceLanguage>
<sourceLanguage> определяет (в рамках языкового ресурса, ориентированного на перевод, или терминологической базы данных) исходный язык рассматриваемого текста в соответствии с ИСО 12620:1999. | |
Использующий элемент | model.GIPart |
Возможное содержание | только символьные данные |
Объявление | element sourceLanguage { текст } |
Ж.4.36 Элемент <sourceType>
<sourceType> определяет (в рамках многоязычного ресурса, ориентированного на перевод или на управление терминологической базой данных), характер текста, который используется для документирования выборки лексических или терминологических эквивалентов, коллокаций и т.п. | |
Использующий элемент | model.GIPart |
Возможное содержание | только символьные данные |
Объявление | element sourceType { текст } |
Примечание | Для документирования многоязычных терминологических статей в качестве источников информации служат как параллельные, так и предварительно подготовленные тексты. |
Ж.4.37 Элемент <targetLanguage>
<targetLanguage> определяет (в рамках языкового ресурса, ориентированного на перевод, или в рамках терминологической базы данных) язык, на который переводится исходный текст. | |
Использующий элемент | model.GIPart |
Возможное содержание | только символьные данные |
Объявление | element targetLanguage { текст } |
Ж.4.38 Элемент <transaction>
<transaction> представляет один из этапов создания, одобрения и использования конкретного компонента (утверждение, проверка, эксплуатация, импорт данных, ввод данных, модификация, генерация данных, стандартизация, организация пользовательского доступа, извлечение данных). | |
Использующий элемент | model.HistoCPart |
Возможное содержание | только символьные данные |
Объявление | element transaction { текст } |
Ж.4.39 Элемент <translate>
<translate> представляет информацию о том, надо или не надо переводить контент контролируемого компонента SegC. Возможные значения этого элемента - "да" (переводить) и "нет" (не переводить). | |
Использующий элемент | model.I18N model.SegCPart |
Возможное содержание | пустой элемент |
Ж.4.40 Элемент <translationRole>
<translationRole> (переводная роль) определяет в процессе перевода, соответствует ли контролируемый компонент MonoC исходному или целевому языку. | |
Использующий элемент | model.L10N model.MonoCPart |
Возможное содержание | пустой элемент |
Ж.4.41 Элемент <translationStatus>
<translationStatus> (статус перевода) указывает, находится ли компонент MultiC в конкретном состоянии процесса перевода. Одно из возможных значений может быть переменным. | |
Использующий элемент | model.L10N model.MultiCPart |
Возможное содержание | пустой элемент |
Ж.4.42 Элемент <version>
<version> однозначно определяет уникальный номер, используемый для целей управления версиями. | |
Использующий элемент | model.HistoCPart |
Возможное содержание | только символьные данные |
Объявление | element version { текст } |
Приложение ДА
(справочное)
Сведения о соответствии ссылочных международных стандартов национальным стандартам
Таблица ДА.1
Обозначение ссылочного международного стандарта | Степень соответствия | Обозначение и наименование соответствующего национального стандарта |
ISO 12620:2009 | IDT | ГОСТ Р ИСО 12620-2012 "Терминология, другие языковые ресурсы и ресурсы содержания. Спецификация категорий данных и ведение реестра категорий данных для языковых ресурсов" |
ISO 8879 | - | * |
* Соответствующий национальный стандарт отсутствует. До его принятия рекомендуется использовать перевод на русский язык данного международного стандарта. Примечание - В настоящей таблице использовано следующее условное обозначение степени соответствия стандарта: - IDT - идентичный стандарт. | ||
Библиография
[1] | The Object Management Group (OMG); The Unified Modeling Language (UML) Version 2.3. May 2010 |
[2] | TEI Consortium, eds. Guidelines for Electronic Text Encoding and Interchange. November 1, 2007. http://www.tei-c.org/P5/ |
[3] | RUMBAUGH, J., JACOBSON, I. and BOOCH, G. The unified modeling language reference manual, 2nd ed., Addison Wesley, 2004 |
[4] | Википедия http://en.wikipedia.org/wiki/Subtitle (captioning) по сост. на 2 октября 2009 г. |
[5] | ИСО 24611, Управление языковыми ресурсами. Система морфосинтаксического аннотирования |
[6] | ИСО 12620, Терминология, другие языковые ресурсы и ресурсы содержания. Спецификация категорий данных и ведения реестра категорий данных для языковых ресурсов |
[7] | ИСО 16642:2003, Применение компьютера в терминологических целях. Структура терминологической разметки |
[8] | ИСО 24615, Управление языковыми ресурсами. Система синтаксического аннотирования (SynAF) |
[9] | ИСО 8601:2004, Элементы данных и форматы для обмена информацией. Обмен информацией. Представление дат и времени |
[10] | W3C, Date and Time Formats: http://www.w3.org/TR/NOTE-datetime по сост. на 7 мая 2010 г. |
[11] | ИСО/МЭК 14496-17:2006, Информационные технологии. Кодирование аудиовизуальных объектов. Часть 17. Формат потокового текста |
[12] | Organization for the Advancement of Structured Standards (OASIS); XML Localization Interchange File Format (XLIFF), версия 1.2 от 1 февраля 2008 г. |
[13] | Open Standard Codes and Routines (OSCAR); The Translation Memory Exchange (TMX) версия 1.4b. апрель 2004. The Localisation Industry Standards Association (LISA)* |
_______________
* В марте 2011 г. Ассоциация отраслевых стандартов локализации LISA (Localization Industry Standards Association) была объявлена несостоятельным должником. В результате этого портфель стандартов LISA было решено передать некоммерческой творческой организации Creative Commons Attribution в рамках открытой лицензии 3.0 License, которая разрешает повторно использовать и создавать производные документы на базе стандартов LISA. Следует отметить, что LISA назначила своим правопреемником портфеля стандартов Группу промышленных спецификаций (ISG) в области стандартов локализации (LIS) Европейского института телекоммуникационных стандартов (ETSI).
УДК 001.4:006.354 | ОКС 01.020 |
Ключевые слова: управление языковыми ресурсами, многоязычная информационная система, обобщенные атрибуты, детализированная спецификация, терминология | |
Электронный текст документа
и сверен по:
, 2020

{kind=link}