ГОСТ Р ИСО 1951-2012
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Представление и изложение словарных статей. Требования, рекомендации и информация
Presentation and representation of entries in dictionaries. Requirements, recommendations and information
ОКС 01.020, 01.080.99
Дата введения 2014-01-01
Предисловие
1 ПОДГОТОВЛЕН ЗАО "Проспект" на основе собственного аутентичного перевода на русский язык международного стандарта, указанного в пункте 4
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 55 "Терминология, элементы данных и документация в бизнес-процессах и электронной торговле"
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 20 ноября 2012 г. N 966-ст
4 Настоящий стандарт идентичен международному стандарту ИСО 1951:2007* "Представление и изложение словарных статей. Требования, рекомендации и информация" (ISO 1951:2007 "Presentation/representation of entries in dictionaries - Requirements, recommendations and information").
________________
* Доступ к международным и зарубежным документам, упомянутым в тексте, можно получить, обратившись в Службу поддержки пользователей. - .
При применении настоящего стандарта рекомендуется использовать вместо ссылочных международных стандартов соответствующие им национальные стандарты Российской Федерации, сведения о которых приведены в дополнительном приложении ДА
5 ВВЕДЕН ВПЕРВЫЕ
Правила применения настоящего стандарта установлены в ГОСТ Р 1.0-2012 (раздел 8). Информация об изменениях к настоящему стандарту публикуется в ежегодном (по состоянию на 1 января текущего года) информационном указателе "Национальные стандарты", а официальный текст изменений и поправок - в ежемесячном информационном указателе "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ближайшем выпуске ежемесячного информационного указателя "Национальные стандарты". Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет (gost.ru)
Введение
За последние 10 лет процессы создания словарной продукции претерпели важные изменения по причине широкого распространения электронных словарей. Вследствие этого лексикографы оказались перед фактом огромного разнообразия методов разработки и публикации словарей.
Настоящий стандарт имеет целью информационную поддержку процессов создания и организации использования самых разных типов словарной продукции. При этом принимаются во внимание различные способы применения словарей, в особенности такие, которые связаны с новыми функциональными возможностями электронных документов - гиперссылками.
Для того, чтобы сделать информационное содержимое словарей многократно используемым в разных печатных и электронных форматах, лексикографы постоянно стремятся создать надлежащую единую, четко структурированную лексикографическую первооснову или информационный репозиторий. В настоящем стандарте предлагается конкретная модель, основанная на профессиональном опыте и лучших достижениях сложившейся практики и призванная способствовать дальнейшему совершенствованию процедур создания, взаимообмена и организации эффективного использования словарей.
1 Область применения
Настоящий стандарт касается одноязычных и многоязычных общих и отраслевых словарей. Он определяет формализованную общую структуру, не зависящую от носителя информации, и устанавливает способы и средства представления статей в "бумажных" и электронных словарях. Связь между этой формальной структурой и представлениями словарных статей, которые используются издателями и читаются пользователями, поясняется примерами, рассмотренными в информативных приложениях.
Цель данного стандарта состоит в том, чтобы облегчить задачи создания, слияния, сравнения, поиска, информационного обмена, распространения и извлечения лексикографических словарных данных. В стандарте используется лексикографический подход к проблеме, основанный на выработке рекомендаций и не имеющий отношения к концептуальным разработкам, определенным в стандарте ИСО 704.
2 Нормативные ссылки
В настоящем стандарте использованы нормативные ссылки на следующие стандарты*, которые необходимо учитывать при использовании настоящего стандарта. В случае ссылок на документы, у которых указана дата утверждения, необходимо пользоваться только указанной редакцией. В случае, когда дата утверждения не приведена, следует пользоваться последней редакцией ссылочных документов, включая любые поправки и изменения к ним.
_______________
* Таблицу соответствия национальных стандартов международным см. по ссылке. - .
ИСО 704:2000 Терминологическая работа. Принципы и методы (ISO 704:2009, Terminology work - Principles and methods)
ИСО 1087-1:2000 Терминологическая работа. Словарь. Часть 1: Теория и применение (ISO 1087-1:2000, Terminology work - Vocabulary - Part 1: Theory and application)
3 Термины и определения
В настоящем стандарте использованы следующие термины с соответствующими определениями:
3.1 комментарий (comment): Металингвистическая информация, описывающая лексическую единицу с помощью лексикографических элементов данных или составных элементов.
3.2 составной элемент (component element): Составной информационный объект, образованный элементами.
Примечание - Существуют три семейства составных элементов: блоки, контейнеры и группы.
3.3 блок (block): Разложимая структура данных, составной элемент, служащий для факторизации элементов, которые используются множеством экземпляров конкретного элемента в качестве общих уточнений.
Примечание - Примеры блоков приведены в таблицах 6-14.
3.4 контейнер (container): Уточняющая структура, составной элемент, используемый для предоставления дополнительной информации об одном конкретном элементе данных с помощью других элементов.
Пример - Контейнер заглавного слова, используемый для представления его произношения или указания части речи и уточняющий таким образом заглавное слово, которое само по себе является уточненным элементом данных.
3.5 группа (group): Составной элемент, используемый для объединения нескольких независимых элементов.
Пример - Смысл понятия описывается группой элементов, таких как определение, предметная область и др.
Примечание - Пример группы представлен в таблицах 15 и 16.
3.6 элемент данных (data element): Единица информации определенной категории, для которой с помощью набора признаков заданы определение, идентификатор, форма представления и диапазон допустимых значений.
[ИСО/МЭК 11179-1:2004, определение 3.3.8]
Примечание - Списки элементов данных представлены в таблицах 1 и 2.
3.7 словарная статья (dictionary entry): Лексический вход, часть словаря, которая содержит информацию, относящуюся к одной лемме и ее вариантам.
3.8 элемент (element): Любой элемент данных или составной элемент.
3.9 заглавное слово (headword): Слово лексического входа, лемма, которая служит заголовком для статьи в словаре.
3.10 лемма (lemma): Базовое слово, лексическая единица, выбранная в соответствии с лексикографическими соглашениями о представлении различных форм инфлективной парадигмы.
Пример - "Продавать" - это лемма парадигмы "продает, продал, продающий и т.д.".
3.11 лексическая единица, лексема (lexical unit): Языковая единица, принадлежащая к лексикону данного языка и описанная или упомянутая в словаре.
3.12 лексикографический символ (lexicographical symbol): Буква, знак пунктуации или иной типографский либо графический символ или группа символов, равно как их комбинация, используемые для представления определенных лексикографических или терминологических данных, которые отображаются или выводятся автономно либо в сочетании с другим элементом лексикографических данных.
3.13 гнездовая рубрика (nested entry): Группирующая структура для родственных словарных статей с общим заглавным словом.
4 Формализованное описание словарных статей
Для большей четкости изложения рассматриваемая ниже формализованная модель, именуемая в дальнейшем как XmLex, иллюстрируется короткими примерами, запрограммированными в соответствии с документом, касающимся определения типов данных в языке XML и носящим имя XmLex_V00 (более подробную информацию см. в справочном приложении С). |
4.1 Общий обзор элементов данных и композиционных элементов
Словарные статьи могут рассматриваться как комментарии к определенным темам, образующим лексические единицы словаря. Статья имеет главную тему (определяемую заглавным словом); все другие темы (например, варианты, переводы) называются "зависимыми темами". Темы и комментарии являются элементами данных. Каждому элементу данных соответствует модель информационного содержания (контента). Элементы данных группируются в композиционные элементы для создания непротиворечивого и полностью поддающегося вычислительной обработке лексического входа. Приводимые ниже открытые списки элементов данных и композиционных элементов могут расширяться пользователем в соответствии с конкретными целями.
В словарях, издаваемых типографским способом, для определения связей между темами и комментариями, как правило, соблюдаются определенные типографские соглашения (использование обычного, полужирного и курсивного шрифтов); соглашения по размещению (до/после) и по знакам пунктуации (запятая и точка с запятой). В модели XmLex:
- положение элемента никогда не используется для обозначения связи между двумя элементами;
- не существует никаких маркеров, эквивалентных типографским знакам (запятой и точке с запятой).
Композиционные элементы (контейнеры, блоки и группы) используются для кодирования логических зависимостей между комментариями и темами таким образом, что, с одной стороны, всегда имеется возможность автоматически скомпоновать и выдать на печать любую форму, а, с другой стороны, автоматически "просчитать" все взаимосвязи между элементами в случае преобразования данных (например, для обращения двуязычного словаря) или при повторном использовании данных в иных контекстах, например, в среде систем памяти переводов или лексических баз данных.
В данной части стандарта:
- описываются элементы данных и их объединение в композиционные элементы, необходимые для представления наиболее общих словарных статей;
_______________
Каждому элементу данных присваивается условное имя и описание, которое должно в максимально возможной степени отвечать требованиям стандарта ISO 12620:1999. Произвольные элементы данных, тип которых определяется пользователем, позволяют осуществить расширение модели на ситуации "договорного информационного обмена".
- определяется формализованная модель словаря в расширенном представлении Бэкуса - Наура, которое часто используется в качестве формальной нотации для описания синтаксической структуры данного языка;
- даются в приложениях примеры реализации и средства контроля, основанные на использовании спецификаций XML, Xpointer, XSL и XHTML.
4.1.1 Элементы данных
4.1.1.1 Лексические единицы
Представленная ниже таблица содержит перечень лексических единиц и комментариев, которые следует использовать в стандартизованной словарной статье.
В первом столбце таблицы дается обозначение элемента данных. Второй столбец показывает групповой идентификатор этого элемента в рамках формализованной модели. В третьем столбце приводится короткое пояснение, а в четвертом - помещена ссылка на первый соответствующий пример (если таковой существует) элемента данных в приложениях (буква обозначает приложение, подчеркнутый номер указывает номер примера, а последний номер определяет нужную строку).
Таблица 1 - Список лексических единиц
Имя | Групповой идентификатор | Пояснение | См. приложение пример |
сокращенная форма | AbbreviatedForm | Лексическая единица, образованная путем удаления отдельных слов или букв из более длинной формы [...]. | С |
аналогия | Analogy | Лексическая единица, имеющая некоторое сходство по смысловому содержанию с текущей лексической единицей. | С |
антоним | Antonym | Лексическая единица, которая представляет понятие, противоположное по смыслу текущей лексической единице. | С |
композиционная фраза | CompositionalPhrase | Любое многократно повторяющееся общепринятое словосочетание, такое как коллокация, пословица, поговорка и т.п. | С |
словообразование | Derivation | Изменение формы лексической единицы, обычно выражающееся в модифицировании корневой основы или аффиксации и сигнализирующее об изменении информации о части речи. | С |
пример | Example | Экземпляр, типичный для применения лексической единицы в определенном контексте. | С |
ложный друг | FalseFriend | Лексическая единица языка, кажущаяся формальным или семантическим подобием лексической единице другого языка, но не соответствует ей по смыслу. | С |
произвольная тема | FreeTopic | Лексическая единица, тип которой в данном международном стандарте не определен. | С |
полная форма | FullForm | Полная форма представления лексической единицы, для которой существует сокращенная форма. | С |
заглавное слово | Headword | Лемма, являющаяся заголовком словарной статьи. | С |
инфлексия | Inflection | Модификация формы слова для выражения других грамматических связей, в которых оно может участвовать. | С |
международный научный термин | IntemationalScientificTerm | Термин, являющийся частью научной терминологии, принятой соответствующим научным распорядительным органом. | С |
многословная лексическая единица | MultiWordUnit | Лексическая единица, состоящая из нескольких слов и выражающая только одно понятие. | С |
символ | Symbol | Обозначение некоторого понятия буквами, числами, пиктограммами или любой их комбинацией. | С |
синоним | Synonym | Лексическая единица, которая представляет то же самое или очень близкое понятие, что и заглавное слово словарной статьи. | С |
перевод | Translation | Эквивалентная лексическая единица, принадлежащая целевому языку перевода. | С |
вариант | Variant | Одна из альтернативных форм лексической единицы. | С |
Таблица 2 - Список комментариев
Имя | Групповой идентификатор | Пояснение | См. приложение пример |
Засвидетельст- | Attestation | Дата или время просмотра лексической единицы. | С |
падеж | Case | Грамматическая форма лексической единицы (существительное, местоимение или модификатор), указывающая на ее грамматическую связь с другими словами в статье или предложении. | С |
цитата | Citation | Цитата из книги, статьи или документа. | С |
дополнение | Complement | Вспомогательная часть лексической единицы (например, предлог "to" с английским глаголом). | |
определение | Definition | Предложение, которое описывает некоторое понятие и позволяет отличать его от других понятий в рамках системы концептов. | С |
отображение | Display | Синтезированный текст, который может показываться вместо раздельного представления тем или комментариев. | С |
этимология | Etymology | Информация о происхождении конкретного слова и эволюции его смыслового значения. | С |
формула | Formula | Цифры, символы или иные средства краткого выражения понятия, как, например, математическая или химическая формула. | С |
частота | Frequency | Характеристика относительной интенсивности и общности использования лексической единицы. | С |
свободный комментарий | FreeComment | Металингвистические средства, используемые для описания лексической единицы. | С |
география применения | GeographicalUsage | Использование лексической единицы, отражающее региональные различия. | С |
грамматический род | GrammaticalGender | Совокупность из двух или более грамматических категорий, на которые разделяются имена существительные конкретного языка. | С |
грамматическое число | GrammaticalNumber | Во многих языках - грамматический признак различия, который указывает на количество объектов, определяемых данной лексической единицей. | С |
грамматическая структура | GrammaticalPattern | Грамматическая конструкция, в которой часто встречается конкретная лингвистическая единица. | С |
направляющая фраза | GuidePhrase | Грамматический оборот, иллюстрирующий случай употребления слова или его конкретного смыслового значения. | С |
вставка | Insert | Текст, таблица или рисунок, которые представляют некоторые грамматические, энциклопедические, научные или культурологические сведения, относящиеся к словарной статье или к нескольким словарным статьям. Такая вставка может совершенно не зависеть от текста словаря. | |
наклонение | Mood | Свойство глаголов, выражающее отношение говорящего к реальности или правдоподобию того, о чем идет речь. | С |
нормативный статус | NormativeStatus | Указатель статуса термина, присвоенный полномочным органом власти, таким как организация по стандартизации или государственным регуляционным учреждением. | С |
примечание | Note | Дополнительная информация, касающаяся любого другого элемента совокупности данных. | С |
часть речи | PartOfSpeech | Тип, присвоенный лексической единице на основании ее грамматических и семантических свойств. | С |
лицо | Person | Индикатор грамматического лица (1-го, 2-го, 3-го и т.п.), ассоциируемого с данной изменяемой лексической единицей. | С |
произношение | Pronunciation | Представление артикуляции при произнесении лексической единицы. | С |
область применения | RangeOfApplication | Область, в рамках которой сохраняется истинный смысл конкретного понятия. | С |
регистр | Register | Классификация, показывающая относительный уровень языка, присвоенный конкретной лексической единице. | С |
поисковая форма | SearchForm | Лексическая единица, добавленная к лексическому входу с целью облегчения процедуры поиска. | С |
смотри | See | Перекрестная ссылка на другое заглавное слово, которое является синонимом текущего заглавного слова. | С |
смотри также | SeeAlso | Перекрестная ссылка на родственное заглавное слово. | С |
спецификатор эмоциональной окраски | SenseQualifier | Любой указатель эмоциональной окраски лексической единицы ("фигуральный", "буквализм", "устаревший"...). | С |
сортировочный ключ | SortKey | Лексическая единица, которая вводится в лексикографическую статью для целей удобства сортировки, когда порядок расположения статей не позволяет отследить местоположение нужного словосочетания. | |
исходный язык | SourceLanguage | Язык лексической единицы, которая должна быть переведена на другой язык. | С |
субкатегоризация | Subcategorisation | Приписывание лексического объекта к подклассу его части речи, особенно в тех случаях, когда учитываются синтаксические элементы, с которыми он может сочетаться. | С |
предметная область | SubjectField | Область человеческих знаний. | С |
слогоделение | Syllabification | Разделение слова на слоги, отражающее его артикуляцию по слогам, то есть по неделимым элементам произношения. | С |
целевой язык | TargetLanguage | Язык, на который должна быть переведена лексическая единица. | С |
грамматическое время | Tense | Отличительный признак в виде разных форм глагола для выражения различий во времени или продолжительности выполнения обозначаемого этим глаголом действия или состояния. | С |
4.1.2 Иерархические структуры: словарь и словарные статьи
Словарь состоит из обычных или гнездовых статей.
Таблица 3 - Список высокоуровневых структур
Имя | Групповой идентификатор | Пояснение | См. приложение пример |
словарь | Dictionary | Совокупность словарных статей или гнездовых рубрик. | С |
словарная статья | DictionaryEntry | См. определение 3.4. | С |
гнездовая рубрика | NestEntry | См. определение 3.10. | D |
Статья в словаре состоит из элементов данных, которые самодостаточны или компонуются в рамках композиционных элементов.
4.1.3 Композиционные элементы
4.1.3.1 Контейнеры
Всюду, где это возможно, кодированному примеру на языке XML предшествует его печатный вид, взятый из реального словаря. В данном случае вся словарная статья полностью представляется на бумаге текстом внутри прямоугольника с серым фоном (на экране - это зеленый цвет). Если кодируются только какие-то части статьи, то на бумаге они [в данном случае - это текст "Farad n (F) DIN 1301"] располагаются на белом фоне (на экране - это желтый цвет). |
Контейнер определяется в приложении С.4.5 стандарта ISO 16642:2003 как структура, используемая при необходимости уточнения соответствующего элемента данных с помощью других информационных элементов (для заглавного слова - это его часть речи; для цитаты - это имя автора цитируемых слов; для символического обозначения - его источник и т.п.). Пример контейнера приводится в таблице 4.
Таблица 4 - Исходные данные (пример 23 из приложения С)
![]()
Хотя в данном англо-немецком словаре слова "Farad", "n", "F" и "DIN 1301" напечатаны в одну строку, между этими элементами существуют зависимости следующего характера:
[Фарада ("Farad") - это имя существительное ("noun"), обозначается символом "F" в соответствии со стандартом "DIN 1301"]
Таблица 5 - Кодовое представление (пример 23 из приложения С)

Контейнер перевода (<TranslationCtn>) используется для уточнения перевода (Farad) путем указания его части речи (<PartOfSpeech>). Контейнер символа (<SymbolCtn>) используется для уточнения символа (F) посредством указания его источника (DIN 1301). Этот контейнер символа встроен в контейнер перевода для добавления к переводу символического обозначения.
4.1.3.2 Блоки
В издаваемых типографским способом словарях часто используются знаки пунктуации (запятая или точка с запятой) для обозначения степени схожести элементов статьи. Например, в таблице 6 слово "feelings" ("чувства") в квадратных скобках, которое стоит перед двумя переводами, разделенными запятой, определяет "область использования" этих двух переводов. Точка с запятой закрывает список возможных переводов слова "dam" в рамках области "feelings". Заключенное в квадратные скобки слово "Words" ("разговорная речь") открывает новую "область использования".
Блоки используются для кодирования характера такой логической связи.
Таблица 6 - Исходные данные - блок с базовыми компонентами (англо-французский пример 1 из приложения С)

Таблица 7 - Схематическое представление блоков с базовыми компонентами

Здесь имеются три родственных узла <Translation>. Блок TranslationBlock используется для объединения двух из этих узлов в одну группу, где они разделяют одну и ту же область использования <RangeOfApplication>.
Таблица 8 - Кодовое представление блока с базовыми компонентами (пример 1 из приложения С)

Таблица 9 - Исходные данные - блок с контейнерами
![]()
Здесь имеются три производные формы прошедшего времени глагола "cleave" (раскалывать) и три формы причастия прошедшего времени от этого глагола. Каждая производная форма может быть уточнена указанием для нее произношения или регистра.
Таблица 10 - Схематическое представление блока с контейнерами

Таблица 11 - Кодовое представление блока с контейнерами

Таблица 12 - Исходные данные производного блока

Таблица 13 - Схематическое представление производного блока
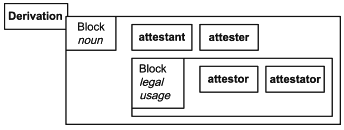
Блок <DerivationBlock> используется для ассоциирования уточнения <PartOfSpeech> с четырьмя производными блоками <Derivation>. Вложенный блок <DerivationBlock> используется для объединения в группу двух последних производных блоков, разделяющих одну и ту же область использования <RangeOfApplication>.
Модель XmLex определяет блоки для семи тем: CompositionalPhrase (композиционная фраза), Derivation (производный элемент), Headword (заглавное слово), Inflection (изменение формы слова), MultiWordUnit (многословная единица), Synonym (синоним) и Translation (перевод).
Таблица 14 - Кодовое представление вложенного производного блока

4.1.3.3 Группы
Группа объединяет независимые элементы данных, контейнеры и блоки.
Группа является композиционным элементом, который используется для представления различных (и повторяющихся) наборов информации, например, множественных смысловых значений заглавного слова в рамках словарной статьи.
Таблица 15 - Пример группы (фрагмент примера 3 из приложения С)
![]()
Таблица 16 - Кодовое представление (фрагмент примера 3 из приложения С)

В соответствии с предметной областью заглавное слово имеет два смысловых значения. Каждое из них описывается в группе <SenseGroup>.
Таблица 17 - Список групп
Имя | Групповой идентификатор | Пояснение | См. приложение пример |
омографическая группа | HomographGroup | Группирующий элемент для описания омографов. | С |
смысловая группа | SenseGroup | Группирующий элемент для описания одного смыслового значения заглавного слова в словарной статье. См. определение 3.2.3. | С |
4.2 Формальная структура словарной статьи
4.2.1 Формальная грамматика для высокоуровневых структур
Словарная статья включает в себя:
- одну или несколько основных лексических единиц ("заглавных слов") и связанные с ними другие лексические единицы (часть речи, произношение, орфографические варианты, словообразование и т.п.);
- описание каждого смыслового значения заглавных слов и лексических единиц, ассоциируемых с данным значением (композиционных фраз, многословных единиц, переводов, синонимов и др.).
Когда заглавное слово имеет сильно различающиеся смысловые значения, словарная статья может разбиваться на подстатьи по каждому омографу или для каждого значения может создаваться отдельная статья (с соответствующим номером омографа).
Несколько статей могут группироваться внутри уникального "гнезда" для сборки родственных заглавных слов в компактный словарь.
Модель представляется с использованием следующих соглашений расширенной формы Бэкуса - Наура (РБНФ):
- терминальные элементы являются существительными без разделителей; их объяснение дается до начала использования (примером может служить заглавное слово);
- символы разделяются знаками <>;
- {} обозначает любое число вхождений, включая 0;
- [ ] обозначает отсутствие или ровно одно вхождение;
- + означает одно или множество вхождений.
Необходимо помнить, что:
- порядок следования элементов внутри правила не имеет значения; например, внутри контейнера повторяющиеся уточняющие элементы могут появляться как до, так и после уточняемого элемента данных;
- символы, имя которых заканчивается словом "Value" (значение), как, например, <GrammaticalGenderValue>, или словом "Туре" (тип), как <HeadwordType>, в настоящем международном стандарте не рассматриваются; они относятся к допустимым значениям, которые определены в ISO 12620:1999 и в "Реестре категорий данных Технического комитета 37" (ТС 37 Data Category Registry).
Для элемента данных разрешаются списки допустимых значений. Например, элемент грамматического рода <GrammaticalGenderValue> может содержать значения "мужской", "женский", "средний" и т.п.
Определение типов дает дополнительную информацию о характере элемента данных. Например, <HeadwordType> будет содержать перечисление типов заглавных слов (имя нарицательное, имя собственное, приставка, суффикс, географическое название и др.).
Реализация этой модели всегда дает пользователю возможность добавлять собственные новые типы или нужные ему допустимые значения.
- Описание цитирования (CitationCtn) в настоящем стандарте отсутствует. Его компоненты следует заимствовать в ISO 15836 (Дублинское ядро) или ISO 12615 (ссылки на источники).
1. | <Dictionary> ::= |
<generalQualifiers> | |
[sourceLanguage] | |
[targetLanguage] | |
{<DictionaryEntry> | <NestEntry> | <lnsert>} | |
2. | <NestEntry> ::= |
<generalQualifiers> | |
[sourceLanguage] | |
[targetLanguage] | |
{DictionaryEntry>} | |
3. | <DictionaryEntry> ::= |
[sortKey] | |
[sourceLanguage] | |
[targetLanguage] | |
[homographNumber] | |
<generalQualifiers> | |
(Headword| HeadwordCtn| HeadwordBlock)+ | |
{HomographGroup} | {SenseGroup} | |
{MultiWordUnitCtn | CompositionalPhraseCtn| | |
{<Administrativelnformation>} | |
4. | <HomographGroup> ::= |
<generalQualifiers> | |
[Headword| HeadwordCtn| HeadwordBlock] | |
{<CoreComments> | <SenseGroup>} | |
{<RelatedTopics>} | |
5. | <SenseGroup> ::= |
<generalQualifiers> | |
[senseNumber] | |
[targetLanguage] | |
{<CoreComments>| | |
<RelatedTopics>| | |
<SenseGroup>} | |
(See|SeeCtn) | |
6. | <RelatedTopic> ::= |
{AbbreviatedForm| <AbbreviatedFormCtn> | |
Analogy |<AnalogyCtn>| <AnalogyBlock>| | |
Antonym| <AntonymCtn> | |
Citation| <CitationCtn>| | |
CompanySpecificUsage| CompanySpecificUsageCtn| | |
CompositionalPhrase| <CompositionalPhraseCtn>| | |
<CompositionalPhraseBlock>| | |
Derivation|<DerivationCtn>|<DerivationBlock>| | |
Example|<ExampleCtn>| | |
FalseFriend|<FalseFriendCtn>| | |
FreeTopic|<FreeTopicCtn>| | |
FullForm|<FullFormCtn>| | |
Homonym| HomonymCtn| | |
lnflection|<lnflectionCtn>|<lnflectionBlock>| | |
lntemationalScientificTerm|<lnternationalScientificTermCtn>| | |
MultiWordUnit|<MultiWordUnitCtn>|<MultiWordUnitBlock>| | |
ProprietaryRestriction| ProprietaryRestrictionCtn| | |
Synonym|<SynonymCtn>|<SynonymBlock>| | |
Translation|<TranslationCtn>|<TranslationBlock>| | |
Variant|<VariantCtn>} | |
7. | <HeadwordCtn> ::= <generalQualifiers> Headword |
{<CoreComments>| <RelatedTopics>} | |
8. | <HeadwordBlock> ::= <generalQualifiers> (Headword | |
HeadwordCtn)+ | |
{<CoreComments>} | |
9. | <MultiWordUnitCtn> ::= <generalQualifiers> MultiWordUnit+ |
{<CoreComments>| <RelatedTopics>} {<SenseGroup>} | |
10. | <CompositionalPhraseCtn> ::= <generalQualifiers> |
CompositionalPhrase+ {<CoreComments>| <RelatedTopics>} | |
{<SenseGroup>} | |
11. | <LinguisticComment> ::= |
Attestation|< AttestationCtn >| | |
Case|<CaseCtn>| | |
Complement|<ComplementCtn>| | |
Display| | |
Etymology|<EtymologyCtn>| | |
Formation|<FormationCtn>| | |
Formula|<FormulaCtn>| | |
Frequency|<FrequencyCtn>| | |
GeographicalUsage|<GeographicalUsageCtn>| | |
GrammaticalGender|<GrammaticalGenderCtn>| | |
GrammaticalNumber|<GrammaticalNumberCtn>| | |
GrammaticalPattern| GrammaticalPatternCtn| | |
GuidePhrase|<GuidePhraseCtn>| | |
Mood|<MoodCtn>| | |
NormativeStatus|<NormativeStatusCtn>| | |
PartOfSpeech|<PartOfSpeechCtn>| | |
Person|<PersonCtn>| | |
Pronunciation|<PronunciationCtn>| | |
RangeOfApplication|<RangeOfApplicationCtn>| | |
Register|<RegisterCtn>| | |
SearchForm|<SearchFormCtn>| | |
Syllabification|<SyllabificationCtn>| | |
Symbol|<SymbolCtn>| | |
TypicalComplement| TypicalComplementCtn| | |
Tense|<TenseCtn>| | |
UsageNote|<UsageNoteCtn> | |
12. | <SemanticComment> ::= |
13. | <CoreComments> ::= {<LinguisticComments>| <SemanticComments>| |
14. | <CrossReferences> ::= SeeAlso |
15. | <Administrativelnformation> ::= Origination | Modification |
16. | <FreeElements> ::= FreeComment| <FreeCommentCtn> |
17. | <GeneralElements> ::= Note| <NoteCtn>| Source| <SourceCtn> |
18. | <ContainerComplement> ::= <FreeElements>| <GeneralElements> |
19. | <generalQualifiers> ::= [id] [class] [style] [xmhl:lang] |
4.2.2 Формальная грамматика для контейнеров других лексических единиц
20. | <AbbreviatedFormCtn> ::= <generalQualifiers> AbbreviatedForm |
21. | <AnalogyCtn> ::= <generalQualifiers> Analogy {<CoreComments>| |
22. | <AntonymCtn> ::= <generalQualifiers> Antonym {<CoreComments>| |
23. | <DerivationCtn> ::= <generalQualifiers> Derivation |
24. | <ExampleCtn> ::= <generalQualifiers> Example {<CoreComments>| |
25. | <FalseFriendCtn> ::= <generalQualifiers> FalseFriend |
26. | <FreeTopicCtn> ::= <generalQualifiers> FreeTopic |
27. | <FullFormCtn> ::= <generalQualifiers> FullForm |
28. | <lnflectionCtn> ::= <generalQualifiers> Inflection |
29. | <lnternationalScientificTermCtn> ::= <generalQualifiers> |
30. | <SearchFormCtn> ::= <generalQualifiers> SearchForm |
31. | <SynonymCtn> ::= <generalQualifiers> Synonym {<CoreComments>| |
32. | <TranslationCtn> ::= <generalQualifiers> Translation |
33. | <VariantCtn> ::= <generalQualifiers> Variant {<CoreComments>| |
4.2.3 Формальная грамматика для блоков
34. | <AnalogyBlock> ::= <generalQualifiers> (Analogy| AnalogyCtn>| |
35. | <CompositionalPhraseBlock> ::= <generalQualifiers> |
36. | <DerivationBlock> ::= <generalQualifiers> (Derivation| |
37. | <HeadwordBlock> ::= <generalQualifiers> (Headword| |
38. | <lnflectionBlock> ::= <generalQualifiers> (Inflection| |
39. | <MultiWordUnitBlock> ::= <generalQualifiers> |
40. | <SynonymBlock> ::= <generalQualifiers> |
41. | <TranslationBlock> ::= <generalQualifiers> |
42. | <VariantBlock> ::= <generalQualifiers> |
4.2.4 Формальная грамматика для контейнеров других комментариев
43. | <AttestationCtn> ::= <generalQualifiers> Attestation |
44. | <CaseCtn> ::= <generalQualifiers> Case { Example| ExampleCtn| |
45. | <DefinitionCtn> ::= <generalQualifiers> Definition |
46. | <EtymologyCtn> ::= <generalQualifiers> Etymology |
47. | <FormulaCtn> ::= <generalQualifiers> Formula [Source] |
48. | <FreeCommentCtn> ::= <generalQualifiers> FreeComment |
49. | <FrequencyCtn> ::= <generalQualifiers> Frequency |
50. | <GeographicalUsageCtn> ::= <generalQualifiers> |
51. | <GuidePhraseCtn> ::= <generalQualifiers> GuidePhrase |
52. | <GrammaticalGenderCtn> ::= <generalQualifiers> |
53. | <GrammaticalNumberCtn> ::= <generalQualifiers> |
54. | <GrammaticalPatternCtn> ::= <generalQualifiers> |
55. | <lnsertCtn> ::= <generalQualifiers> Insert |
56. | <MoodCtn> ::= <generalQualifiers> Mood {Example| ExampleCtn| |
57. | <NormativeStatusCtn> ::= <generalQualifiers> NormativeStatus |
58. | <NoteCtn> ::= <generalQualifiers> Note {<ContainerComplement>} |
59. | <PartOfSpeechCtn> ::= <generalQualifiers> PartOfSpeech |
60. | <PersonCtn> ::= <generalQualifiers> Person { Example| |
61. | <PronunciationCtn ::= <generalQualifiers> Pronunciation |
62. | <RegisterCtn ::= <generalQualifiers> Register |
63. | <RangeOfApplicationCtn> ::= <generalQualifiers> |
64. | <SeeCtn> ::= <generalQualifiers> See { Corecomments } |
65. | <SenselndicatorCtn> ::= <generalQualifiers> Senselndicator |
66. | <SenseQualifierCtn> ::= <generalQualifiers> SenseQualifier |
67. | <SourceCtn> ::= <generalQualifiers> Source |
68. | <SubcategorisationCtn> ::= <generalQualifiers> |
69. | <SubjectFieldCtn> ::= <generalQualifiers> SubjectField |
70. | <SyllabificationCtn> ::= <generalQualifiers> Syllabification |
71. | <SymbolCtn> ::= <generalQualifiers> Symbol { Source } |
72. | <TenseCtn> ::= <generalQualifiers> Tense { Example| |
73. | <TypicalComplementCtn> ::= <generalQualifiers> |
74. | <UsageNoteCtn> ::= <generalQualifiers> UsageNote |
4.2.5 Формальная грамматика для лексических единиц
75. | <AbbreviatedForm> ::= <generalQualifiers> |
76. | <Analogy> ::= <generalQualifiers> <CoreComponentContent> |
77. | <Antonym> ::= <generalQualifiers> [AntonymType] |
78. | <Citation> ::= <generalQualifiers> [CitationType] <CoreComponentContent> |
79. | <CompositionalPhrase> ::= <generalQualifiers> |
80. | <Derivation> ::= <generalQualifiers> [DerivationType] |
81. | <Example> ::= <generalQualifiers> [ExampleType] [correctness] |
82. | <FalseFriend> ::= <generalQualifiers> [FalseFriendType] |
83. | <FreeTopic> ::= <generalQualifiers> FreeTopicType |
84. | <FullForm> ::= <generalQualifiers> [FullFormType] |
85. | <Headword> ::= <generalQualifiers> [HeadwordType] |
86. | <lnflection> ::= <generalQualifiers> [InflectionType] |
87. | <MultiWordUnit> ::= <generalQualifiers> (<MultiWordUnitType> |
88. | <SearchForm> ::= <generalQualifiers> [SearchFormType] |
89. | <Synonym> ::= <generalQualifiers> [SynonymType] |
90. | <Translation> ::= <generalQualifiers> (<TranslationType> | [targetLanguage] <CoreComponentContent> |
91. | <Variant> ::= <generalQualifiers> [VariantType] |
4.2.6 Формальная грамматика для комментариев
92. | <Attestation> ::= <generalQualifiers> <CoreComponentContent> |
93. | <Case> ::= <generalQualifiers> <CaseValue> |
94. | <CompanySpecificUsage> ::= <generalQualifiers> |
95. | <Definition> ::= <generalQualifiers> [DefinitionType] |
96. | <Display> ::= <generalQualifiers> <CoreComponentContent> |
97. | <Etymology> ::= <generalQualifiers> <CoreComponentContent> |
98. | <Formation> ::= <generalQualifiers> <CoreComponentContent> |
99. | <Formula> ::= <generalQualifiers> <CoreComponentContent> |
100. | <FreeComment> ::= <generalQualifiers> FreeCommentType |
101. | <Frequency> ::= <generalQualifiers> <FrequencyValue> |
102. | <GeographicalUsage> ::= <generalQualifiers> |
103. | <GuidePhrase> ::= <generalQualifiers> <CoreComponentContent> |
104. | <GrammaticalGender> ::= <generalQualifiers> |
105. | <GrammaticalNumber> ::= <generalQualifiers> |
106. | <GrammaticalPattern> ::= <generalQualifiers> |
107. | <lnsert> ::= <generalQualifiers> [InsertType] |
108. | <Mood> ::= <generalQualifiers> <MoodValue> |
109. | <NormativeStatus> ::= <generalQualifiers> |
110. | <Note> ::= <generalQualifiers> <CoreComponentContent> |
111. | <PartOfSpeech> ::= <generalQualifiers> <PartOfSpeechValue> |
112. | <Person> ::= <generalQualifiers> <PersonValue> |
113. | <Pronunciation> ::= <generalQualifiers> [scheme] |
114. | <ProprietaryRestriction> ::= <generalQualifiers> |
115. | <Register> ::= <generalQualifiers> <RegisterValue> |
116. | <RangeOfApplication> ::= <generalQualifiers> |
117. | <See> ::= <generalQualifiers> <CoreComponentContent> |
118. | <SeeAlso> ::= <generalQualifiers> <CoreComponentContent> |
119. | <Senselndicator> ::= <generalQualifiers> |
120. | <SenseQualifier> ::= <generalQualifiers> |
121. | <Source> ::= <generalQualifiers> <CoreComponentContent> |
122. | <Subcategorisation> ::= <generalQualifiers> |
123. | <SubjectField> ::= <generalQualifiers> [scheme] |
124. | <Syllabification> ::= <generalQualifiers> |
125. | <Symbol> ::= <generalQualifiers> <CoreComponentContent> |
126. | <Tense> ::= <generalQualifiers> <TenseValue> |
127. | <TypicalComplement> ::= |
128. | <UsageNote> ::= <generalQualifiers> [UsageNoteType] |
129. | <Voice> ::= <generalQualifiers> <VoiceValue> |
4.3 Модели контента
4.3.1 Элементы контента
Контент (информационное содержимое) элемента данных является смесью следующих компонентов:
- открытого текста;
- "вложенных элементов" (см. п.4.3.2), которые либо представляют собой элементы данных, появляющиеся внутри контента (например, <Example>), либо специфичны для элементов контента (например, скрытый текст <HiddenEntry>);
- "базовых элементов" (см. п.4.3.3) общего применения, таких как <Unit> (единица) или <Quantity> (количество);
- элементов представлений в языке XHTML: b, br, div, h1, h2, h3, h4, h5, h6, i, img, ol, p, span, sub, sup, table, ul;
- указателей (см. п. 4.3.4).
4.3.2 Вложенные элементы
Таблица 18 - Список вложенных элементов
Имя | Групповой идентификатор | Пояснение | См. |
дополнение | Addendum | Текст, добавляемый к обороту речи (цитата, поговорка и т.п.), чтобы сделать его более ясным. | |
альтернатива | Alternative | Компонент заглавного слова, указывающий на возможность выбора между двумя или более компонентами. Могут существовать несколько вариантов выбора (<Choice>). | С |
коллокатор | Collocator | Добавочный компонент к заглавному слову, служащий для построения композиционной фразы (CompositionalPhrase). | С |
сопряженный термин | EntailedTerm | Лексическая единица, которая определяется в другой словарной статье. | С |
иноязычный текст | ForeignText | Слово, фраза или расширенный текст, принадлежащие к иному языку, чем язык окружающего текста. | С |
фрагмент | Fragment | Короткий сегмент лексической единицы, вложенный в метадискурс. | С |
свободный контент | FreeContent | Произвольный элемент, используемый внутри контента элемента данных. | |
глосса | Gloss | Любой комментарий. | С |
скрытый вход | HiddenEntry | Контекстуальный (не лемматический) подадрес внутри дескриптивного элемента. | С |
номер омографа | HomographNumber | Номер, ассоциируемый с единицей описания омографа. | С |
опциональный | Optional | Необязательная часть лексической единицы. | С |
префикс | Prefix | Приставка, добавляемая к слову спереди для образования производного слова или инфлективной формы. | С |
символ повторения | RepeatSymbol | Элемент-заменитель, используемый вместо последней лексической единицы в статье. | С |
смысловой номер | SenseNumber | Номер, присваиваемый лексической единице в описании смыслового значения. | С |
основа | Stem | Основная часть слова, к которой добавляются аффиксы. | |
суффикс | Suffix | Аффикс, добавляемый к концу основы слова и служащий для образования нового слова или выполнения роли изменяемого окончания. | С |
URI | URI | Универсальный идентификатор ресурса (Uniform Resource Identifier), именуемый также URL (Uniform Resource Locator), который представляет собой короткую строку, указывающую местонахождение ресурса в сети Интернет: такими ресурсами могут быть документы, изображения, загружаемые файлы, сетевые услуги, ящики электронной почты и др. | |
url | Url | Физический адрес объекта, доступ к которому организуется на основе использования уже развернутых в сети протоколов [RFC 2396] |
- 4.3.3 Базовые элементы
Базовые элементы соответствуют обычным битам количественной информации или широко используемых лексических единиц, которые могут появляться в любых местах текста и во вложенных элементах.
Таблица 19 - Список базовых элементов
Имя | Групповой идентификатор | Пояснение | См. приложение пример |
дефис | Hyphen | Элемент, используемый для разделения частей некоторых сложных слов, для соединения слов в синтаксических конструкциях и для связи слогов слов написанного или напечатанного текста при использовании переносов [CED]. | С |
количество | Quantity | Атрибут какого-либо явления, предмета или вещества, которые могут иметь количественные различия и представляться количественной величиной. | С |
диапазон | Range | Связанный набор предельных величин, между которыми лежат измеряемые количественные значения; задается путем установления нижней и верхней границ диапазона изменения. [ISO 12620:1999, А.5.7] | С |
ударение | Stress | Элемент, используемый для указания слога, который выделяется более громким произношением по сравнению с окружающими его слогами [CED]. | С |
единица измерения | Unit | Определенная и принятая по всеобщему соглашению конкретная количественная величина, с которой сопоставляются другие количественные величины того же типа в целях выражения их количественных значений относительно установленной эталонной величины. [VIM:1993, определение 1.7] | |
кодовая группа | Word | Автономная графическая часть лексической единицы. |
Таблица 20 - Список вложенных и базовых контейнеров
Имя | Групповой идентификатор | Пояснение | См. приложение пример |
скрытый контейнер статьи | HiddenEntryCtn | Контейнер для уточнения <HiddenEntry> | С |
контейнер кодовой группы | WordCtn | Контейнер для уточнения кодовой группы <Word> |
4.3.4 Указатель
Указатель - это элемент, используемый для установления связи между двумя позициями внутри словаря. Для указателя необходимы как минимум две части (или два бита) информации: 1) подсказка пользователю и 2) адрес указываемой целевой позиции.
Таблица 21 - Указатель
Имя | Групповой идентификатор | Пояснение | См. приложение пример |
указатель | Ptr | Поле или запись, используемые в системе сбора данных для переадресации пользователя к другой связанной позиции, например, к другой записи. | С |
Таблица 22 - Пример перекрестной ссылки (пример 3 из приложения С)

Первый вход ("LEX ex.9-1") указывает на другой вход ("LEX ех.9-4") с помощью указателя <Ptr>.
4.3.5 Формальная грамматика для вложенных контейнеров
130. | <HiddenEntryCtn> ::= <generalQualifiers> {<CoreComments>| |
131. | <WordCtn> ::= <generalQualifiers> {<CoreComments>| |
4.3.6 Формальная грамматика контента категории данных
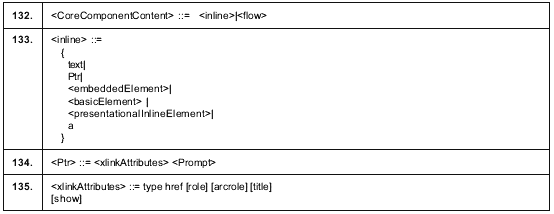

4.4 Общие спецификаторы
Все элементы структуры, элементы данных и перемещаемые элементы имеют общие спецификаторы XHTML (класс, стиль, xml:lang), спецификатор размера документа (documentSize) для указания формата словаря, к которому относится данный элемент (компактный, средний, большой и др.), а также признак отображения, используемый для контроля визуального представления элементов в соответствии с настройками элемента Display.
5 Способы представления
5.1 Средства макетирования
5.1.1 Общие положения
В зависимости от среды представления словаря, используются один или несколько способов его макетирования. Разметка текста (см. таблицу 23) и соответствующие типографские правила могут использоваться применительно ко всем средам и носителям для различения и выделения различных элементов статьи (см. п.5.1.2). Табличная форма особенно рекомендуется для словарей, охватывающих больше двух языков (см. п.5.1.2.3). В электронной среде в качестве специфической формы представления могут использоваться шаблоны банка данных.
5.1.2 Средства разметки словарей
5.1.2.1 Текстовое форматирование
Таблица 23 - Форматирование текста
Характеристики форматирования | Примеры вариантов форматирования |
Семейство шрифтов | различие оформления текста за счет использования разного начертания шрифтов (например, с засечками и без засечек) |
Размер кегля | разная величина шрифта для разных элементов статьи |
Гарнитура шрифта | светлый прямой, светлый курсив, полужирный прямой, полужирный курсив |
Цвет | цветовое выделение элементов статьи (например, показ гнездовых терминов другим цветом) |
Стиль | капитель, заглавные буквы, подстрочный, надстрочный |
5.1.2.2 Типографские знаки
Следует иметь в виду, что типографские знаки, перечисленные в таблице 24, характеризуют лишь функцию знака, но не описывают его визуальное представление.
Различным типам представляемых на экране изображений соответствуют разные модификации одних и тех же типографских знаков. Так, например, в латинском тексте глиф ";" представляет типографский знак "точка с запятой", однако в случае греческого текста это будет "вопросительный знак". Это значит, что при использовании латинского шрифта типографский знак "точка с запятой" должен печататься как ";", а в случае использования греческого шрифта - как точка вверху "·".
Таблица 24 - Типографские знаки
Типографский знак | Функциональное назначение |
Точка | разделение элементов статьи |
Точка с запятой | разделение элементов статьи |
Двоеточие | соединение элементов статьи |
Наклонная черта | соединение элементов статьи, разграничение возможных вариантов |
Нумерация | выделение разделов и подразделов, арабские цифры, римские цифры, греческие буквы, алфавитная нумерация и т.п. (см. приложение А) |
Круглые и квадратные скобки | выделение элементов статей (круглыми, квадратными, угловыми и фигурными скобками) |
Символьные метки | разметка элементов статьи |
Показатель степени (надстрочные цифры) | разграничение идентичных элементов статьи |
5.1.2.3 Табличное представление
Различные элементы словарной статьи могут структурироваться путем представления их в табличной форме (например, в многоязычных словарях для каждого языка может быть отведена отдельная колонка). Заголовки колонок должны быть видны в каждом отображении (например, в книжном формате эти заголовки должны присутствовать на каждой странице).
Если различные элементы статьи помещаются в ячейки таблицы, они должны разграничиваться какими-либо иными способами, рассмотренными в 5.1.2.1 и 5.1.2.2.
5.2 Механизмы уплотнения
5.2.1 Общепринятые сокращения
Используемые общепринятые сокращения должны четко идентифицироваться и объясняться (например, в руководствах пользователя). Аббревиатуры должны быть прозрачными и легко понимаемыми, если возможно не требующими обращения к инструкциям пользователя.
Если какие-то аббревиатуры определены в каком-либо стандарте, то надлежит использовать именно такие стандартизованные определения,
- когда они достаточно точны для применения в рамках предметной области, охватываемой словарем, и
- когда они соответствуют уровню образования и начитанности целевой аудитории пользователей словаря.
5.2.2 Повторения сокращенной формы заглавного слова
В "бумажных" словарях для экономии места повторяемые заголовки статьи могут даваться в сокращенной форме. В системах с банками данных таких сокращений заглавных слов необходимо избегать применительно к поисковым словам и ключам сортировки.
Сокращения заголовка статьи могут заменять один элемент многословного термина или часть слова. В последнем случае компонент слова должен быть четко ограничен, например, вертикальной чертой. При этом не должно быть никакой двусмысленности, особенно в связи с общеизвестными сокращениями.
5.2.3 Символы повторения (тильда или тире)
В "бумажных" словарях для экономии места могут также использоваться символы повторения: тильда (волнистое тире) [~] или обычное тире [-]. В системах с банками данных таких символов повторения необходимо избегать применительно к поисковым словам и ключам сортировки.
Сокращения заголовка статьи могут заменять один элемент многословного термина или часть слова. В последнем случае компонент слова должен быть четко ограничен, например, вертикальной чертой. При этом не должно возникать никакой двусмысленности. Использование нескольких символов повторения подряд для замены нескольких элементов недопустимо.
Специальная форма тильды в виде тильды с кружочком указывает на переключение при печатании первого символа с нижнего регистра на верхний.
5.2.4 Гнездовой принцип
В "бумажных" словарях для экономии места может использоваться гнездовая структура, при которой несколько словарных статей объединяются в один абзац. В этом случае заглавные слова не обязательно печатаются только в начале новой строки, а могут появляться и внутри абзаца.
Гнездового принципа необходимо избегать при использовании электронного представления словарных статей.
Приложение А
(справочное)
Арабская, римская и греческая системы нумерации
Таблица А.1 - Арабская, римская и греческая системы нумерации
Наименование числа (русское) | Знак арабской системы | Знак римской системы | Знак греческой системы |
Один | 1 | I | |
Два | 2 | II | |
Три | 3 | III | |
Четыре | 4 | IV | |
Пять | 5 | V | |
Шесть | 6 | VI | |
Семь | 7 | VII | |
Восемь | 8 | VIII | |
Девять | 9 | IX | |
Десять | 10 | X | |
Одиннадцать | 11 | XI | |
Двенадцать | 12 | XII | |
Тринадцать | 13 | XIII | |
Четырнадцать | 14 | XIV | |
Пятнадцать | 15 | XV | |
Шестнадцать | 16 | XVI | |
Семнадцать | 17 | XVII | |
Восемнадцать | 18 | XVIII | |
Девятнадцать | 19 | XIX | |
Двадцать | 20 | XX | |
Двадцать один | 21 | XXI | |
Двадцать два | 22 | XXII | |
Тридцать | 30 | XXX | |
Сорок | 40 | XL | |
Пятьдесят | 50 | L | |
Шестьдесят | 60 | LX | |
Семьдесят | 70 | LXX | |
Восемьдесят | 80 | LXXX | |
Девяносто | 90 | ХС |
|
Сто | 100 | С | |
Сто один | 101 | CI | |
Двести | 200 | CC | |
Триста | 300 | CCC | |
Четыреста | 400 | CD | |
Пятьсот | 500 | D | |
Шестьсот | 600 | DC | |
Семьсот | 700 | DCC | |
Восемьсот | 800 | DCCC | |
Девятьсот | 900 | CM |
|
Тысяча | 1000 | M | |
| |||
Приложение В
(справочное)
Таблицы функций лексикографических символов
Двухбуквенные имена DE, EL, FR, JP, LT и PL, фигурирующие в данном приложении, обозначают кодовые названия стран (в соответствии со стандартом ISO 3166-1:1997 Коды для представления названий стран и единиц их административного деления. Часть 1. Коды стран), в которых используются лексикографические символы (DE = Германия; EL = Греция; FR = Франция; JP = Япония; LT = Литва; PL = Польша).
Примечания
1 Этот список - не исчерпывающий. Приведенные в данном приложении символы взяты из определенных одно- и двуязычных словарей, представленных для каждой из упомянутых стран.
2 Комментарий относительно символов, используемых в Японии:
- Представленные в этом приложении символы были взяты из четырех современных одноязычных японских словарей, содержащих более 200000 статей. Другие типы словарей, включая двуязычные, не рассматривались.
- Японские тексты в соответствии с традицией написаны вертикально сверху вниз, а строки на странице читаются справа налево как в исследовавшихся словарях. Поэтому все японские символы, фигурирующие в данном приложении, представлены в вертикальном написании.
В.1 Прагматическая и грамматическая информация о словарных статьях и их компонентах
Таблица В.1 - Прагматические и грамматические функции
Функциональное назначение символа по отношению к отмеченному слову | Символ | Название символа | Местоположение | Специфика применения |
Слово устарело или выходит из употребления | крестик, кинжал | впереди; надстрочный | ||
Нерекомендуемое слово (варваризм, гибрид, калька) | знак умножения | впереди | Литва | |
Встречается только в классической литературе | ромбик | впереди | Германия | |
Неологизм | * | звездочка | впереди | |
Является торговой маркой | зарегистрированный торговый знак | постпозитивный; надстрочный | Германия | |
торговая марка | постпозитивный; надстрочный | |||
Переводческий неологизм | ! | восклицательный знак | впереди | |
Гармонизированный международный научно-технический термин | ° | знак градуса | впереди | Польша |
треугольник | впереди | |||
Примеры взяты из фольклора или просторечных выражений | ^ | крышка | впереди | Литва |
Вульгаризм | ! | восклицательный знак | впереди | Греция |
Защищено законодательно (или иным способом) | § | знак параграфа | впереди | |
Идиоматическое выражение | * | звездочка | впереди | Германия |
косоугольник | впереди | Литва, Польша | ||
ромбик | впереди | Литва | ||
Фразовый глагол | ромбик | впереди | Германия | |
прямоугольник | впереди | Литва | ||
квадратик | впереди | Литва | ||
Базовая лексика | буллит, маркер абзаца | впереди | Германия | |
Производное слово от заглавного слова | косоугольник | впереди | Польша | |
Пословица | квадратик | впереди | Польша | |
Несовершенная форма глагола совершенного вида или совершенная форма глагола несовершенного вида | - - | впереди | Польша | |
Определенный сложный термин или определенное сложное имя | треугольник | впереди | Литва | |
^ | крышка | впереди | Литва | |
Приблизительный эквивалент | знак приближенного равенства | впереди | Литва | |
Лексический вход словарной статьи представлен географическим названием | черный квадратик в белом ромбе | постпозитивный | Япония | |
Лексический вход словарной статьи представлен именем собственным | черный кружок в белом круге | постпозитивный | Япония | |
Лексический вход словарной статьи представлен античным словом |
| постпозитивный | Япония | |
Лексический вход словарной статьи представлен поэтическим эпитетом (pillow-word) | постпозитивный | Япония | ||
Отмеченный символ кандзи отсутствует в списке Йойо-кандзи (это список символов кандзи для общего применения) | черный перевернутый треугольник | справа вверху | Япония | |
Отмеченный символ кандзи присутствует в списке Йойо-кандзи, но данного начертания в списке нет | белый перевернутый треугольник | справа вверху | Япония |
В.2 Этимологическая информация о словарной статье и ее компонентах
Таблица В.2 - Этимологическая информация о словарной статье или о функции компонента
Функциональное назначение символа по отношению к отмеченному слову | Символ | Название символа | Местоположение | Специфика применения |
В печатной литературе не встречается; воспринимается как гипотетический | * | звездочка | впереди | Греция, Литва, Польша |
Это индоевропейский этимон; воспринимается как гипотетический | * | звездочка | впереди | Греция, Польша |
Форма/слово перед символом происходит от формы/слова после символа | знак "меньше" | Германия, Греция, Литва | ||
Форма/слово после символа происходит от формы/слова перед символом | знак "больше" | Греция, Литва |
В.3 Экономия пространства
Таблица В.3 - Функции экономии пространства
Функциональное назначение символа по отношению к отмеченному слову | Символ | Название символа | Местоположение | Специфика применения |
Заменяет элемент лексической единицы во всей словарной статье или в ее части | ~ | тильда | впереди или в середине термина либо в конце части термина | Германия, Литва, Польша |
Заменяет заглавное слово по всей статье, когда стоит отдельно | ~ | тильда | Германия, Польша | |
Заменяет предлог "с" | + | знак плюс | после слова | Франция, Литва |
Отсекает некоторые слова либо части слова | … | троеточие | Германия | |
Заменяет ключевое слово главного заголовка в подзаголовке | | | вертикальная черта | Япония | |
Заменяет ключевое слово в примере | | | вертикальная черта | Япония | |
Заменяет часть кана лексического входа в зоне кандзи-кана (в случае сложных слов иноязычного и японо-китайского происхождения) | | | вертикальная черта | Япония | |
Заменяет одни и те же символы кана главного слова в зоне описания предыстории кана | : | две точки (по вертикали) | Япония | |
| | вертикальная черта | Япония | ||
Заменяет иноязычное слово, приведенное в этимологической зоне, во всем остальном тексте статьи | волна (вертикальная) | Япония | ||
Отсекает некоторые слова в примере | троеточие (вертикальное) | Япония |
В.4 Семантическая спецификация
Таблица В.4 - Описание семантики функций: индицирующие символы
Функциональное назначение символа по отношению к отмеченному слову | Символ | Название символа | Местоположение | Специфика применения |
Обозначение равнозначности понятий | = | знак равенства | впереди | Польша |
Эквивалент или синоним заглавного слова представляет похожее понятие | приблизительно равно | впереди | Польша | |
Понятие, представляемое этим обозначением, немного шире, чем понятие, описанное в статье | знак "больше" | впереди | ||
Понятие, представляемое этим обозначением, немного уже, чем понятие, описанное в статье | знак "меньше" | впереди | ||
Понятие, представляемое этим обозначением, перекрывает понятие, описанное в статье | знак умножения | впереди | ||
Понятие, представляемое этим обозначением, является омографом для заглавного слова и несет в себе другой смысл | знак неравенства | впереди | ||
Это обозначение не относится к понятию, описанному в статье | знак неравенства | впереди | ||
Одно отмеченное значение в корне отличается от всех остальных значений | буллит, маркер | впереди | Греция | |
Синоним имеет более широкий или более узкий смысл | стрелка вверх и стрелка вниз | после | Греция | |
Это метафора | правый черный треугольник | впереди | Польша | |
Данное слово является синонимом лексического входа статьи и может использоваться как синоним во всех случаях | вертикальный знак равенства | впереди | Япония | |
Данное слово является антонимом основной статьи | вертикальная двухголовая стрелка | впереди | Япония | |
| впереди | Япония | ||
Данное слово является квазисинонимом лексического входа статьи |
| впереди | Япония | |
Сравнение основного слова с отмеченным словом или фразой поможет глубже понять смысл основного слова |
| впереди | Япония | |
Понимание отмеченного слова или выражения поможет глубже понять смысл основного слова |
| впереди | Япония | |
Данное слово или выражение происходит от основного слова |
| впереди | Япония | |
черный перевернутый треугольник | впереди | Япония |
В.5 Перекрестные ссылки между статьями
Таблица В.5 - Функции перекрестных ссылок
Функция | Символ | Название символа | Местоположение | Специфика применения |
Указательная перекрестная ссылка | вертикальная стрелка вверх | впереди | Германия, Литва | |
горизонтальная стрелка вправо | впереди | Греция, Франция, Литва | ||
наклонная стрелка | впереди | Литва | ||
= | знак равенства | впереди | Литва | |
Указание на слово, следующее сразу за данным символом | * | звездочка | впереди | Франция |
Обращение к следующей статье | вертикальная стрелка вниз | впереди | Япония | |
Отсылка к пояснению, содержащемуся в следующей статье | двухлинейная стрелка вниз | впереди | Япония | |
белая стрелка вниз | впереди | Япония |
В.6 Соединение компонентов статьи
Таблица В.6 - Функции соединения компонентов
Функция | Символ | Название символа | Местоположение | Специфика применения |
Соединение заглавного слова с его вариантами в заголовке статьи | & | амперсанд | Греция | |
Соединение примера с его источником в части словарной статьи | / | слеш, косая черта | Япония | |
Указание происхождения слова или его родственных связей | горизонтальная стрелка | Литва | ||
Указание нерекомендуемых слов, словоформ или словосочетаний в сопоставлении с рекомендациями | = | знак равенства | постпозиционный | Литва |
В.7 Идентификация разделения, словообразования, постановки ударения и т.п.
Таблица В.7 - Функции разделения, словообразования, постановки ударения и т.п.
Функция | Символ | Название символа | Местоположение | Специфика применения |
Показ возможных способов разделения слова | | | черта | Германия | |
Указание краткого ударного гласного звука | (.) | точка под гласной буквой | Германия | |
Указание долгого ударного гласного звука | (_) | подчеркнутая гласная буква | Германия | |
Указание на укороченную фонетическую транскрипцию | - | тире | Германия, Франция | |
Указание на неправильную форму множественного числа | - | тире | Франция | |
Представление последовательности отдельных компонентов сложного слова | + | знак плюс | Греция, Литва, Польша | |
Указание способа построения синтаксической конструкции | + | знак плюс | в круглых скобках, которые содержат грамматическую информацию | Франция |
Отделение частей слова, таких как основа, от окончаний, префиксов, аффиксов и др. | - | тире | Греция, Литва | |
Отделение основы слова и корня от падежных окончаний в этимологической информации | - | тире | Франция | |
Указание во французском языке на недопустимость связывания конечного согласного с начальным гласным звуком следующего слова | * | звездочка | впереди буквы "h" | Франция |
Указание на смягченный согласный звук | ' | вертикальная черточка | постпозиционный | Литва |
Указание ударного гласного или дифтонга (когда ударение в слове не ясно) | точка после гласного или дифтонга | постпозиционный | Литва | |
Выделение общей части родственных слов | II | вертикальные параллельки | Литва | |
Выделение необязательной буквы или необязательного компонента термина или слова | ( ) | круглые скобки | Литва | |
[] | квадратные скобки | Германия | ||
Показ способа разделения слова на образующие его компоненты (применительно к лексическому входу словарной статьи) | ' | вертикальная черточка | между компонентами | Япония |
пробел | между компонентами | Япония | ||
Показ разделения основы и окончания слова (применительно к лексическому входу словарной статьи) | средняя точка катакана | между основой слова и его окончанием | Япония | |
Указание последнего слога "си" в основе слова классического имени прилагательного с окончанием на сику (применительно к лексическому входу словарной статьи) | белый буллит | перед последним "си" | Япония | |
Указание начала сложного инфлективного слова в составном слове или в грамматическом обороте (применительно к лексическому входу словарной статьи) | белый буллит | перед спрягаемым словом | Япония | |
Показ структуры заимствованного слова (в зоне описания) | ' | вертикальная черточка | между компонентами | Япония |
Разделитель иностранных имен и фамилий (в зоне описания) | II | вертикальный знак равенства | Япония | |
Указание на то, что предшествующий гласный звук - долгий | вертикальная метка продолжительного звука в азбуке катакана-хирагана | Япония | ||
Указание на то, что отмеченная вокабула может произноситься либо вместо этого может удлиняться предшествующий ей гласный звук | белый треугольник | внизу справа | Япония | |
Указание на то, что отмеченный иероглиф | X | строчная х | внизу справа | Япония |
Указание на назальный звук в сочетаниях с | отметка полугласного звука катакана-хирагана | вверху справа | Япония | |
При наличии цифры внутри прямоугольника - указание на мору, после которой тон звука меняется с высокого на низкий | скругленный белый прямоугольник | Япония | ||
В сочетании с соответствующим слогом - указание места тонального ударения (слога, после которого тон меняется с высокого на низкий) | белый квадратик | Япония | ||
В сочетании с соответствующим слогом - указание высокотонального слога | белый кружок | Япония | ||
Указание на отсутствие тонального ударения | ноль в скругленном прямоугольнике | Япония | ||
ноль в кружочке | Япония | |||
Указание на высокотональную мору | черный кружок | Япония | ||
Указание на низкотональную мору | белый кружок | Япония | ||
Указание на мору, в которой тон переходит от высокого к низкому | кружок с черным верхним полукругом | Япония | ||
Указание на мору, в которой тон переходит от низкого к высокому | кружок с черным нижним полукругом | Япония | ||
Выделение в написанном слове знаков кана, которые могут быть опущены в кана-окончании ("окуригана") | вертикальные круглые скобки | Япония | ||
горизонтальные круглые скобки | Япония | |||
Выделение в написанном слове знаков кана, которые могут быть добавлены в кана-окончание ("окуригана") | вертикальные круглые скобки | Япония | ||
Указание возможной формы лексического входа словарной статьи |
| впереди | Япония |
В.8 Включение металингвистической информации
Таблица В.8 - Включаемые металингвистические функции
Функция | Символ | Название символа | Местоположение | Специфика применения |
Включение фонологической транскрипции | // | два слеша | Греция, Польша | |
[ ] | квадратные скобки | Германия, Франция, Литва, Польша | ||
Включение переводных значений иностранных слов | одиночные кавычки | Греция | ||
Включение этимологической информации | [ ] | квадратные скобки | Германия, Литва | |
угловые скобки | Польша | |||
( ) | круглые скобки | Франция, Литва | ||
Указание ссылочных номеров таблиц спряжения глаголов | [ ] | квадратные скобки | Франция | |
Указание меток (стилевых, словоупотребления, региональных, предметных) | ( ) | круглые скобки | Германия, Литва | |
Включение толкований | ( ) | круглые скобки | Германия, Литва | |
Включение примечаний | ( ) | круглые скобки | Франция | |
Включение грамматической информации | угловые скобки | Германия | ||
( ) | круглые скобки | Франция | ||
Включение форм множественного числа | ( ) | круглые скобки | Франция | |
Включение определенных типов перекрестных ссылок | ( ) | круглые скобки | Франция | |
Включение определенных типов примеров | ( ) | круглые скобки | Франция | |
Включение определенной лингвистической информации (ударение, номер парадигмы и др.) | ( ) | круглые скобки | Литва | |
Включение имени автора или названия источника, из которого взят пример | ( ) | круглые скобки | Германия | |
Включение альтернативных слов или словосочетаний в речевые обороты | [ ] | квадратные скобки | Литва | |
( ) | круглые скобки | Литва | ||
Включение дополнительной информации в примеры | [ ] | квадратные скобки | Литва | |
Включение дополнительной информации, относящейся к заглавному слову | ( ) | круглые скобки | Франция | |
Включение восстановленных сегментов (окончаний, слогов) непонятных сокращений | [ ] | квадратные скобки | Литва | |
Включение смысловых значений | литовские кавычки | Литва | ||
Включение меток, касающихся местного произношения и его корней | вертикальные угловые скобки | Япония | ||
Включение общих типов письма с использованием алфавитов канзи и кана | вертикальные линзообразные скобки | Япония | ||
вертикальные светлые квадратные скобки | Япония | |||
Включение информации о части речи и грамматических формах | двойные вертикальные квадратные скобки ("черепаший панцирь") | Япония | ||
вертикальные круглые скобки | Япония | |||
Включение этимона (исходной формы данной единицы языка) в оригинал или его романизированную форму с указанием языка или страны | вертикальные круглые скобки | Япония | ||
вертикальные квадратные скобки | Япония | |||
вертикальные черные линзообразные скобки | Япония | |||
вертикальные белые линзообразные скобки | Япония | |||
вертикальные скобки "черепаший панцирь" | Япония | |||
Включение информации о предметной области термина | вертикальные светлые квадратные скобки | Япония | ||
вертикальные скобки "черепаший панцирь" | Япония | |||
Включение названия времени года | вертикальные двойные угловые скобки | Япония | ||
Включение примеров | вертикальные угловые скобки | Япония | ||
Включение имени автора или названия работы, из которой взят цитируемый пример | вертикальные Г-образные скобки | Япония | ||
Включение иероглифов канзи в зону объяснения словарных значений (когда для толкования разных значений слова используются несколько систем канзи) | вертикальные двойные угловые скобки | Япония | ||
Включение слов или фраз, которые должны быть особо выделены в определениях и объяснениях | вертикальные Г-образные скобки | Япония | ||
Включение названия авторской работы в определения и объяснения | вертикальные Г-образные скобки | Япония | ||
Включение парафраза, синонима или толкования речевого оборота в определения, объяснения и примеры | вертикальные круглые скобки | Япония | ||
Включение различных примечаний | вертикальные круглые скобки | Япония | ||
| вертикальные двойные круглые скобки | Япония | ||
вертикальные скобки "черепаший панцирь" | Япония | |||
Включение информации об авторстве или первоисточнике оборота речи, определения, объяснения, документа, толкования и т.п. | вертикальные круглые скобки | Япония | ||
вертикальные квадратные скобки | Япония | |||
вертикальные скобки "черепаший панцирь" | Япония | |||
вертикальные угловые скобки | Япония | |||
Включение года или периода времени | вертикальные круглые скобки | Япония |
В.9 Структурирование словарных статей
Таблица В.9 - Структурирование функций словарных статей
Функция | Символ | Название символа | Местоположение | Специфика применения |
Разделение этимологической информации для разных слов | точка вверху (греческий аналог точки с запятой) | Греция | ||
Разделение компонентов словарной статьи | ; | точка с запятой | Германия, Франция | |
Разделение альтернативных форм, слов, словосочетаний и т.п. | / | слеш, косая черта | Германия, Греция, Литва | |
Разделение двух определений, когда второе определение имеет иной смысл; в этом случае ему предшествует метка (предметной области, регистра и др.) | - | дефис | Франция | |
Разделение дополнительного значения | II | вертикальные параллельки | Литва | |
Отделение слова с далеким смысловым значением от других слов, присутствующих в той же словарной статье | II | вертикальные параллельки | Литва | |
Разделение разных смысловых значений | I | тактовая черта | Литва | |
II | вертикальные параллельки | Литва | ||
Разделение в переводе разных оттенков значения заглавного слова | ; | точка с запятой | Литва | |
Разделение разных речевых оборотов | - | дефис | перед вторым оборотом в наборе примеров разных фраз | Франция |
Отметка начала семантической части словарной статьи | : | двоеточие | Германия, Греция | |
Отметка начала определения речевого оборота | : | двоеточие | Франция | |
Введение определенного типа примечания, относящегося к словарной статье в целом | - | дефис | Франция | |
Разделение двух коротких энциклопедических текстов | - | дефис | Франция | |
Обозначение, указывающее на то, что далее следует подстатья со своим подзаголовком или без него | черный ромбик | Франция | ||
Обозначение вложенной леммы | - | дефис | Греция | |
Обозначение скрытой статьи | квадратик | Греция | ||
Обозначение, указывающее (несколькими словами) на то, что далее следует иллюстрация | квадратик | Франция | ||
Обозначение, указывающее на то, что далее следует группа элементов, не упорядоченных по алфавиту | ромбик | Германия | ||
Обозначение, указывающее на то, что далее следует множество грамматических оборотов | ромбик | Франция | ||
Обозначение, указывающее на то, что далее следует информация энциклопедического характера | черный квадратик | Франция | ||
Обозначение, указывающее на то, что далее следует примечание | черный треугольник, обращенный вправо | Франция | ||
Отделение рефлексивного слова | | | тактовая черта | впереди | Литва |
II | вертикальные параллельки | впереди | Литва | |
Указание на то, что далее следует редко употребляемое дополнительное значение | | | тактовая черта | Литва | |
Указание на конкретный пример словоупотребления | | | тактовая черта | Литва | |
Отметка начала описания литературной формы заглавного слова |
| Япония | ||
Отметка начала зоны примеров |
| Япония | ||
полноширинная звездочка | Япония | |||
Отметка начала зоны примечаний разных типов |
| Япония | ||
| Япония | |||
перевернутый белый треугольник | Япония | |||
белый ромбик | Япония | |||
Отметка начала зоны примечания, касающегося времени года |
| Япония | ||
Отметка начала зоны описания суффиксов и единиц измерения для исчисляемых существительных |
| Япония | ||
Отметка начала зоны информации о произношении заглавного слова словарной статьи |
| Япония | ||
Отметка начала корпуса словаря (в классических словарных формах с поиском лексического входа) |
| Япония | ||
Отметка начала зоны описания альтернативных представлений (в сравнении с классическими словарями) |
| Япония | ||
Отметка начала зоны описания альтернативных представлений (в сравнении с классическими словарями) |
| Япония | ||
В сочетании с последовательными номерами слогов - разделение и структурирование альтернативных определений и смысловых значений лексической единицы | скругленный белый квадратик | Япония | ||
скругленный белый прямоугольник | Япония | |||
скругленный черный квадратик | Япония | |||
белый кружок | Япония | |||
черная окружность | Япония | |||
Разделение альтернативных форм | средняя точка катаканы | Япония | ||
Разделение диалектных значений одного и того же слова | белый ромбик | Япония |

Приложение С
(справочное)
Примеры кодовых представлений на языке XML
Реальные словарные статьи, использованные в настоящем стандарте в качестве примеров, служат только для иллюстрирования принципов формирования и надлежащего представления лексикографических данных с использованием языка XML. Издатели соответствующих словарей не несут никакой ответственности за содержимое этих примеров. Документ, касающийся типов определений данных [The Definition Type Document (XmLex_V00.dtd)] используется здесь как одна из возможных реализаций формальной модели, описанной в части 4, для чисто информативных целей. Более подробные сведения об этом документе и соответствующий контрольный файл доступны по адресу http://www.genetrix.org/common/XmLex/readme.html |
Шесть первых приведенных полностью словарных статей являются примерами из одноязычных, двуязычных общих и технических словарей, соответствующих требованиям XmLex_V00.dtd. Каждый пример начинается с общего представления статьи для читателя (зеленый фон), а далее следует кодовое представление XmLex (желтый фон).
С.1 Полные тексты статей
Пример 1 - Двуязычная словарная статья (англо-французская)

Кодовое представление


Пример 2 - Обычная двуязычная словарная статья


Кодовое представление


Пример 3 - Научная двуязычная словарная статья (англо-немецкая)

Кодовое представление


Пример 4 - Общая одноязычная словарная статья (на немецком языке)

Кодовое представление



Пример 5 - Общая одноязычная словарная статья

Кодовое представление


Пример 6 - Техническая одноязычная словарная статья

Кодовое представление

С.2 Фрагменты, иллюстрирующие конкретные элементы
Пример 7 - Сокращенная форма

Кодовое представление

Пример 8 - Аффиксы

Пример 9 - Возможные варианты

Кодовое представление

Пример 10 - Аналогия

Пример 11 - Фактографическая информация, засвидетельствование фактов (Attestation)

Кодовое представление

Пример 12 - Коллокатор (англо-испанский)

Кодовое представление

Пример 13 - Скрытая статья (HiddenEntry), GuidePhrase

Кодовое представление

Пример 14 - Объяснение

Перевод см. в примере 13
Кодовое представление

Пример 15 - Ложный друг переводчика

Пример 16 - Формула

Кодовое представление

Пример 17 - Произвольный комментарий (FreeComment)

Символ "h." указывает на то, что слово "![]() " является гапаксом и потому сопровождается датой его появления в языке.
" является гапаксом и потому сопровождается датой его появления в языке.
Кодовое представление
![]()
Термин "гапакс" (hарах), обозначающий индивидуальное словообразование, однократное употребление, не является стандартизованным комментарием, поэтому тип, характеризующий его происхождение, называется произвольным комментарием <FreeComment>.
Пример 18 - Произвольная тема, скрытая статья

Пример 19 - Частота словоупотребления

Кодовое представление

Пример 20 - Полная форма
![]()
Кодовое представление

Пример 21 - География применения
![]()
Кодовое представление

Пример 22 - Инфлексия

Перевод см. в примере 13
Кодовое представление

Пример 23 - Формула или символ в тексте (InlineFormula)
![]()
Кодовое представление


Пример 24 - Лингвистическое примечание, случаи словоупотребления

Кодовое представление

Пример 25 - Наклонение

Кодовое представление

Пример 26 - Стандартизованный термин (англо-немецкий контекст)
![]()
Кодовое представление

Пример 27 - Примечание

Кодовое представление


Пример 28 - Личные данные

Пример 29 - Диапазон значений (англо-немецкий контекст)
![]()
Кодовое представление выделенной части
![]()
Пример 30 - Номер смыслового значения (SenseNumber), номер омографа (HomographNumber)

Кодовое представление выделенной части

Пример 31 - Грамматическое время

Пример 32 - Вариант
![]()
Кодовое представление

Пример 33 - Количественная величина
![]()
Кодовое представление

Пример 34 - Грамматическая структура
![]()
Кодовое представление
Пример 35 - Указатель смыслового значения (Senselndicator) и типовое дополнение (TypicalComplement) (англо-французский контекст)

Кодовое представление


Пример 36 - Полная форма

Кодовое представление

Пример 37 - Фирменный термин (немецко-английский контекст)

Кодовое представление


Пример 38 - Объект собственности
![]()
Кодовое представление

Пример 39 - Международный научный термин

Кодовое представление

Приложение D
(справочное)
Определение средств сборки компонентов словаря и сжатия словарных статей
Реальные словарные статьи, использованные в настоящем Международном стандарте в качестве примеров, служат только для иллюстрирования принципов формирования и надлежащего представления лексикографических данных с использованием языка XML. Издатели соответствующих словарей не несут никакой ответственности за содержимое этих примеров. |
D.1 Привязка средств разметки к компонентам словаря
Применительно к каждому компоненту словаря необходимо обеспечить возможность четкого распознавания пользователем структурного значения компонента в той мере, в какой это требуется для различения компонентов структуры. Эта задача может решаться, например, посредством дифференциации способов разметки или дифференциации маркеров структурированного текста.
Следующий пример показывает кодовое представление гнездовой статьи двуязычного словаря (англо-французского), полученное путем преобразования структуры XSL-файла в документ HTML. Большинство маркеров текстовой структуры и все схемы представления созданы с помощью XSL-преобразования. Разные XSL-преобразования способны порождать различные представления одних и тех же лексических единиц.
Пример 1 - Словарное гнездо двуязычного словаря (англо-французского)


Пример 2 - Список стилей XSL





Применение средств разметки и маркеров структурированного текста, определенных для преобразования XSL-файлов в словарные статьи, обеспечивается каким-либо XSLT-процессором, например, процессором Xalan.
Соответствующая команда выглядит следующим образом:
java org.apache.xalan.xslt.Process-IN pocketdict-en-fr.xml -XSL XmLex.xsl
-OUT pocketdict-en-fr.html
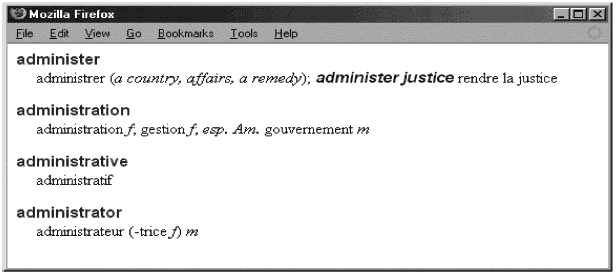
Рисунок D.1 - Конечный результат операции преобразования в документ HTML
D.1 Примеры компактных словарных статей
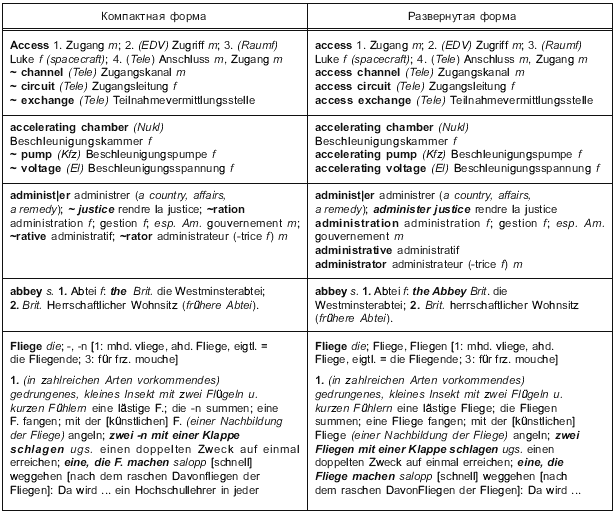
Приложение ДА
(справочное)
Сведения о соответствии ссылочных международных стандартов ссылочным национальным стандартам Российской Федерации
Сведения о соответствии ссылочных международных стандартов ссылочным национальным стандартам Российской Федерации приведены в таблице ДА.1.
Таблица ДА.1
Обозначение ссылочного международного стандарта | Степень соответствия | Обозначение и наименование соответствующего национального стандарта |
ИСО 704:2000 | IDT | ГОСТ Р ИСО 704-2010 "Терминологическая работа. Принципы и методы" |
ИСО 1087-1:2000 | - | * |
* Соответствующий национальный стандарт отсутствует. До его утверждения рекомендуется использовать перевод на русский язык данного международного стандарта. Перевод данного международного стандарта находится в Федеральном информационном фонде технических регламентов и стандартов. Примечание - В настоящей таблице использовано следующее условное обозначение степени соответствия стандарта: - IDT - идентичный стандарт. | ||
__________________________________________________________________________
УДК 001.4:006.354 ОКС 01.020, 01.080.99
Ключевые слова: терминология, словарные статьи, отраслевые словари
__________________________________________________________________________
Электронный текст документа
и сверен по:
, 2014

{kind=link}